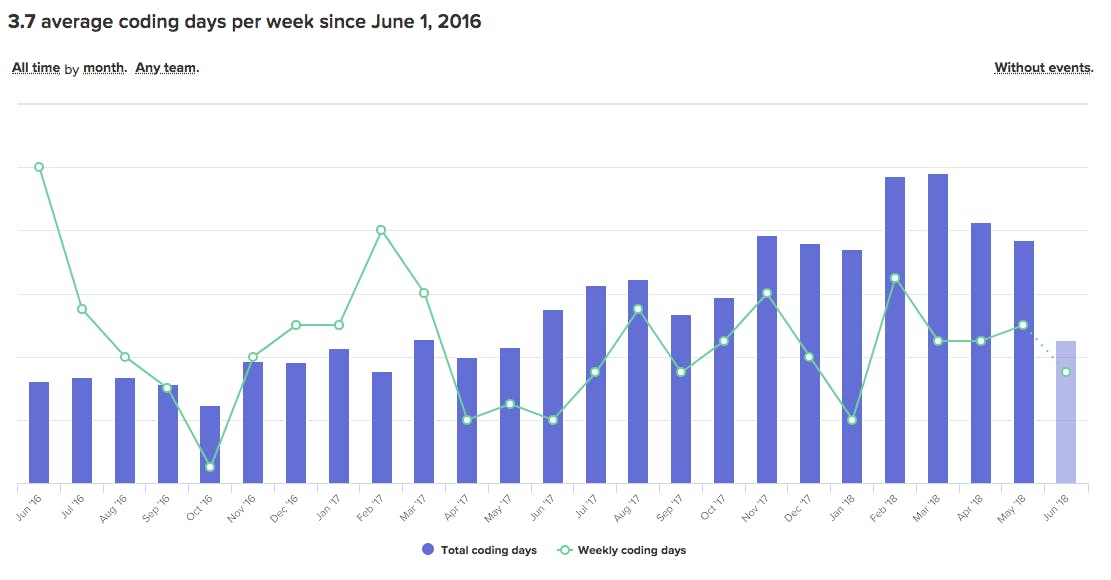
Most of you know me as a product person, but in the past year-and-a-half, I’ve been leading our R&D team @Bizzabo. Since taking the lead, I’ve searched for the best way to measure R&D team performance in a way that reflects the true value the team provides. We started by using the industry standard measure to track team performance: planning versus delivery. measuring These were our Team KPIs: : in order to become better in planning Deviation of up to 20% : we believe small tasks are better handled and can be better executed Average of 2 days per task Uptime of 99.95% My challenge was that these KPIs were not directly connected to the true value of the R&D team. We could easily deliver on the KPIs even if the pace was slow and the quality was low. After 6 months of iterations and changes, I decided to define R&D KPIs that would better reflect the value of a well-functioning R&D team — team and quality. velocity I want to pause for a second and recognize the team of for their Velocity product. It helped us to get to where we are today. Go and check them out. Code Climate Let’s review what is encompassed by the term “R&D velocity”: Work Habits Number of coding days per week Number of code pushes per day (push early, push Small) Pull Request (PR) Size Time from review request to merge Code Quality Code complexity Code documentation Test coverage Number of bugs Uptime Efficiency Percent of re-work Number of abandonment PRs Number of reverts Once we broke down the different drivers we went and checked how we perform in each one in order to select which KPIs will drive the fastest ROI if we focus on them first. Let deep dive into each one: Number of coding days per week The average number of days per week that a team member is coding (defined as pushing at least one commit). You might argue that one commit does not reflect well, but I challenge you to start simple or to suggest a better metric that is easy to quantify. Number of code pushes per day How many pull requests are merged per active contributor per unit of time. Number of code pushes per day PR Size This one required a bit deeper dive to understand what is a good PR size for us. But we weren’t sure how we could set a clear number. The key was to find the number of lines of code that would take a peer less than an hour of work to code review, and approve the PR. Having to code review longer than an hour is a challenging task, and as a result, the review will probably be less thorough. In turn, this will make it challenging to as more bugs will get into production. Our optimal PR size is less than 250 lines of code. In reality, most of our PRs were even smaller save 33 hours Distribution of PR size Time from Review Request to Merge Think of this as a funnel for each step the PR needs to move through in order to be released to production: Time to review > Time to Approve > Time to Merge We wanted to have a clear internal SLA so 80% of the PRs would go through this funnel in a known time frame. It is a balance, and probably different for each team depending on mentality and culture. On one hand, we didn’t want a developer to wait too long for a review, on the other hand, we wanted to prevent the reviewer from having to context switch from her current task. We defined our goals as follows: Time to Review: 12 hours (same day review) Time to Approve: 3 hours after the first review Time to Merge: 12 hours after approval. We also defined a maximum of 2 reviewers to avoid having too many cooks in the kitchen. Code Complexity The definition — Number of lines of application code that are nested at least four levels deep within control structures like if statements, loops, etc. The KPI — Amount of complex code per thousand lines of code. Below you can see how we have simplified our code-base over the years. This was accomplished in large part by adopting new technologies (React/Redux, Kotlin, Microservices, Dockers and K8s) and by improvements made to our code-culture. Code complexity over time Code documentation We operate with a “no documentation” mentality. We believe you should write simple code that everyone can understand easily. (Though, to be fair we do have some comments)… Test Coverage Our R&D team doesn’t have a dedicated QA team. Every developer writes her own tests (unit test and end-to-end testing) and the Squad is responsible for the release quality. No new code is released without proper coverage. Full automation tests are run on every build. Number of Bugs Bugs are tricky to measure. When do you track them? What counts as a bug? Our great Customer Support team does an amazing job (first response time is less than 1.5 hours) and only escalates relevant issues to our R&D Escalation team ( ). We measure the number and severity of bugs every month. But what do you do as the team grows? We all know that as you write more code you have more bugs. we have an open position for a team leader We dived deep into the analysis to find a direct correlation between lines of code in a certain month to bugs, the number of releases (we have a full CI/CD in place) to bugs, and more. In the end, we decided to measure the ratio between the number of total PRs merged to the number of bugs. The number of bugs reported by customers by severity The number of total PR merged: Number of PR merged over time The ratio We defined our KPI as 0.2 (a bug for every 5 PRs merge) with 0 urgent bugs. UP-Time This one is pretty straightforward. We aim to measure our uptime per month to make sure our customers get the highest quality of service availability. We use for it, and we love them. :) statuscake Percentage of re-work A reworked line of code is any line of code committed and then edited within 3 weeks by the same author. The re-work ratio is calculated using this formula: (total unique reworked lines count) / (total unique changed or added lines count). There is no right or wrong way to measure re-work as this is a more team or company specific metric. This is especially true when some of the teams are working from the inside to the outside and the re-work is higher, or when some teams are working after intensive planning and sometimes are doing fast product iterations. The main idea is to be able to retrospect every feature development to see if the re-work is not due to changing requirements, or to a lack of sufficient technical direction. Number of abandoned PRs A pull request is considered “abandoned” if it is opened and then closed without merging. We also include pull requests that have been inactive for more than 3 days. This enables us to make sure we are focused on the most important tasks while minimizing our context-switches, and while making sure our work is not going to waste. When we look on abandoned PRs by age, it is clear that probably 90% of the PRs that are older than 30 days will never be merged again, in other words, it is lost code. After cleaning out the pipe and not counting PRs that were never meant to be merged (like POC, Tests, and some other internal needs), we will be able to retrospect any PR that is aging and understand why. We can determine if it’s a change in product prioritization, or if we never ended an initiative due to wrong estimations, etc. You can see that focusing on this KPI and putting processes in place made our squads working habits are more aligned; the deviation between the teams became smaller (since July where we kicked off our new KPI processes) abandoned PR per squad Number of reverts How much code is being reverted after merging? Revert is usually a direct outcome of an immediate bug (quality) or a fast understanding of a product/feature miss. We are not aiming for a specific number but we do use each revert as a trigger to have a dedicated retrospective. So, what do we use as our KPI? 1. We defined the attributes of a good R&D KPI: Measurable from the individual to the Squad (we are working in the ) to the whole team. Spotify Model Reflects and encourages the increase of throughput Connects to the quality of the work (and code). Challenges the team and make them better Delivery of the highest quality product in the shortest time. 2. After analyzing all the above we decided on the following KPIs for the team ( merged per active contributor per unit of time.) Throughput: 15 PR merged per Contributor per month. *How many PRs are (*A pull request is considered “abandoned” if it is opened and then closed without merging. We also include PRs that have been inactive for more than 3 days) Efficiency: PR abandonment rate < 5% Quality: 99.98% Uptime Quality: 0.2 Bugs/PR merged with 0 urgent tickets What do you think? Share your feedback or ask me a question in the comments. Explore our open positions here: https://www.bizzabo.com/careers/engineering