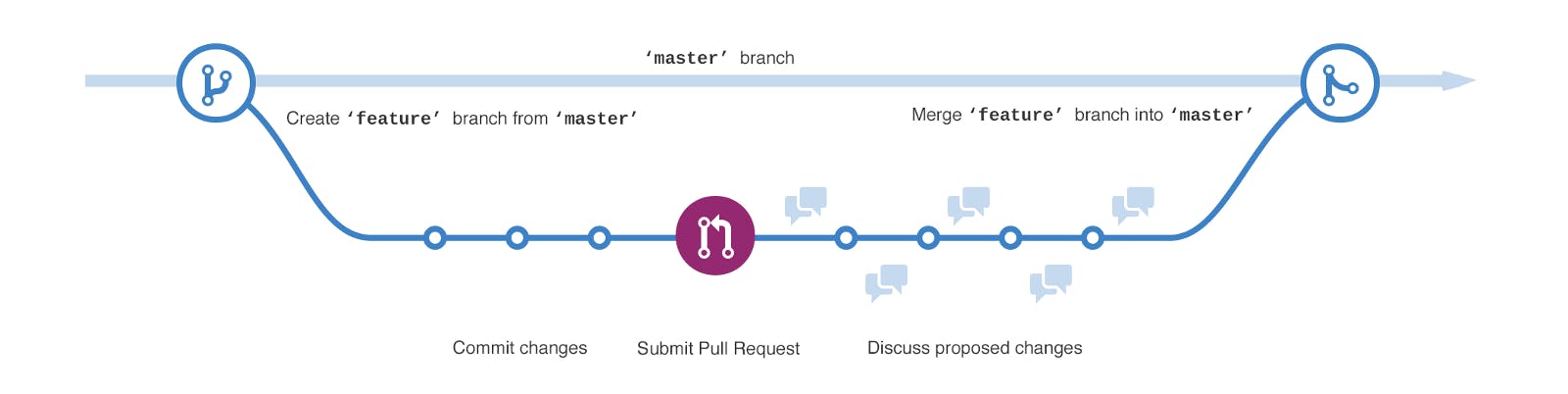
Git, debugging, testing, the terminal, Linux, the cloud, networking, patterns/antipatterns - what even is this mess? Don't worry we'll go through it from beginning to end (all the way, I promise) everything you need to know to collaborate proficiency with others. Why so many tools? We're flooded with tools which are all titled , but... why so many of them? To answer this let's start at the very beginning and slowly work our way through our coding journey! essential to boost productivity We all started on a small solo project working to build an app, create a simple model, or just to finish an assignment. As we begin to code we notice that it just... doesn't run 😢 and so we sigh, take a deep breath in and begin to look for what went wrong. The first bug is just a small innocent typo, but with time we start running into more and more silly pesky bugs 🐞, each one a slight bit harder to deal with than the last! Once we read our code, find the typo and fix it (a little golden ) our coding journey continues, and we work on creating something slightly more impressive. debugging We soon get to a crossroad, we finish working on our small little program and want to work on something slightly more ambitious (yay)! Although we're ambitious, we notice one small thing - we make a good few mistakes. Like any good student, we get a few books, read a few articles, watch a few videos, and before long we've learned several which make for a nice, smooth coding experience and ... to avoid like the plague. design patterns antipatterns Now with a few sophisticated patterns/antipatterns in mind, we feel like we're ready to show the world our coding prowess! We start névé and nervous but with passion, and so through gathering a few friends together, we begin a new chapter of our lives 😅. The work is fun and everyone wants to play their part, but soon one question arises - ? how can we work together At first, emailing/messaging code from one person to another works fine... but then a few more people pitch in, and combining every line of code becomes - unmanageable! In a moment of chaos, one man did the impossible though, Linus Torvalds extended his olive branch and gave us Git - the perfect system to collaborate with others. Eventually, we approach another challenge, although we're writing the code just fine... we feel bogged down by our workflow. To our surprise, there's an easy and elegant solution - Linux and the terminal. Linus Torvald proposes Linux as an (the ugly behemoth) and with it a terminal to write code in a fashion which completely 's Windows. alternative to Windows bash Now with our workflow smoothened out, there are just a few questions left - how can we run this code anywhere and what if we need... more? Luckily for us, the dot com boom unfolds and the internet is ablaze! What we once had to run (other people/companies servers). Now we can run and distribute progressively larger (and more heavyweight) code right from the comfort of our houses! on our machines, can now be run on the cloud The epochs Chapter 1 - Debugging Our code is bound to have problems... even if we're genius', they'll still crop up! We can't *completely avoid them, but we can approach each problem in just the right way, so we're able to smoothly eliminate it. There's a simple technique to help with this: - Keep it simple stupid, the simpler it is the easier it is to find the problem! SIMPLIFY - It's fine when we don't know what's wrong, relax and start exploring, use a few print statements, read a few errors and try to figure things out 😌 EXPLORE - Try to find where your code goes south (focused effort reveals bugs quickest) ISOLATE Now I know it's , but ... it makes a big difference! Just remember to keep calm, take a deep breath 🫁 and continue, if it's a bug you'll find and destroy it with time and effort 😌! easier said than done just try this out Chapter 2 - Testing Our code works... or does it? Testing is all about finding whether something which actually . It's about finding whether your changes break how things work (likely in a subtle way). seems to work fine works fine Testing can be simple, or complex. At its simplest, it's about looking at what we think our code does and double-checking just that, in a more complex light it's about writing (yes, code to test the code). small pieces of code (unit or integration tests) to test the code Unit tests are for small isolated tests/scenarios and integration tests for larger/more realistic ones. Although this sounds simple (so far), testing is extremely nuanced as the way we write code has an extremely large impact on our ability to test it (hence knowledge of patterns/anti-patterns may be useful)! There's a lot to testing and I'm not an expert, but I hope that this is enough to get you going/give you some sense of direction... Chapter 3 - Design Patterns/Anti-patterns Patterns and antipatterns are just good and bad coding practices we should try and use more/less respectively. Although at their heart ! In essence, we see good and bad code all the time, so learning these comes naturally, however lots of books/articles go into fine detail by naming and shaming. design patterns/anti-patterns are simple, they tend to be sorely overcomplicated All have three basic purposes, to help , organise ( ) or communicate ( ) between classes and objects. design patterns create structural behavioural A few examples: - creating classes which are only initialised (used) once Singleton - when we abstract (group) multiple algorithms (or models) into one class so they can easily be swapped out Strategy - when multiple objects need to know about when an event is triggered we can distinguish between observers and callers Observer Since are just mistakes they're a good few that exist: anti-patterns - when we're stuck planning and never start coding Analysis paralysis - when we use code without understanding it Cargo cult programming - the last 10% of our work takes 90% of our time Rule of credibility - when all our code is in one large clump Big ball of mud - where our code isn't cleanly separated Spaghetti code - creating excess classes/code for no reason Poltergeist - can just use classes/functions when code is used in multiple places Repeated logic/redundant code - names should be short but still express meaning Ambiguous naming of variables and functions - fixed values with an unknown purpose Magic strings Note it's more practical to pick these all up through carefully inspecting code (especially off Stack Overflow)! Chapter 4 - Git Git is the collaboration one-stop-shop! It is elegant and beautiful once we learn to use it... but seemingly not before that 😧. Don't worry though, it's quite simple, Git works through tracking what changes we make (hence it's called ), and it does this by breaking up our timeline into chunks that we've (commits). version control committed to using We may now ask though - how does this help to combine our changes? Luckily for us, it's not too difficult to interpret, Git stores our work in which can be shared and . Whenever we make changes we can these and then them out to our online repositories (technically called remote repositories). Then once we're ready to share our brilliant code we can (with a pull request)! Although this all just sounds weirdly social right now, it gets useful when Git provides us with overviews of our changes, so we're certain that our team's outstanding work won't collide/conflict with our work. repositories forked/cloned commit push pull others over to see/confirm what we've done Now there are a few more technical ways we can to use Git, primarily through segmenting work/progress into and providing special ways to . allow us to highlight particular parts of our codebase which we'd like to share, whilst also allowing us to isolate certain which may be unstable/not quite ready yet! The first way to combine branches is to by adding the changes made into a new commit. The second is to (which we call a ). Which one we use depends on our situation: branches combine our changes Branches features merge changes replay one branch's changes on another rebase When we try to make our commit history as simple as possible, a rebase is an amazing and flexible option If we need to remove, modify, combine or change the order of commits, to keep a simple and clean history, only a rebase will suffice However, just like time travel, a rebase is dangerous whenever we do it on anything others are using In practice (this is often referred to as the ) only rebase non-publish/non-used code golden rule Now that we've discussed the difficult concepts, let us take a look at the terminal (explained further below) commands we can use: To clone a repository git my_website_url clone To add a file/folder to be tracked in the next commit (stores changes at the time the commend's run) git commit -m "added amazing new features" To change branches git checkout my_branch To create and switch to a new branch git checkout -b my_new_branch To push git push To merge branches git merge my_feature_branch To rebase a branch (n is the number of commits to consider) git rebase -i HEAD~n To add an upstream branch git remote add upstream original_repo_url To sync a local repository (to its remote) git fetch upstream A few mistakes to avoid: The URL to a Git repository doesn't include any specific file/folder We fork repositories to keep an isolated version to work with ourselves before we're ready to pull together our work (so our changes don't affect each other in the middle of things) So the URL to enter when a repo to work with is and then the original repositories main branch becomes the forked repositories (as it's likely newer) cloning your forked version upstream branch Be careful when copy-pasting their URLs as they're quite easy to mix the wrong way round Note the upstream branch only has to be set once Pull requests happen through an online UI (i.e. the GitHub website) not the terminal (normally) Once we start an interactive rebase, carefully read the provided options Chapter 5 - Linux and the Terminal As explained above, Linux is an amazing replacement for Windows (it's free by the way) which is far more flexible and lightweight! One distinct feature is the inbuilt powerful terminal (called bash) which allows us to perform complex tasks easily. Here are the essential commands: List files ls ls my_folder Change directory (into another folder) folder_path cd Move a file/folder mv old_location new_location Copy a file cp file_location copy_location Copy a folder cp -r folder_location copy_location Run another program (like a text editor, normally vi, vim or nano) program_location Although they don't seem anything out of the ordinary, the terminal provides a solid way to do a variety of tasks! Note if you ever enter a text editor you can't seem to close (likely vi/a variant of vi) hit escape and then :q! If you liked this article, please share, follow me on Twitter and check out my blog where I've explain other complex topics like web scraping and Photos by Kevin Ku on Unsplash , Kevin Horvat on Unsplash , Yancy Min on Unsplash Michael Dziedzic on Unsplash