
1,708 reads
We Created a Simulated Video Call Demo with ChatGPT
by byCodeLink@codelink
byCodeLink@codelink
We provide high-quality professionals to help clients build and release highly impacting products.
July 6th, 2023





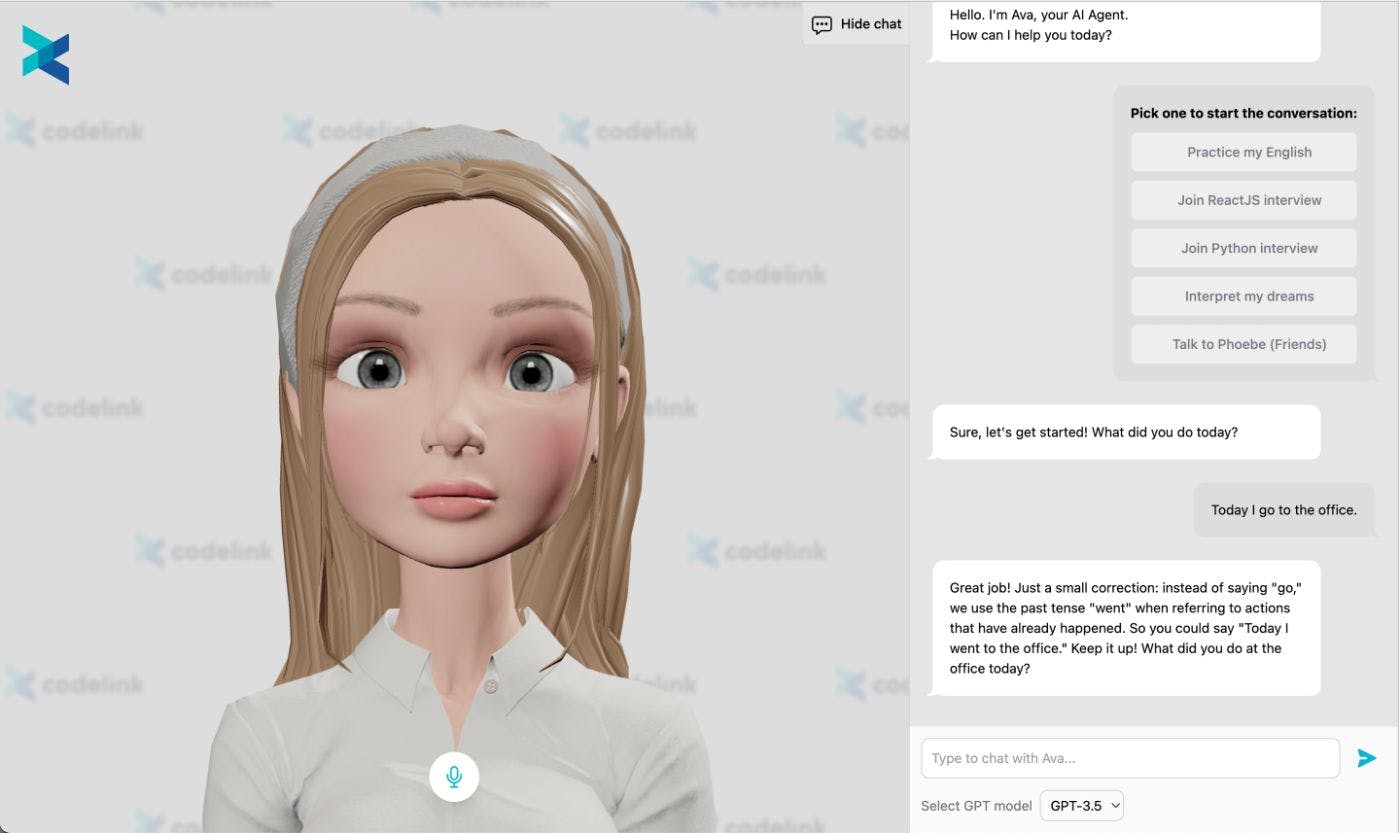
We provide high-quality professionals to help clients build and release highly impacting products.
Story's Credibility



We provide high-quality professionals to help clients build and release highly impacting products.
Story's Credibility
About Author

We provide high-quality professionals to help clients build and release highly impacting products.
Comments














