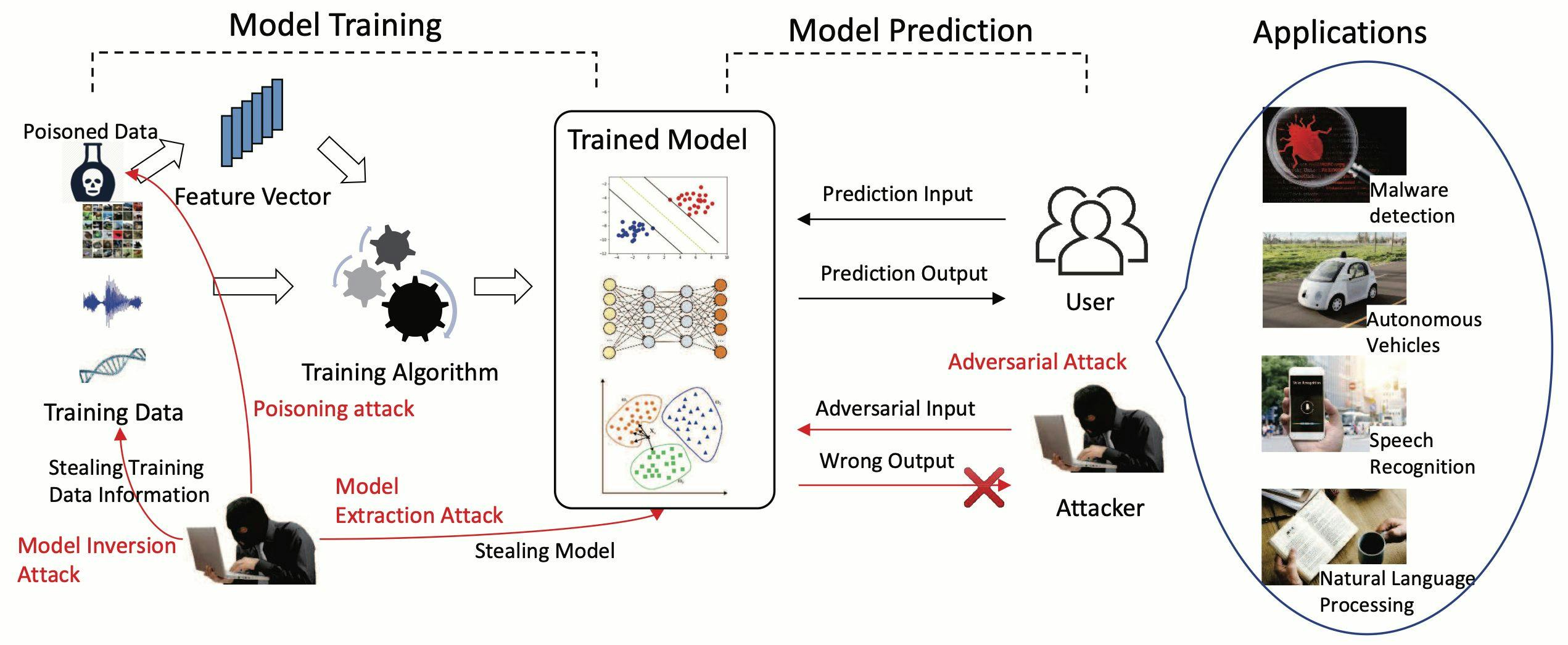
Authors: (1) Rui Duan University of South Florida Tampa, USA (email: ruiduan@usf.edu); (2) Zhe Qu Central South University Changsha, China (email: zhe_qu@csu.edu.cn); (3) Leah Ding American University Washington, DC, USA (email: ding@american.edu); (4) Yao Liu University of South Florida Tampa, USA (email: yliu@cse.usf.edu); (5) Yao Liu University of South Florida Tampa, USA (email: yliu@cse.usf.edu). Table of Links Abstract and Intro Background and Motivation Parrot Training: Feasibility and Evaluation PT-AE Generation: A Joint Transferability and Perception Perspective Optimized Black-Box PT-AE Attacks Experimental Evaluations Related Work Conclusion and References Appendix II. BACKGROUND AND MOTIVATION In this section, we first introduce the background of speaker recognition, then describe black-box adversarial attack formulations to create audio AEs against speaker recognition. A. Speaker Recognition Speaker recognition becomes more and more popular in recent years. It brings machines the ability to identify a speaker via his/her personal speech characteristics, which can provide personalized services such as convenient login [4] and personalized experience [1] for calling and messaging. Commonly, the speaker recognition task includes three phases: training, enrollment, and recognition. It is important to highlight that speaker recognition tasks [29], [118], [113] can be either (i) multiple-speaker-based speaker identification (SI) or (ii) single-speaker-based speaker verification (SV). Specifically, SI can be divided into close-set identification (CSI) and open-set identification (OSI) [39], [29]. We provide detailed information in Appendix A. B. Adversarial Speech Attacks Given a speaker recognition function f, which takes an input of the original speech signal x and outputs a speaker’s label y, an adversarial attacker aims to find a small perturbation signal δ ∈ Ω to create an audio AE x + δ such that f(x + δ) = yt, D(x, x + δ) ≤ ϵ, (1) where yt ̸= y is the attacker’s target label; Ω is the search space for δ; D(x, x + δ) is a distance function that measures the difference between the original speech x and the perturbed speech x+δ and can be the Lp norm based distance [29], [118] or a measure of auditory feature difference (e.g., qDev [44] and NISQA [113]); and ϵ limits the change from x to x + δ. A common white-box attack formulation [28], [72] to solve (1) can be written as where J (·, ·) is the prediction loss in the classifier f when associating the input x + δ to the target label yt, which is assumed to be known by the attacker; and c is a factor to balance attack effectiveness and change of the original speech. A black-box attack has no knowledge of J (·, ·) in (2) and thus has to adopt a different type of formulation depending on what other information it can obtain from the classifier f. If the attack can probe the classifier that gives a binary (accept or reject) result, the attack [118], [74] can be formulated as Since (3) contains f(x + δ), the attacker has to create a probing strategy to continuously generate a different version of δ and measure the result of f(x + δ) until it succeeds. Accordingly, a large number of probes (e.g., over 10,000 [118]) are required, which makes real-world attacks less practical against commercial speaker recognition models that accept speech signals over the air C. Design Motivation To overcome the cumbersome probing process of a blackbox attack, we aim to find an alternative way to create practical black-box attacks. Given the fact that a black-box attack is not possible without probing or knowing any knowledge of a classifier, we adopt an assumption of prior knowledge used in [118] that the attacker possesses a very short audio sample of the target speaker (note that [118] has to probe the target model in addition to this knowledge). This assumption is more practical than letting the attacker know the classifier’s internals. Given this limited knowledge, we aim to remove the probing process and create effective AEs. Existing studies have focused on a wide range of aspects regarding ground-truth trained AEs (GT-AEs). The concepts of parrot speech and parrot training create a new type of AEs, parrot-trained AEs (PT-AEs), and also raise three major questions of the feasibility and effectiveness of PT-AEs towards a practical black-box attack: (i) Can a PT model approximate a GT model? (ii) Are PT-AEs built upon a PT model as transferable as GT-AEs against a black-box GT model? (iii) How to optimize the generation of PT-AEs towards an effective black-box attack? Fig. 1 shows the overall procedure for us to address these questions towards a new, practical and nonprobing black-box attack: (1) we propose a two-step one-shot conversion method to create parrot speech for parrot training in Section III; (2) we study different types of PT-AE generations from a PT model regarding their transferability and perception quality in Section IV; and (3) we formulate an optimized blackbox attack based on PT-AEs in Section V. Then, we perform comprehensive evaluations to understand the impact of the proposed attack on commercial audio systems in Section VI. D. Threat Model In this paper, we consider an attacker that attempts to create an audio AE to fool a speaker recognition model such that the model recognizes the AE as a target speaker’s voice. We adopt a black-box attack assumption that the attacker has no knowledge about the architecture, parameters, and training data used in the speech recognition model. We assume that the attacker has a very short speech sample (a few seconds in our evaluations) of the target speaker, which can be collected in public settings [118], but the sample is not necessarily used for training in the target model. We focus on a more realistic scenario where the attacker does not probe the model, which is different from most black-box attack studies [113], [29], [118] that require many probes. We assume that the attacker needs to launch the over-the-air injection against the model (e.g., Amazon Echo, Apple HomePod, and Google Assistant). This paper is available on arxiv under CC0 1.0 DEED license. Authors: (1) Rui Duan University of South Florida Tampa, USA (email: ruiduan@usf.edu); (2) Zhe Qu Central South University Changsha, China (email: zhe_qu@csu.edu.cn); (3) Leah Ding American University Washington, DC, USA (email: ding@american.edu); (4) Yao Liu University of South Florida Tampa, USA (email: yliu@cse.usf.edu); (5) Yao Liu University of South Florida Tampa, USA (email: yliu@cse.usf.edu). Authors: Authors: (1) Rui Duan University of South Florida Tampa, USA (email: ruiduan@usf.edu); (2) Zhe Qu Central South University Changsha, China (email: zhe_qu@csu.edu.cn); (3) Leah Ding American University Washington, DC, USA (email: ding@american.edu); (4) Yao Liu University of South Florida Tampa, USA (email: yliu@cse.usf.edu); (5) Yao Liu University of South Florida Tampa, USA (email: yliu@cse.usf.edu). Table of Links Abstract and Intro Abstract and Intro Background and Motivation Background and Motivation Parrot Training: Feasibility and Evaluation Parrot Training: Feasibility and Evaluation PT-AE Generation: A Joint Transferability and Perception Perspective PT-AE Generation: A Joint Transferability and Perception Perspective Optimized Black-Box PT-AE Attacks Optimized Black-Box PT-AE Attacks Experimental Evaluations Experimental Evaluations Related Work Related Work Conclusion and References Conclusion and References Appendix Appendix II. BACKGROUND AND MOTIVATION In this section, we first introduce the background of speaker recognition, then describe black-box adversarial attack formulations to create audio AEs against speaker recognition. A. Speaker Recognition A. Speaker Recognition A. Speaker Recognition Speaker recognition becomes more and more popular in recent years. It brings machines the ability to identify a speaker via his/her personal speech characteristics, which can provide personalized services such as convenient login [4] and personalized experience [1] for calling and messaging. Commonly, the speaker recognition task includes three phases: training, enrollment, and recognition. It is important to highlight that speaker recognition tasks [29], [118], [113] can be either (i) multiple-speaker-based speaker identification (SI) or (ii) single-speaker-based speaker verification (SV). Specifically, SI can be divided into close-set identification (CSI) and open-set identification (OSI) [39], [29]. We provide detailed information in Appendix A. B. Adversarial Speech Attacks B. Adversarial Speech Attacks B. Adversarial Speech Attacks Given a speaker recognition function f, which takes an input of the original speech signal x and outputs a speaker’s label y, an adversarial attacker aims to find a small perturbation signal δ ∈ Ω to create an audio AE x + δ such that f(x + δ) = yt, D(x, x + δ) ≤ ϵ, (1) where yt ̸= y is the attacker’s target label; Ω is the search space for δ; D(x, x + δ) is a distance function that measures the difference between the original speech x and the perturbed speech x+δ and can be the Lp norm based distance [29], [118] or a measure of auditory feature difference (e.g., qDev [44] and NISQA [113]); and ϵ limits the change from x to x + δ. A common white-box attack formulation [28], [72] to solve (1) can be written as where J (·, ·) is the prediction loss in the classifier f when associating the input x + δ to the target label yt, which is assumed to be known by the attacker; and c is a factor to balance attack effectiveness and change of the original speech. A black-box attack has no knowledge of J (·, ·) in (2) and thus has to adopt a different type of formulation depending on what other information it can obtain from the classifier f. If the attack can probe the classifier that gives a binary (accept or reject) result, the attack [118], [74] can be formulated as Since (3) contains f(x + δ), the attacker has to create a probing strategy to continuously generate a different version of δ and measure the result of f(x + δ) until it succeeds. Accordingly, a large number of probes (e.g., over 10,000 [118]) are required, which makes real-world attacks less practical against commercial speaker recognition models that accept speech signals over the air C. Design Motivation C. Design Motivation C. Design Motivation To overcome the cumbersome probing process of a blackbox attack, we aim to find an alternative way to create practical black-box attacks. Given the fact that a black-box attack is not possible without probing or knowing any knowledge of a classifier, we adopt an assumption of prior knowledge used in [118] that the attacker possesses a very short audio sample of the target speaker (note that [118] has to probe the target model in addition to this knowledge). This assumption is more practical than letting the attacker know the classifier’s internals. Given this limited knowledge, we aim to remove the probing process and create effective AEs. Existing studies have focused on a wide range of aspects regarding ground-truth trained AEs (GT-AEs). The concepts of parrot speech and parrot training create a new type of AEs, parrot-trained AEs (PT-AEs), and also raise three major questions of the feasibility and effectiveness of PT-AEs towards a practical black-box attack: (i) Can a PT model approximate a GT model? (ii) Are PT-AEs built upon a PT model as transferable as GT-AEs against a black-box GT model? (iii) How to optimize the generation of PT-AEs towards an effective black-box attack? Fig. 1 shows the overall procedure for us to address these questions towards a new, practical and nonprobing black-box attack: (1) we propose a two-step one-shot conversion method to create parrot speech for parrot training in Section III; (2) we study different types of PT-AE generations from a PT model regarding their transferability and perception quality in Section IV; and (3) we formulate an optimized blackbox attack based on PT-AEs in Section V. Then, we perform comprehensive evaluations to understand the impact of the proposed attack on commercial audio systems in Section VI. D. Threat Model D. Threat Model In this paper, we consider an attacker that attempts to create an audio AE to fool a speaker recognition model such that the model recognizes the AE as a target speaker’s voice. We adopt a black-box attack assumption that the attacker has no knowledge about the architecture, parameters, and training data used in the speech recognition model. We assume that the attacker has a very short speech sample (a few seconds in our evaluations) of the target speaker, which can be collected in public settings [118], but the sample is not necessarily used for training in the target model. We focus on a more realistic scenario where the attacker does not probe the model, which is different from most black-box attack studies [113], [29], [118] that require many probes. We assume that the attacker needs to launch the over-the-air injection against the model (e.g., Amazon Echo, Apple HomePod, and Google Assistant). This paper is available on arxiv under CC0 1.0 DEED license. This paper is available on arxiv under CC0 1.0 DEED license. available on arxiv