
501 reads
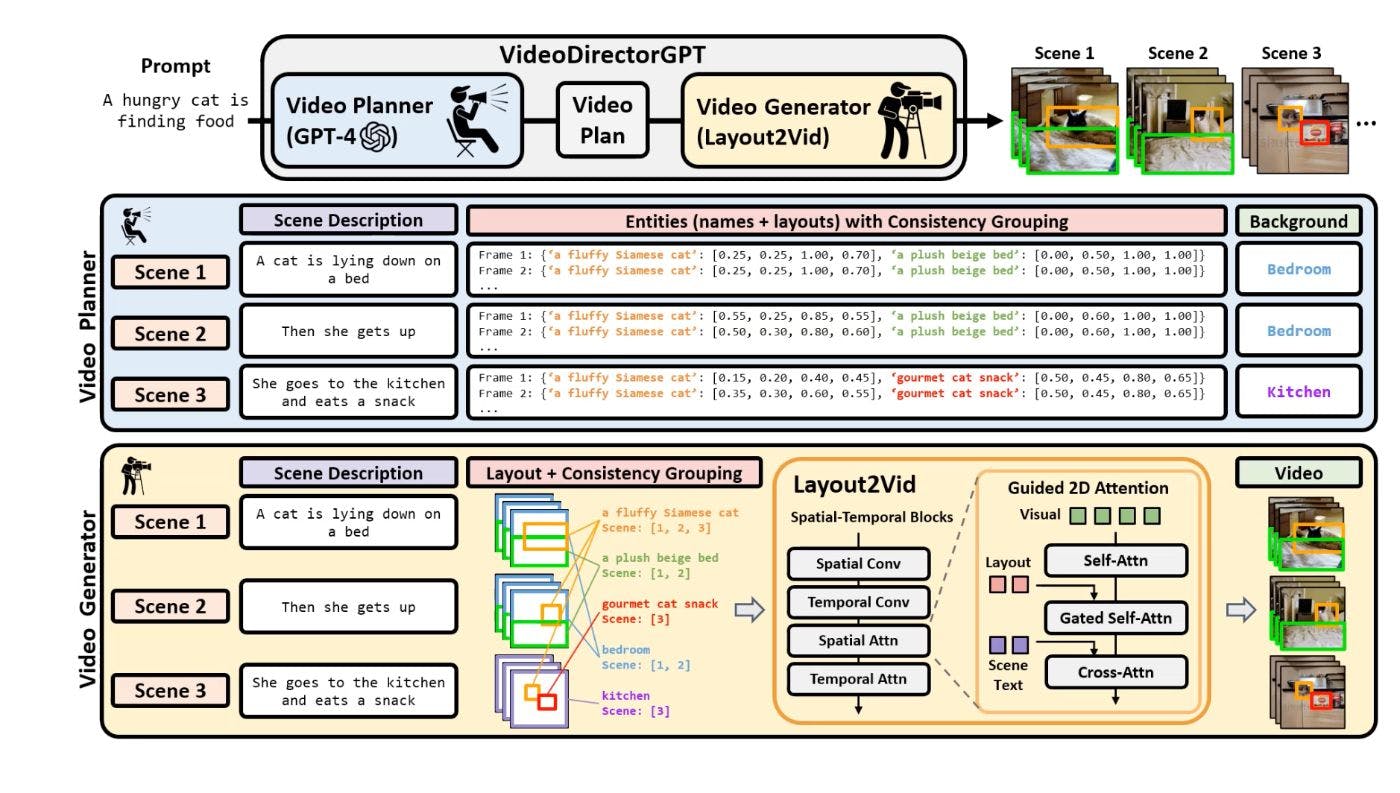
UNC Presents VideoDirectorGPT: Advancing Multi-Scene Video Generation with AI
by byaimodels44@aimodels44
byaimodels44@aimodels44
Among other things, launching AIModels.fyi ... Find the right AI model for your project - https://aimodels.fyi
October 3rd, 2023





Audio Presented by
Among other things, launching AIModels.fyi ... Find the right AI model for your project - https://aimodels.fyi
Story's Credibility


Among other things, launching AIModels.fyi ... Find the right AI model for your project - https://aimodels.fyi
Story's Credibility
About Author

Among other things, launching AIModels.fyi ... Find the right AI model for your project - https://aimodels.fyi
Comments














