
1,635 reads
Approach Pre-Trained Deep Learning Models With Caution
by byComet@cometml
byComet@cometml
Allowing data scientists and teams the ability to track, compare, explain, reproduce ML experiments.
October 28th, 2019





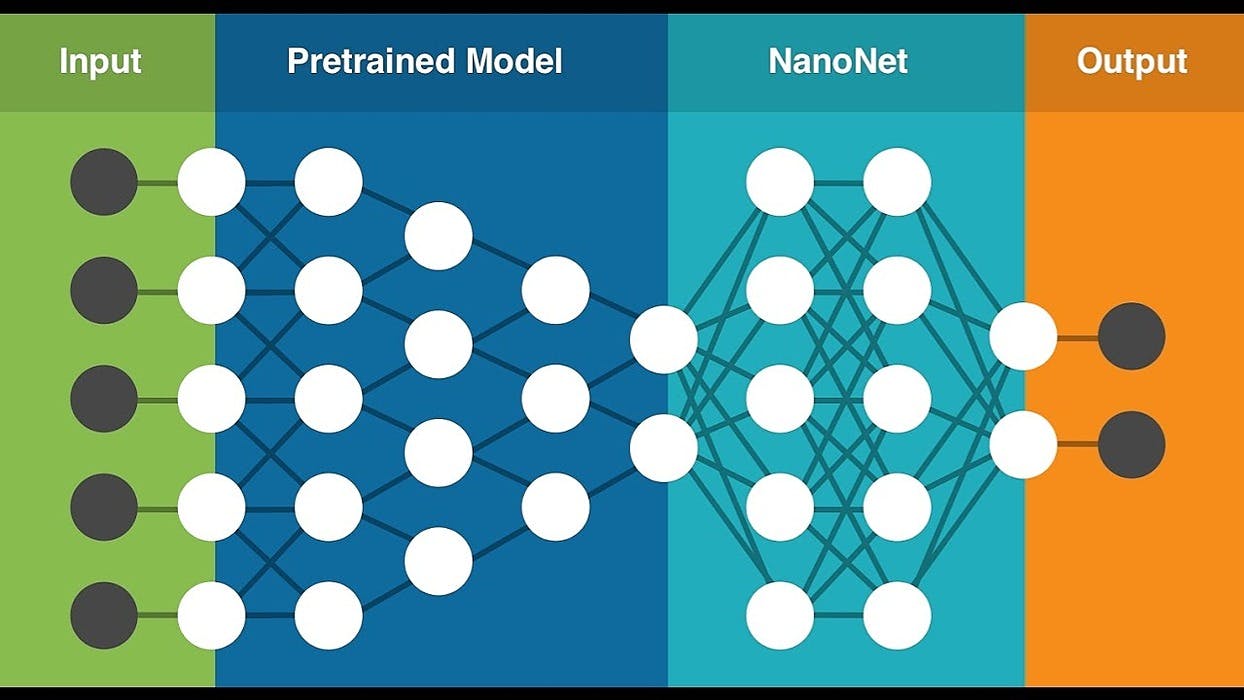
Allowing data scientists and teams the ability to track, compare, explain, reproduce ML experiments.


Allowing data scientists and teams the ability to track, compare, explain, reproduce ML experiments.
About Author

Allowing data scientists and teams the ability to track, compare, explain, reproduce ML experiments.
Comments

















