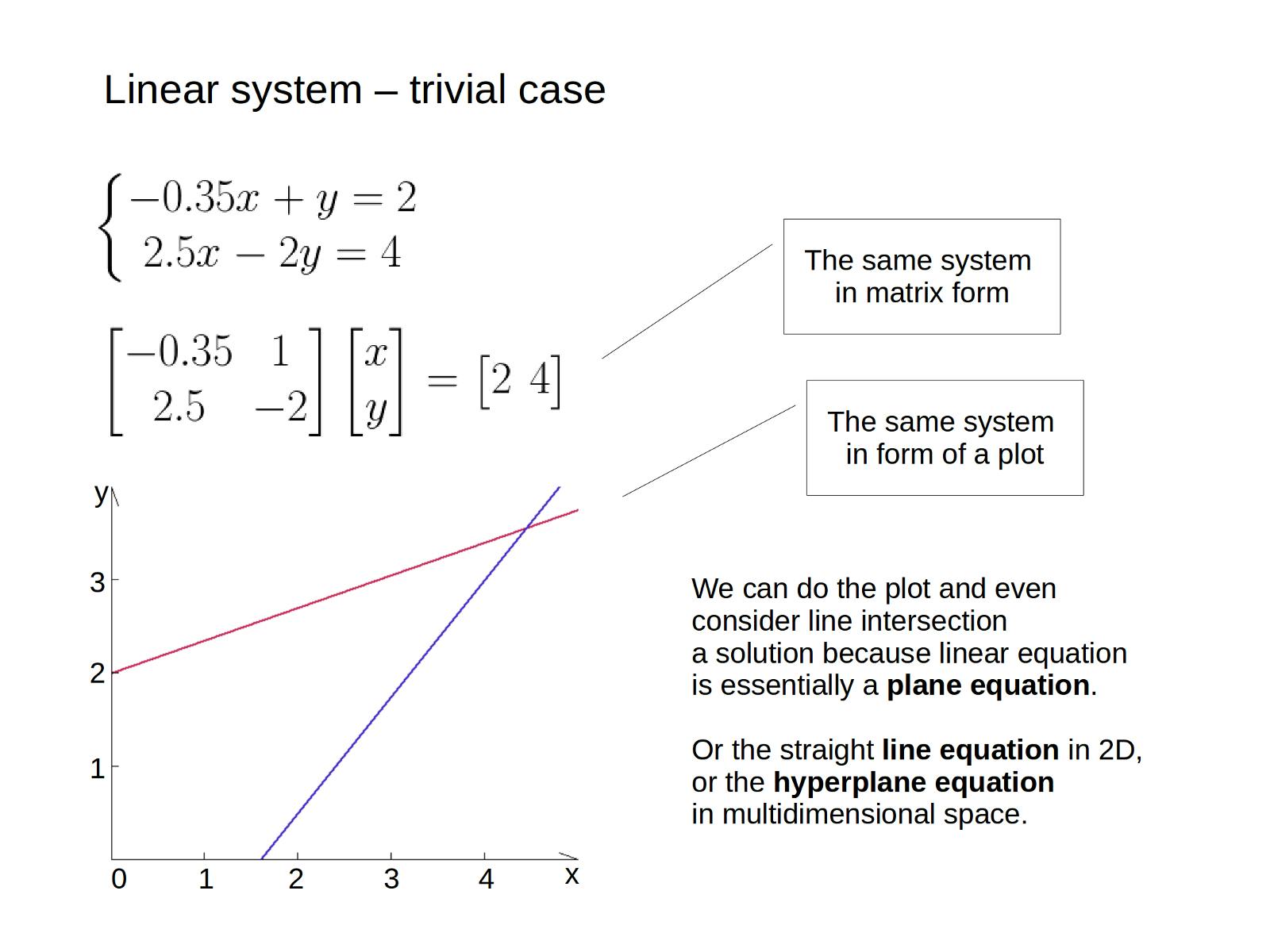
There is an interactive version of this piece on Words and Buttons: https://wordsandbuttons.online/programmers_introduction_to_linear_equations.html Systems of linear equations are usually taught in high school or college. Chances are, you already know how to solve them in several ways of which you have never had to use any in practice. So why would you want a guide on that? One reason is since the subject is widely known, it makes a perfect specimen to show a bunch of algorithmic stuff on. What’re iterative algorithms? What’s convergence? What’s error? How do you measure complexity? When it’s not working and why? These questions are worth a series of lectures each on their own, but it’s rather easy to illustrate them using a thing as simple as a linear system. Moreover, it’s not even that simple. It is easy conceptually, but there are corner cases, , and complexity constraints, — all the things that make programming interesting. Learning about them, or simply reviving what you already know, is the second reason you might want to read this guide. computational problems So let’s start from the trivialities and make our way into something fascinating, shall we? Let’s say you have two linear equations with two variables each. If these equations constitute a system, then there may be some combination of variables’ values for which both equations hold true. This is called a solution. Generally, for the system of two linear equations in two variables each, there is one solution. Not two, not a hundred, but one. It’s easy to imagine because every linear equation is the same as a plane equation, which is in our two-dimensional case a simple straight line. When two lines intersect anywhere in space, they only intersect once. But they may as well not intersect at all or coincide completely. That makes corner cases for a linear solver. First of all, we don’t always deal with n-equation of n-variables. If there are fewer equations than variables, then the system is . For our case, 1 equation with 2 variables, every point on the line the remaining equation specifies is a solution. Because yes, it satisfies all the equations just fine. But imagine two parallel planes in three-dimensional space. They also constitute an underspecified system, but they never intersect, so there is be no solution at all. underspecified If we have more equations than variables, we call the system . It probably has no solution at all. Yes, there may be intersections, but these points do not satisfy all the equations at once. Although, if for some happy reason three lines intersect in one single point, then they do satisfy all the equations, and it is a solution. In three dimensions there might even be four planes rotated along the same axis. The whole axis will be the solution. overspecified We really-really have no solution when the system is . This means it has parallel things in it. Lines, or planes, or hyperplanes, — if at least two of them never intersect, then there is no solution. inconsistent And we may have an infinite number of points as a solution if the system has at least two things that coincide. Regarding equations and not planes this is called . Well, we still might have one or none if there are other things, but that will presume that our system is overspecified as well. linear dependency Usually, the code we use to solve a system doesn’t do well with corner cases. It may detect that there is no solution, or return the first best point if solution holds an infinite number of them. Or just crash, or hang up forever. Let’s take a look at the simplest iterative solver. We all know the very basic properties of a right triangle. As soon as there is a triangle and it is right-angled, we just know that the is longer than the . Now if we take an arbitrary point in space, and its projection on one of the lines from the equation, and the solution (whichever it is), we will form a right triangle, right? And the distance from the solution to the projection will be smaller than to the original point. hypotenuse cathetus So if we project the point onto one of the lines, it will get a little bit closer to the solution than before. If we then project this new point to another line, it will get even closer. We will just repeat it iteration after iteration, that’s why it’s called an , until we done. iterative algorithm Well, technically we will never really hit a solution, so we can do this all day. But at some point, the distance to the solution will be less than some tiny number we consider an acceptable algorithm error. Generally, it’s ok not to have an absolute precision in calculations. We always have some error on gathering data and applying our calculation anyway. There is no point in calculating some detail length in nanometers if in reality it will be produced by millimeter blueprints. But this particular algorithm may have other flaws to worry about. There is an interactive introduction to iterative algorithm with this exact example: http://wordsandbuttons.online/interactive_introduction_to_iterative_algorithms.html It is very simple, but it also leaves at least four problems open: Where to start? When to finish? How many steps would it take to get to the point? In which cases it wouldn’t work at all? To answer these questions we have to get acquainted with the . convergence If the algorithm gets closer to the solution every step it does, we say it converges. Usually, it’s not trivial to assess convergence, but in our case, it’s rather visible. If the angle between lines is right, then the convergence is ideal. We get to the solution in just two steps! If the angle gets sharper, it takes more steps to go the same length in space, so we might say that the convergence gets worse. And if the lines are parallel, then the algorithm does not converge at all. It wouldn’t either, meaning, it can’t go further from the solution. But it would just play its ping-pong with the equations forever. diverge So, the convergence assessment answers at least two questions out of four. But actually, it affects all of them. The question “where to start” doesn’t make much sense without “when to stop”. Look, I don’t even have numbers on the plots. I don’t have a legend either. The delimiter on the axis may stand for one meter, or 0.25, or 1.e-25, or a pound. If it means 0.001 decibels and we want to find if our equipment makes any noise within 0.1-decibel error, then the starting point we have on a plot is a great finishing point already. We just have to confirm that. But we can only do that if we have the proper criteria. You see, we don’t really have a notion of where the solution is. That’s why we started the calculation in the first place. So we can’t just say that “we are close enough.” We don’t know that. There are only indirect ways to assume how far have we gone, but that’s it. One way would be to measure our progress. Presumably, if we stop moving on every iteration, and the algorithm converges, then we are there. But that’s exactly correct only if we are exactly at the solution point. Which is rarely the case. Usually, we just let ourselves have some error in that. Say, if we progressed less than a micrometer with the last step, then we don’t care about further progress at all because we calculate shed rafters length. Although, this is not exactly the error of the algorithm. The worse the convergence, the sooner we will get “stuck” within the stopping error, and “sooner” means “further from the end”, so the calculation error will be bigger. Technically we can adjust the stopping error to match algorithm error having some numeric convergence assessment, but it only looks simple with linear equations. Usually, it’s much more complicated. Picking and setting up iterative algorithms is an art in its own right. The one I showed is probably the worse in terms or convergence, so it’s not practically applicable. But it’s graphic enough, let’s exploit this even further. So, why do we have to deal with iterations at all? Why do we project our point orthogonally? Can’t we just project it along the other line? Yes, we can! It’s just two iterations, but there is no exit condition, no convergence involved, and the starting point doesn’t matter at all. They are not even the iterations anymore! That what makes an algorithm . direct But will it work faster than the iterative counterpart? In two dimensions the projection direction is fairly obvious, but what will happen if we raise the dimension? In 3D we can determine a projection direction as a cross-product of the two planes’ normal vectors. If 4D and higher we will use n-dimensional cross-product generalization. It has 3 nested loops each running n times. This means that for the 3-dimensional case the innermost loop will run 27 times. Not so bad. But we have to do this cross-product 3 times as well, so it will run 81 times in total. If we want to solve a system of four equations, it will run 256 times. 5 equations = 625 runs10 equations = 10000 runs100 equations = 100000000 runs1000 equations = 1000000000000 runs10000 equations = 10000000000000000 runs100000 equations = 1000000000000000000000 runs At some point, it will eat up all the resources Solar system has to offer. But not a bit more! That’s good. We can state that the complexity of the algorithm is bound from the top by some function that looks like . We usually use big `O` notation to state that. n power 4 However, this type of complexity assessment only measures how an algorithm reacts on changing n. It does not account for branching, cache misses, instruction count or any other thing that matters in real world programming. One huge mistake is to rely on the complexity assessment without actual measurement. For example, it’s always the different picture with the small data. With small enough data, most of the gains from the fast algorithm vanish because of the implementation overhead. You would be surprised how often people use trees instead of plain arrays without even realizing that the whole array fits in a cache line perfectly. But anyway, now when we have a direct algorithm and we know its complexity, we naturally want to make it smaller. Can’t we squeeze in at least ? n power 3 Sure, why not. The two systems from above are equivalent. It means, that whatever is true for the first is true for the second. And vice versa. The exact coefficients don’t matter, the order of equations doesn’t matter. Nothing matters but the truth. So if we do something with the equations that will not affect the truth, then the system will remain equivalent, right? Why don’t we then turn the left system into the right one in a few steps? Solving linear system in this way is called Gaussian elimination. Or decomposition. Or factorization. I never realized the difference. I guess, if we operate on matrices and want to look smart then it’s the latter. This method can be . Which is, of course, better than , but worse than . Hey, most of the iterative algorithms I know have an iteration with that exact complexity! n power 3 n power 4 n power 2 And here comes the dilemma. Iterative algorithms are cheaper, but they rely on convergence. Direct algorithms are more complex, but they do it all in one run. So what should I pick? Pick the one that fits your task. Exploit what you know about your systems. What do you know about your matrix? If it’s sparse, we have U_V-decomposition_ and even that both work efficiently on that. And if it’s triangular, you already have a half of decomposition done. If the matrix is diagonally dominant, then iterative methods such as or will probably work for you. And if you have a huge matrix, like with literally million equations, then you would usually have no option other than to use something iterative. Cholesky decomposition Jacobi Gauss-Seidel But sometimes you might want to pick a bad algorithm to achieve a good solution. There is a primitive direct method for solving linear systems. It’s called Cramer’s rule and it’s practically awful. It has complexity, and stability problems, and it only works on perfectly specified matrices. But there is one case when it absolutely beats the crap out of rivals. And it’s static computation. O(n*n!) The thing is, it is not only direct, it’s explicit. It doesn’t have any conditions, it doesn’t have loops, it doesn’t have exit criteria or any counters. It’s basically a formula that grows with the dimension. I only wrote a piece of code that generalizes this formula in order to win some microseconds on small systems, but it turns out, modern compilers are extremely good in optimizing explicit computations. They can do pretty amazing things with it. First of all. If you have your matrix and your vector both static — it will solve your system statically as well. This means , no run-time overhead apart from copying the answer from one place of RAM to registers. completely at compile time This is explained in more details in . Vastly Outperforming LAPACK with C++ Metaprogramming Maybe this looks just like a party trick. Not really practical. However, if you have a static matrix and a dynamic vector, it will still pre-compute a Cramer’s rule determinant and all the minors it can statically, so the run-time solution will be as cheap as possible. And solving semi-static problems is a common problem in practice. For example, if you compute a ton of small spline patches in parametric space, then most of your matrices are static points of the singular cube. All the real numbers go to the vector. Or if you want to find an inverse matrix, then you do three solutions with the static basis vectors. But that’s not all. Even if you don’t declare your matrix and vector static, but the compiler infers that some of their parts will never be touched, it can exploit this. If some of the untouched values are ones and zeroes, it can also use this to reduce a whole bunch of needless computation. Every time you build it with some particular semi-static data, it shortens the code using algebraic optimizations to make the most efficient solver for your task. Of course, you can do everything it does with pen and paper. But why would you? The compiler does a respectable amount of algebraic optimization, which in explicit code turns into… the very same algebra you would do manually. It does your algebra for you. How cool is that! Thank you for reading this! I hope this was helpful and not too boring. Oh, whom am I kidding? If linear algebra were not boring, they would have made a prequel to it. If you liked this, you might also enjoy: _Preface_hackernoon.com Floating point numbers explained with the Walpiri language, big boring tables, and a bit of algebra… _Why would you care about some homogeneous coordinates, whatever they are? Well, if you work with geometry: 3D-graphics…_hackernoon.com Programmer’s guide to homogeneous coordinates