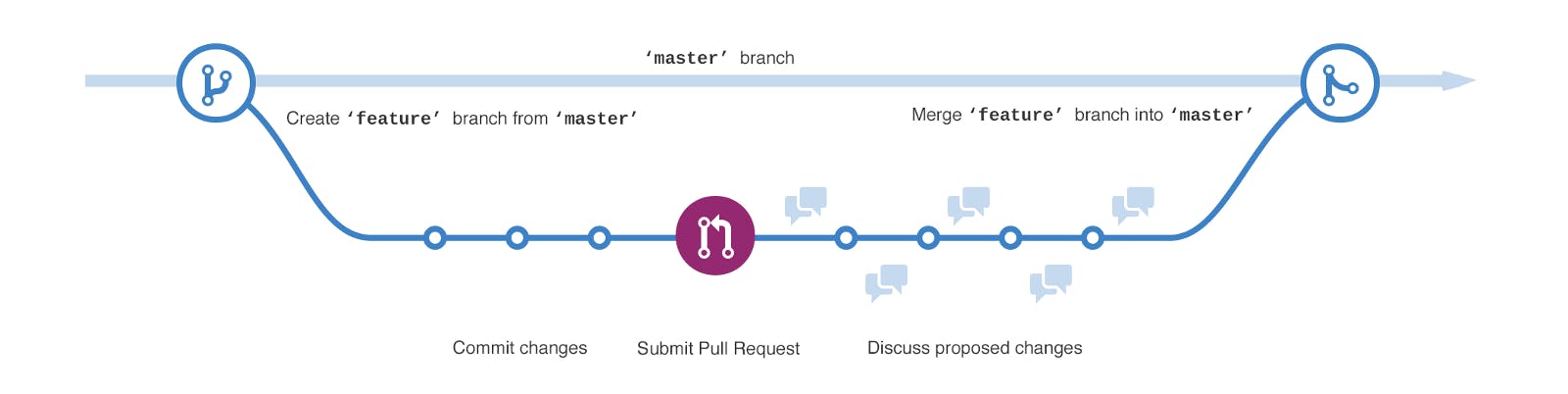
You’ve probably heard your engineers talking about , Github, or source control. It may have been in the context of “let me pull the latest changes from git” or “Github is down; let’s go grab a beer.” So wtf is git? git To set the stage, let’s start with an analogy. Let’s say you’re working on drafting a newsletter in collaboration with several colleagues. What are some problems that you may face? Let’s say that Google Docs and similar online editors haven’t been invented yet, as they solve many of these problems, and, in fact, git can be thought of as Google Docs for code. Each of your colleagues is responsible for a different section and you’re all working in parallel. How do you aggregate the final version? You could each write your sections separately and then get together to merge it at the end, but then you can’t see what they’re working on until that point so you can’t coordinate a consistent flow and proofread each other’s work. You’re , but you wake up on the day the newsletter is supposed to go out and realize you introduced a weird error that you can’t figure out. How do you easily revert to an older version or review the changes you made that might have caused the problem? skilled in HTML Your colleague makes some minor edits and sends a revised version for you to proofread. How do you know what changes they made so you don’t have to re-review the whole thing? You’re on an airplane or one of the few other remaining places where a wifi signal is hard to come by. How to you continue your work and sync up with your colleagues once you’re back online? Your computer crashes or you use multiple computers to get your work done. How do you ensure you can pick up where you left off on another machine? Suppose your company produces many such newsletters and is working on multiple at the same time. Now suppose your designer makes a change to the header. How do you apply this to all current and future newsletters without a lot of copy & pasting? Now take these problems, multiply them by the number of engineers on your team, and assume they can all be working on adjacent parts of the code at the same time. And it’s just one gigantic newsletter with tens or hundreds of thousands of sentences that lasts indefinitely through the life of your product. That’s more or less what it feels like working on a software development team. Source control solutions like git make these challenges manageable. Git is the most popular system around. There are others (subversion, perforce, mercurial), but git is by far the most popular these days. You can think of a source control system as a Dropbox or Google Drive specifically for code. Engineers new code to the system and they each other’s changes. For the remainder of the article, I’ll refer only to git, but most principles apply to the other source control systems as well. source control commit pull The main reason to use a source control system is to enable collaboration. If a project only has one engineer, it’s feasible for them to avoid using source control, although they likely want to anyway for some of the other benefits that we’ll discuss. They could save their files on their laptop, make modifications as necessary, and copy code from their laptop to production servers. But as soon as two or more engineers are working on the same codebase, this quickly becomes unmanageable. How would they share code? Email it to each other whenever there are changes? What if they’re working in the same area of the code and make conflicting changes? Without knowing about source control, your first thought might be to store code in a centralized place like Dropbox or Google Drive so multiple engineers can modify the same codebase. But these solutions are aren’t well suited for source code. It would be easy to mistakenly overwrite each other’s changes whenever one person saves new code to the drive or another person downloads their colleague’s changes and it’s hard to see what changed and when. Branching Source control is analogous to a tree. There is typically one copy of the code, and then many “branches” — that is, copies of the code with modifications. Those branches can themselves have branches, hence the tree analogy. Branches are typically created when an engineer starts working on a new feature or a new bug fix. Branches can then be back together when work on it is complete. The definition of “complete” varies by team: it may be as soon as it’s ready for testing, after it’s code reviewed, or after it passes QA. master merged Different development teams have different workflows that result in different branch structures. Git itself doesn’t enforce any structure on the “shape” of the tree, and branches upon branches can become unmanageable. Imagine a multi-month project that is being developed by a large team of developers and requires several rounds of QA. An initial branch might be created for the feature, then each developer creates a branch off of that one to work on their portion of the project. Bugs are found in those branches so new branches are created off of them… you can see how it can quickly become a mess. Most people agree that the best practice is to strive to minimize the number of active branches under development at one time. A typical workflow includes a branch which is the code running in production (sometimes referred to as the branch since it is supposed to be the most stable and thoroughly tested branch), a branch which tracks what’s on the company’s staging environment (sometimes called or for “work in progress”). Developers branch off of — that is, they create a new branch that starts as a copy of the development branch — to work on new features or fixes, then the branch back to the development branch after it is tested and reviewed. The development branch is merged into the master branch when the team is ready to deploy to production. The master branch becomes the code that is running in production, either automatically through a process (the topic of a future post) or through a manual process. The team might also have a _hotfix_process for quick, emergency changes that need to be deployed immediately, where a branch is created off of the master branch instead of the development branch and merged back to master as soon as it is ready. master golden development dev wip development merge continuous deployment Merging Branching (eg. creating a new branch) is pretty straightforward; not much can really go wrong. It’s essentially the same as copying a directory on your hard drive into a new location. Merging can be a lot more complicated. With slightly different clones of the same code, how do you resolve differences? If not done perfectly, someone’s change could get overwritten or, worse, an incorrect merge could result in the whole application not working — source code is not very forgiving. Git is quite good at merging code automatically when changes are completely unrelated to each other, but requires manual intervention when two or more developers are working on the same portion of the code. This is known as a , which means that git couldn’t confidently merge the changes automatically so developers need to do it manually. This happens more often than you’d think: even though your codebase has tens or hundreds of thousands of lines of code, there tend to be hotspots that are changed much more frequently than others, and recently introduced features tend to require more changes and bug fixes than long established code. When the same portion of code is affected, git conservatively prompts developers to review the differences and choose the appropriate course of action, which is not always obvious. Fortunately, git provides excellent tools to assist in this process. Still, you might hear your engineers talking about a “bad merge,” which means that something went wrong that either overwrote someone’s change or broke the application in an unexpected way. merge conflict Git History One of git’s most powerful features is that it maintains a complete history of all changes that have ever been made to the codebase. You can see any old version of the code and any branch unless it has been intentionally deleted. This is especially useful when something goes wrong. When a collection of changes are deployed to production and a new bug arises that doesn’t seem to be directly related to any of them (which, as we explored in , happens regularly), git allows developers to explore what changed, when, why, and by whom. It also lets engineers quickly to an old change, which is especially useful when something serious occurs upon deploying to production: reverting to a previous version is usually faster than debugging the problem and fixing the new code. These are some of the reasons developers might use git even for solo projects. why is everything broken revert Git history is also useful outside of emergencies. New developers can look back at previous changes to see how similar tasks were implemented in the past. Obscure bugs can be tracked down by viewing the git changes at a particular point in time to see what might have changed when the problem started to occur. Git has a cheekily named but quite useful command displays which person made the last change affecting any line of code. blame Github Great, I understand source control and git now! But WTF is Github? Git is open source software that needs to run on a server somewhere. A system administrator or developer could set up a server to make this happen, but you’d have to pay for it, deal with maintenance and upgrades, and worry about backups (you definitely do NOT want to lose your source control repository!) It’s cheaper and easier to use a hosted solution, and Github is the market leader (there are others, including Atlassian’s Bitbucket, which is sometimes chosen for its more generous free tier). So Github simply runs git for you so your engineers don’t have to. Github has also invested in tools and user interfaces to make using git easier and easier. Code reviews While not strictly dependent on source control, let’s take a quick moment to discuss code reviews. Code reviews — also known as because is a git command used for merging and retrieving branches — are commonly used by development teams to proofread each other’s work. Many teams have a policy that no code is merged to the development or master branch without at least one code review. pull requests pull In a typical code review, a developer who is familiar with the code in question but did not write it themselves will read through the — the highlighted difference between the old code and the new code — and add suggestions. Code reviewers occasionally catch bugs, but that’s not really the main point. More common critiques relate to code style and more efficient ways to accomplish tasks. In some companies, this is a formal process where an engineering leader must sign off on code before it is merged; in others it is an informal process. On teams that I’ve run, code reviews are required but it is an informal process and there is no requirement that the reviewer be more senior than the person who wrote the code. Regardless of experience, both people involved can learn something through the process. diff So do I need to learn git? In the past, I’ve taught some non-technical colleagues to use git so they could contribute simple changes such as copy, images, and light HTML modifications. As I’ve , I’ve found it incredibly useful to early stage for the founders and non-technical team members to learn to perform somewhat technical tasks on their own to let engineers focus on things only they can do. Learning to use git takes your autonomy to the next level by letting you actually modify production code on your own. Think what you could do if you could modify copy, themes, etc. regularly without distracting your engineering team. written before startups But I’m not going to teach you how to do it here. The bulk of the work is in learning your team’s codebase and their source control workflow. Hopefully their workflow includes code reviews, which should prevent you from getting into too much trouble. Git is extremely powerful; even most senior engineers only understand a subset of git. Ask your engineer if it makes sense for you to set up git and start making small changes yourself.