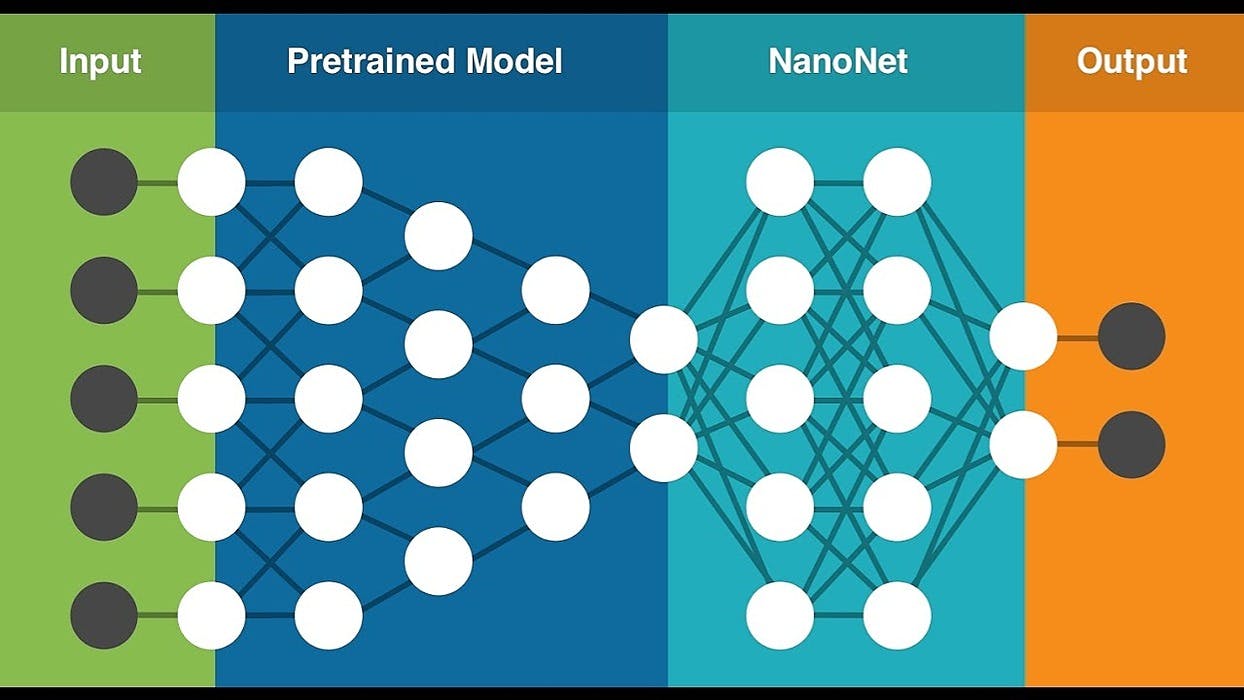
532 reads
Why Software Engineering Processes and Tools Don't Work for Machine Learning
by byComet@cometml
byComet@cometml
Allowing data scientists and teams the ability to track, compare, explain, reproduce ML experiments.
December 5th, 2019





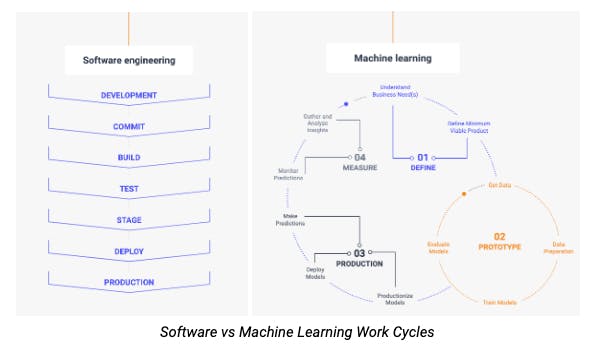
Allowing data scientists and teams the ability to track, compare, explain, reproduce ML experiments.


Allowing data scientists and teams the ability to track, compare, explain, reproduce ML experiments.
About Author

Allowing data scientists and teams the ability to track, compare, explain, reproduce ML experiments.
Comments