



































Jan 01, 1970
2,145 測定値
LLM は AI アプリを変革します: その方法は次のとおりです
長すぎる; 読むには
人工知能は、1994 年にインターネットが普及して以来、最も革新的なパラダイム シフトです。企業は、ビジネスのやり方に AI を導入しようと躍起になっています。これを実現する最も重要な方法の 1 つは、生成 AI と大規模な言語モデルを介したものです。 LLM は急速にアプリケーション スタックの不可欠な部分になりつつあります。人工知能は、1994 年にインターネットが普及して以来、最も革新的なパラダイム シフトです。そして当然のことながら、多くの企業がビジネスのやり方に AI を導入しようと躍起になっています。
これを実現する最も重要な方法の 1 つは、生成 AI と大規模言語モデル (LLM) を介したものであり、ChatGPT に企業ブログの特定のトピックに関する投稿を書いてもらったり、コードの作成を手伝ってもらったりすることをはるかに超えています。
実際、LLM は急速にアプリケーション スタックの不可欠な部分になりつつあります。
必要なすべてのデータを含み、LLM の「言語を話す」ことができるデータベース上に ChatGPT のような生成 AI インターフェイス (「エージェント」) を構築することは、モバイル アプリの未来 (そして、ますます現在) です。
動的な対話のレベル、膨大な量の公開および独自データへのアクセス、および特定の状況に適応する機能により、LLM 上に構築されたアプリケーションは、最近まで利用できなかった強力で魅力的なものになっています。
そして、このテクノロジーは急速に進化し、適切なデータベースと適切な API があれば、事実上誰でもこれらのエクスペリエンスを構築できるようになりました。何が関係するのか見てみましょう。
生成 AI がアプリケーションの動作方法に革命を起こす方法
「エージェント」と「AI」を同じ文で聞くと、電子商取引サイトにアクセスしたときにどのように役立つかを尋ねるポップアップ ウィンドウとして経験したことのある単純なチャットボットを思い浮かべる人もいます。
しかし、LLM は、単純な会話のプロンプトや FAQ から得た回答で応答する以上のことを行うことができます。
ユーザーが適切なデータにアクセスできる場合、LLM に基づいて構築されたアプリケーションは、より高度な方法で私たちと対話することができ、専門家が精選した、より有用で、具体的で、豊富な、そしてしばしば驚くほど先見の明のある情報を提供します。
ここに例を示します。
あなたは裏庭にデッキを作りたいので、ホームセンターのモバイル アプリケーションを開き、買い物リストを作成するように依頼します。
アプリケーションは GPT-4 などの LLM と複数のデータ ソース (企業独自の製品カタログ、店舗在庫、顧客情報、注文履歴、およびその他の多数のデータ ソース) に接続されているため、ユーザーが何を求めているかを簡単に知ることができます。 DIY プロジェクトを完了する必要があります。
しかし、それ以上のことができます。
デッキに組み込む寸法と機能を説明すると、アプリケーションは視覚化ツールと設計支援を提供します。あなたの郵便番号を知っているので、あなたの近くのどの店舗に必要な商品の在庫があるかを知ることができます。
また、購入履歴のデータに基づいて、作業を手伝ってくれる請負業者が必要である可能性を示唆し、近くの専門家の連絡先情報を提供することもできます。
次に、デッキの汚れが乾くまでにかかる時間(住んでいる地域の季節的な気候傾向も考慮)や、実際にデッキで誕生日パーティーを開催できるようになるまでの時間などの変数に基づいて、次のことを教えてくれます。あなたは計画を立ててきました。
このアプリケーションは、プロジェクトの許可要件や建設が資産価値に及ぼす影響の詳細など、他の多くの関連分野に関する情報を提供したり支援したりすることもできます。さらに質問がありますか?
このアプリケーションは、目的地に到達するための便利なアシスタントとして、あらゆる段階で役立ちます。
アプリケーションで LLM を使用するのは難しいですよね?
これはSFではありません。現在、DataStax の最大手の顧客を含む多くの組織が、生成 AI を組み込んだ複数のプロジェクトに取り組んでいます。
しかし、これらのプロジェクトは、確立された大企業だけの領域ではありません。機械学習やデータ サイエンス、ML モデルのトレーニングに関する膨大な知識は必要ありません。
実際、LLM ベースのアプリケーションを構築するには、データベース呼び出しと API 呼び出しを行うことができる開発者以外はほとんど必要ありません。
最近まで前例のないレベルのパーソナライズされたコンテキストを提供できるアプリケーションの構築は、適切なデータベース、数行のコード、および GPT-4 のような LLM があれば誰でも実現できます。
LLM の使い方は非常に簡単です。これらはコンテキスト (多くの場合「プロンプト」と呼ばれます) を受け取り、応答を生成します。したがって、エージェントの構築は、望ましい応答を得るために LLM に適切なコンテキストを提供する方法を考えることから始まります。
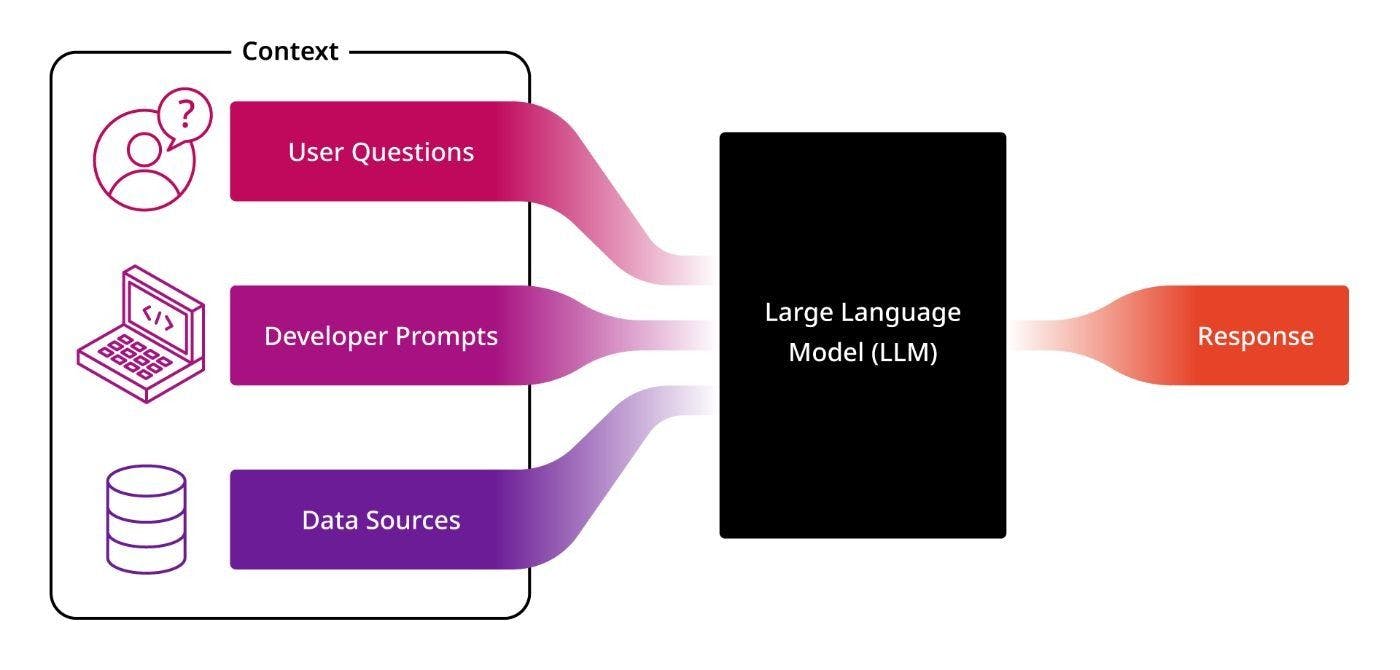
大まかに言えば、このコンテキストは 3 つの場所から取得されます。ユーザーの質問、エージェントの開発者によって作成された事前定義されたプロンプト、データベースまたはその他のソースから取得されたデータです (下の図を参照)。
ユーザーが提供するコンテキストは通常、ユーザーがアプリケーションに入力した単なる質問です。
2 番目の部分は、開発者と協力したプロダクト マネージャーによって提供され、エージェントが果たすべき役割を説明します (たとえば、「あなたは、顧客がプロジェクトを計画する際に支援しようとしている親切な営業エージェントです。以下の内容を含めてください)」回答に含まれる関連製品のリスト」)。
最後に、提供されたコンテキストの 3 番目のバケットには、LLM が応答の構築に使用するデータベースやその他のデータ ソースから取得した外部データが含まれています。
一部のエージェント アプリケーションは、より詳細な応答を作成するために、ユーザーに応答を出力する前に LLM を複数回呼び出すことがあります。
これは、ChatGPT プラグインや LangChain などのテクノロジによって促進されます (これらについては以下で詳しく説明します)。
LLM にメモリを与える…
AI エージェントには知識のソースが必要ですが、その知識は LLM によって理解できるものでなければなりません。少し戻って、LLM がどのように機能するか考えてみましょう。 ChatGPT に質問するとき、ChatGPT のメモリまたは「コンテキスト ウィンドウ」は非常に限られています。
ChatGPT と長時間会話している場合、ChatGPT は以前のクエリと対応する応答をパックしてモデルに送り返しますが、コンテキストを「忘れ」始めます。
これが、LLM 上にエージェント ベースのアプリケーションを構築したい企業にとって、エージェントをデータベースに接続することが非常に重要である理由です。ただし、データベースは、LLM が理解できる方法、つまりベクトルとして情報を保存する必要があります。
簡単に言えば、ベクトルを使用すると、文、概念、または画像を一連の次元に縮小できます。製品の説明などのコンセプトやコンテキストを取得して、それをいくつかの次元、つまりベクトルの表現に変換することができます。
これらの次元を記録すると、ベクトル検索が可能になります。つまり、キーワードではなく多次元の概念に基づいて検索できるようになります。
これは、LLM がより正確で状況に応じて適切な応答を生成するのに役立ち、同時にモデルに長期記憶の形式を提供します。本質的に、ベクトル検索は、LLM と、LLM がトレーニングされる膨大な知識ベースとの間の重要な架け橋です。
ベクトルは LLM の「言語」です。ベクトル検索は、コンテキストを提供するデータベースの必須機能です。
したがって、LLM に適切なデータを提供できるようにするための重要なコンポーネントは、エージェントのエクスペリエンスを促進するために必要な大量のデータセットを処理するスループット、スケーラビリティ、および信頼性を備えたベクトル データベースです。
… 適切なデータベースを使用する
AI/ML アプリケーション用のデータベースを選択する場合、スケーラビリティとパフォーマンスは考慮すべき 2 つの重要な要素です。エージェントは、特に Web サイトにアクセスするすべての顧客やモバイル アプリケーションを使用するすべての顧客が使用する可能性のあるエージェントを導入する場合、大量のリアルタイム データにアクセスする必要があり、高速処理が必要です。
エージェント アプリケーションに供給するデータを保存する場合、必要なときに迅速に拡張できることが成功の最も重要な要素です。
エンゲージメントがエージェントを活用するようになるにつれて、Cassandra は水平方向のスケーラビリティ、速度、堅実な安定性を提供することで不可欠なものとなり、エージェント ベースのアプリケーションを強化するために必要なデータを保存するための自然な選択肢となります。
このため、Cassandra コミュニティは重要な機能を開発しました。
それはどのように行われていますか?
先ほど触れたように、組織がエージェント アプリケーション エクスペリエンスを作成するには、いくつかの方法があります。
開発者が次のようなフレームワークについて話しているのを聞くことができます。
しかし、このようなエクスペリエンスの構築を進める最も重要な方法は、現在世界中で最も人気のあるエージェントである ChatGPT を活用することです。
これはソーシャルネットワーク プラットフォームとなり、そこに接続できるゲーム、コンテンツ、ニュース フィードを構築する組織の巨大なエコシステムが形成されました。 ChatGPT はその種のプラットフォーム、つまり「スーパー エージェント」になりました。
開発者は、LangChain のようなフレームワークを使用して、独自のエージェントベースのアプリケーション エクスペリエンスの構築に取り組んでいるかもしれませんが、それだけに焦点を当てると、莫大な機会コストが発生します。
ChatGPT プラグインに取り組んでいない場合、組織は、ChatGPT が提供できる情報やユーザーに推奨できるアクションの範囲に、ビジネスに固有のコンテキストを統合する大規模な配布の機会を逃すことになります。
Instacart、Expedia、OpenTable、Slack などのさまざまな企業
変化をもたらすアクセス可能なエージェント
ChatGPT プラグインの構築は、企業が取り組むことになる AI エージェント プロジェクトの重要な部分となります。
適切なデータ アーキテクチャ (特にベクトル データベース) を使用すると、適切な情報を迅速に取得して応答を強化できる、非常に高性能なエージェント エクスペリエンスを構築することが大幅に容易になります。
すべてのアプリケーションはAIアプリケーションになります。 LLM や ChatGPT プラグインなどの機能の台頭により、この未来はよりアクセスしやすくなりました。
ベクトル検索と生成 AI について詳しく知りたいですか? 7 月 11 日に開催される無料デジタル イベント、Agent X: Build the Agent AI Experience にご参加ください。
Ed Anuff、DataStax 著
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
ラベル
Languages
この記事は...
関連ストーリー
暗号取引におけるサイバーセキュリティ: 知っておくべきことすべて
#cybersecurity



