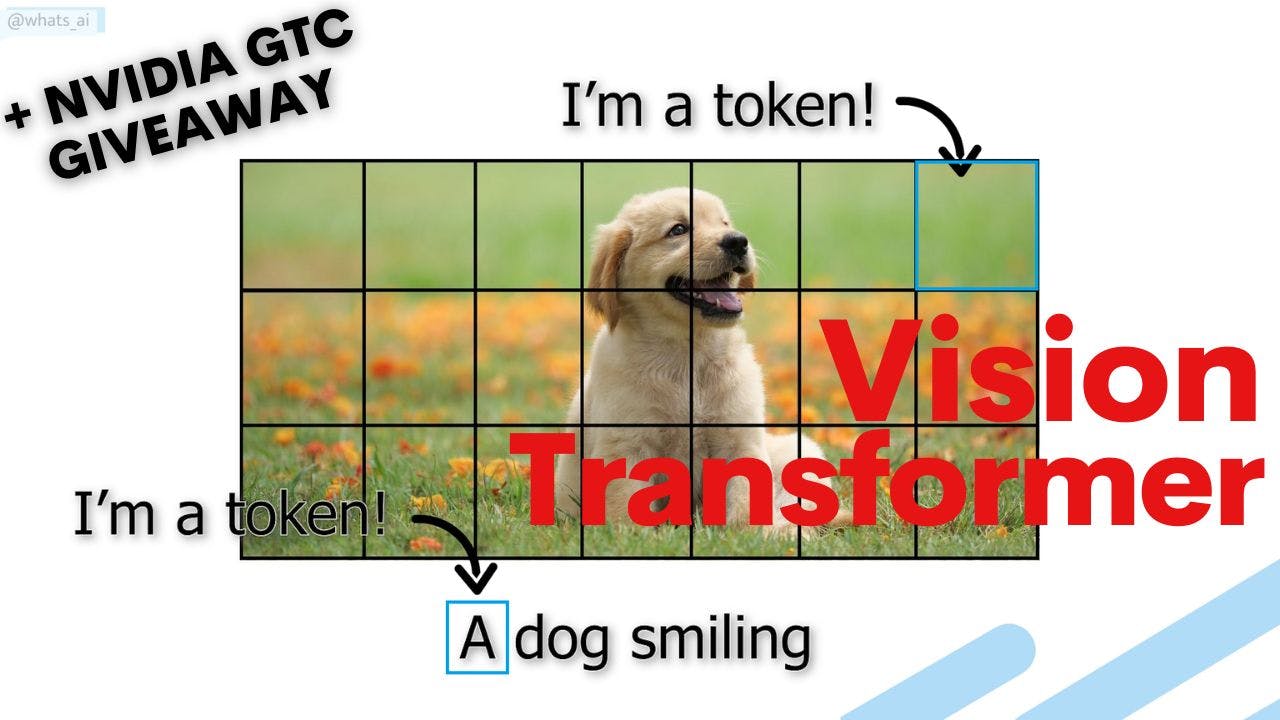
In a couple of minutes, you will know how the transformer architecture can be applied to computer vision with a new paper called the Swin Transformer. As a bonus, make sure you stay until the end of the video for a giveaway sponsored by NVIDIA GTC! References ►My Newsletter (subscribe here to have a chance to win!): http://eepurl.com/huGLT5 ►Register to the GTC event: https://www.nvidia.com/en-us/gtc/?ncid=ref-crea-331503 ►DLI courses: https://www.nvidia.com/en-us/training/ ►Paper: Liu, Z., “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows”, 2021, https://arxiv.org/abs/2103.14030v1 ►Code: https://github.com/microsoft/Swin-Transformer Video transcript 00:00 This video is about most probably the next generation of neural networks for all computer 00:05 vision applications: The transformer architecture. 00:09 You've certainly already heard about this architecture in the field of natural language 00:13 processing, or NLP, mainly with GPT3 that made a lot of noise in 2020. 00:19 Transformers can be used as a general-purpose backbone for many different applications and 00:23 not only NLP. photo: transformers, gpt3 00:25 In a couple of minutes, you will know how this transformer architecture can be applied 00:29 to computer vision with a new paper called the Swin Transformer by Ze Lio et al. from 00:35 Microsoft Research. 00:37 Before diving into the paper, I just wanted to tell you to stay until the end of the video, 00:41 where I will talk about my newsletter I just created and the next free NVIDIA GTC EVENT 00:47 happening in two weeks. 00:48 You should definitely stay or skip right to it as I will provide you with the timeline 00:53 as usual because I will be hosting a giveaway in collaboration with NVIDIA GTC! 00:58 This video may be less flashy than usual as it doesn't really show the actual results 01:03 of a precise application. 01:04 Instead, the researchers showed how to adapt the transformers architecture from text inputs 01:10 to images, surpassing computer vision state-of-the-art convolutional neural networks, which is much 01:15 more exciting than a small accuracy improvement, in my opinion! 01:19 And of course, they are providing the code for you to implement yourself! 01:23 The link is in the description. 01:25 But why are we trying to replace convolutional neural networks for computer vision applications? 01:30 This is because transformers can efficiently use a lot more memory and are much more powerful 01:36 when it comes to complex tasks. 01:38 This is, of course, according to the fact that you have the data to train it. 01:43 Transformers also use the attention mechanism introduced with the 2017 paper Attention is 01:48 all you need. 01:49 Attention allows the transformer architecture to compute in a parallelized manner. 01:54 It can simultaneously extract all the information we need from the input and its inter-relation, 02:00 compared to CNNs. 02:02 CNNs are much more localized, using small filters to compress the information towards 02:07 a general answer. 02:08 While this architecture is powerful for general classification tasks, it does not have the 02:13 spatial information necessary for many tasks like instance recognition. 02:18 This is because convolutions don't consider distanced-pixels relations. 02:23 In the case of NLP, a classical type of input is a sentence and an image in a computer vision 02:29 case. 02:30 To quickly introduce the concept of attention, let's take a simple NLP example sending a 02:34 sentence to translate it into a transformer network. 02:38 In this case, attention is basically measuring how each word in the input sentence is associated 02:44 with each word on the output translated sentence. 02:47 Similarly, there is also what we call self-attention that could be seen as a measurement of a specific 02:53 word's effect on all other words of the same sentence. 02:57 This same process can be applied to images calculating the attention of patches of the 03:01 images and their relations to each other, as we will discuss further in the video. 03:06 Now that we know transformers are very interesting, there is still a problem when it comes to 03:11 computer vision applications. 03:12 Indeed, just like the popular saying "a picture is worth a thousand words," pictures contain 03:18 much more information than sentences, so we have to adapt the basic transformer's architecture 03:23 to process images effectively. 03:26 This is what this paper is all about. 03:28 This is due to the fact that the computational complexity of its self-attention is quadratic 03:33 to image size. 03:35 Thus exploding the computation time and memory needs. 03:38 Instead, the researchers replaced this quadratic computational complexity with a linear computational 03:44 complexity to image size. 03:47 The process to achieve this is quite simple. 03:50 At first, like most computer vision tasks, an RGB image is sent to the network. 03:55 This image is split into patches, and each patch is treated as a token. 04:00 And these tokens' features are the RGB values of the pixels themselves. 04:04 To compare with NLP, you can see this as the overall image is the sentence, and each patch 04:10 is the words of that sentence. 04:13 Self-attention is applied on each patch, here referred to as windows. 04:17 Then, the windows are shifted, resulting in a new window configuration to apply self-attention 04:22 again. 04:23 This allows the creation of connections between windows while maintaining the computation 04:28 efficiency of this windowed architecture. 04:31 This is very interesting when compared with convolutional neural networks as it allows 04:35 long-range pixel relations to appear. 04:38 This was only for the first stage. 04:41 The second stage is very similar but concatenates the features of each group of two by two neighboring 04:47 patches, downsampling the resolution by a factor of two. 04:50 This procedure is repeated twice in Stages 3 and 4 producing the same feature map resolutions 04:57 like those of typical convolutional networks like resnets and VGG. 05:03 You may say that this is highly similar to a convolutional architecture and filters using 05:07 dot products. 05:08 Well, yes and no. 05:10 The power of convolutions is that the filters use fixed weights globally, enabling the translation-invariance 05:16 property of convolution, making it a powerful generalizer. 05:20 In self-attention, the weights are not fixed globally. 05:23 Instead, they rely on the local context itself. 05:26 Thus, self-attention takes into account each pixel, but also its relation to the other 05:32 pixels. 05:33 Also, their shifted window technique allows long-range pixel relations to appear. 05:38 Unfortunately, these long-range relations only appear with neighboring windows. 05:43 Thus, losing very long-range relations, showing that there is still a place for improvement 05:47 of the transformer architecture when it comes to computer vision, 05:51 As they state in the paper, "It is our belief that a unified architecture 05:55 across computer vision and natural language processing could benefit 05:59 both fields, since it would facilitate joint modeling of visual and textual signals and 06:04 the modeling knowledge from both domains can be more deeply shared" 06:08 And I completely agree. 06:10 I think using a similar architecture for both NLP and computer vision could significantly 06:15 accelerate the research process. 06:17 Of course, transformers are still highly data-dependent, and nobody can say whether or not it will 06:23 be the future of either NLP or computer vision. 06:26 Still, it is undoubtedly a significant step forward for both fields! 06:31 Now that you've stayed this far let's talk about an awesome upcoming event for our field: 06:36 GTC. 06:37 So what is GTC2021? 06:38 It is a weeklong event offering over 1,500 talks from AI leaders like Yoshua Bengio, 06:45 Yann Lecun, Geoffrey Hinton, and much more! 06:48 The conference will start on April 12 with a keynote from the CEO of NVIDIA, where he 06:53 will be hosting the three AI pioneers I just mentioned. 06:57 This will be amazing! 06:58 It is an official NVIDIA conference for AI innovators, technologists, and creatives. 07:04 The conferences are covering many exciting topics. 07:07 Such as automotive, healthcare, data science, energy, deep learning, education, and much 07:11 more. 07:12 You don't want to miss it out! 07:14 Oh, and did I forget to mention that the registration is completely free this year? 07:18 So sign-up right now and watch it with me. 07:21 The link is in the description! 07:23 What's even cooler is that NVIDIA provided me 5 Deep Learning Institute credits that 07:28 you can use for an online, self-paced course of your choice worth around 30$ each! 07:34 The deep learning institute offers hands-on training in AI for developers, data scientists, 07:40 students, and researchers to get practical experience powered by GPUs in the cloud! 07:45 I think it's an awesome platform to learn, and it is super cool that they are offering 07:49 credits to give away, don't miss out on this opportunity! 07:52 To participate in this giveaway, you need to mention your favorite moment from the GTC 07:57 keynote on April 12 at 8:30 am pacific time using the hashtag #GTCWithMe and tagging me 08:05 (@whats_ai) on LinkedIn or Twitter! 08:09 I will also be live-streaming the event on my channel to watch it together and discuss 08:13 it in the chat. 08:14 Stay tuned for that, and please let me know what you think of the conference afterward! 08:19 NVIDIA also provided me with two extra codes to give away to the ones subscribing to my 08:24 newsletter! 08:25 This newsletter is about sharing only ONE paper each week. 08:29 There will be a video, an article, the code, and the paper itself. 08:32 I will also add some of the projects I am working on, guides to learning machine learning, 08:37 and other exciting news! 08:39 It's the first link in the description, and I will draw the winners just after the GTC 08:43 event! 08:44 Finally, just a final word as I wanted to personally thanks the four recent Youtube 08:49 members! 08:50 Huge thanks to you ebykova, Tonia Spight-Sokoya, Hello Paperspace, and Martin Petrovski, for 08:58 your support and everyone watching the videos! 09:01 See you in the next one!