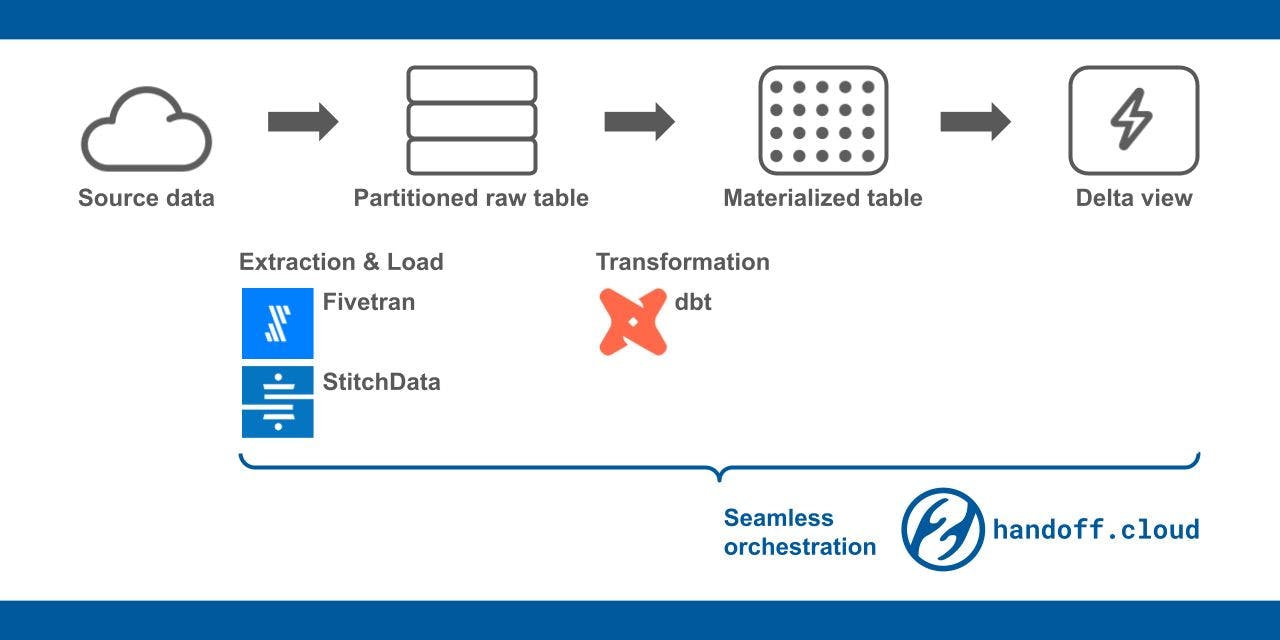
This blog will cover holistically: (a) What data warehousing is (b) Data modeling approaches for Data warehouse (c) Data warehouse on AWS, and lastly (d) Data warehousing for reducing operational load using Managed Service. Let’s understand from a layman’s perspective “ ” What a Data warehouse is As per - Wikipedia a data warehouse (DW or DWH), also known as an enterprise data warehouse (EDW), is a system used for reporting and data analysis and is considered a core component of . Data warehouses are central repositories of integrated data from one or more disparate sources. They store current and historical data in one single place that is used for creating analytical reports for workers throughout the enterprise. This is beneficial for companies as it enables them to interrogate and draw insights from their data and make decisions. business intelligence In basic terms, it is the art of collecting, storing, and efficiently providing insights (business intelligence) to help a business become a data-driven organization. In some sense it’s another transaction database but one that is optimized for analytical workloads. As per the above diagram, data is collected from the source, transformed per usage (ETL/ELT), and stored in DWH/Data mart and Insights exposed via business intelligence tools. All looked simple back in the days of on-prem setup when ELT (ETL vs ELT), Cloud DWH (AWS Redshift, Google Big Query, Snowflake, Databricks), and other Managed Data solutions were non-existent, which lately simplified and scaled the reach of DWH. In this blog let’s understand every aspect one at a time. For simplicity let’s go with the premise that there is no infinite compute & storage and that the transactional system can’t process analytical queries efficiently. This is where an efficient way was required to design a data warehouse that is optimal in storage, efficiently handles analytical queries (Slicing/dicing/Cube, etc), and provides required latency. For all this, two theoretical design model for came into the picture by: Datawarehouse design (a) Bill Inmon – Top Down approach (EDW) and (b) Ralph Kimball – Bottom-up approach (Data mart). Inmon’s approach is to build at a global scale centrally and factor in slow build whereas Kimball's way is to make an independent data mart by silo and connect together later. Let’s not dive into which model is best or which to choose. In my case, in a nutshell, both models work and it totally depends on the use case and maturity of the organization. Another key point in this design is the “Data Representation”, Dimensional modeling using Star Schema, Snowflake schema, or a Hybrid of Star and snowflake which is a key pivot of faster querying and dimensionality. The only key takeaway is despite infinite logistics, a good Datawarehouse design can solve a multi-dimensional problem. So, better not to ignore it. The next step in is the platform of choice which can vary from on-premise (Teradata, IBM DB2, Oracle, etc) to Cloud DW (Snowflake, Redshift, BigQuery, etc). Building a traditional data warehouse is complex, and ongoing management and maintenance can be challenging and expensive. In the next section, we will dive into how to build with AWS Redshift (no argument if on-prem is better or Cloud or which cloud DWH is better). Building a DW Amazon Redshift is a fully managed petabyte scale enterprise-grade data warehouse that provides exceptional performance for analytics queries which is simple to use and cost effective. Amazon Redshift reduces the operational overhead required with traditional data warehouses by automating tasks such as patching, backups, and hardware provisioning. You can configure an Amazon Redshift cluster where you can customize the infrastructure and performance baselines for your data warehouse. Amazon Redshift also provides Redshift Spectrum, Datashare, Redshift ML, and Serverless setup which allows you to use Amazon Redshift cluster beyond DWH. The way to Setup, Define what services to leverage for data collection (AWS DMS, DynamoDB, EMR, Glue, Kinesis, S3, SSH Host, etc) Define a way to interact (Query analysis tools and Management Interfaces) Understand Redshift MPP architecture (Distributed, shared-nothing) Launch Cluster (DC2, DS2, or RA3) with required data size, growth, node, and query performance Design database schema as per use case or DWH implementation with required Data type, schema type, compression, buffer, encoding Loading data using COPY for different file types, INSERT for minimal alter, and ANALYZE & VACUUM for maintenance Perform query optimization and performance enhancement Leverage S3 using Spectrum for external table and Data share for zero-copy Use Redshift ML for deep insights Leverage AWS Quicksight for BI tooling to get insights. So far it makes sense to use Cloud DWH but ? The image below explains how Data Lakes and Data Warehouses work together seamlessly. AWS RDS serves as the data source, providing a cost-effective and durable solution, that feeds into . The data is then transformed using ETL processes and onboarded into Redshift. Additional AWS services such as Athena, Glue, Spectrum, Lake Formation, and others play a crucial role in bridging the gap to create a comprehensive Data Solution. How does this fit in the Big scheme of things DWH + Data Lake/Managed Services for Data solution Amazon S3 In conclusion, this blog covers the fundamentals of Data Warehousing, delves into the implementation approach both theoretically and with a focus on the tech stack. We also gain a bird's-eye view of how it seamlessly integrates into the broader landscape of data solutions.