268 reads
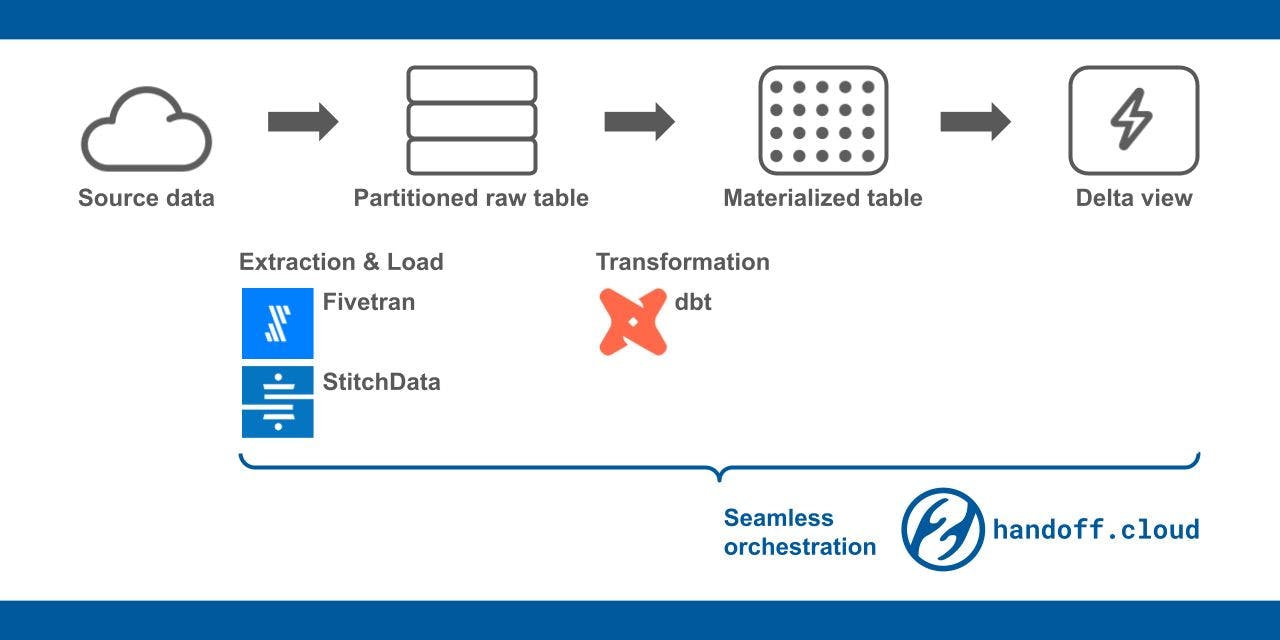
Cost Effective Data Warehousing: Delta View and Partitioned Raw Table
by byhandoff.cloud by ANELEN@handoff
byhandoff.cloud by ANELEN@handoff
💥 New: Bring any data to where decisions take place without hiring a data engineer 👉 https://handoff.cloud
September 17th, 2021





💥 New: Bring any data to where decisions take place without hiring a data engineer 👉 https://handoff.cloud


💥 New: Bring any data to where decisions take place without hiring a data engineer 👉 https://handoff.cloud
About Author

💥 New: Bring any data to where decisions take place without hiring a data engineer 👉 https://handoff.cloud
Comments