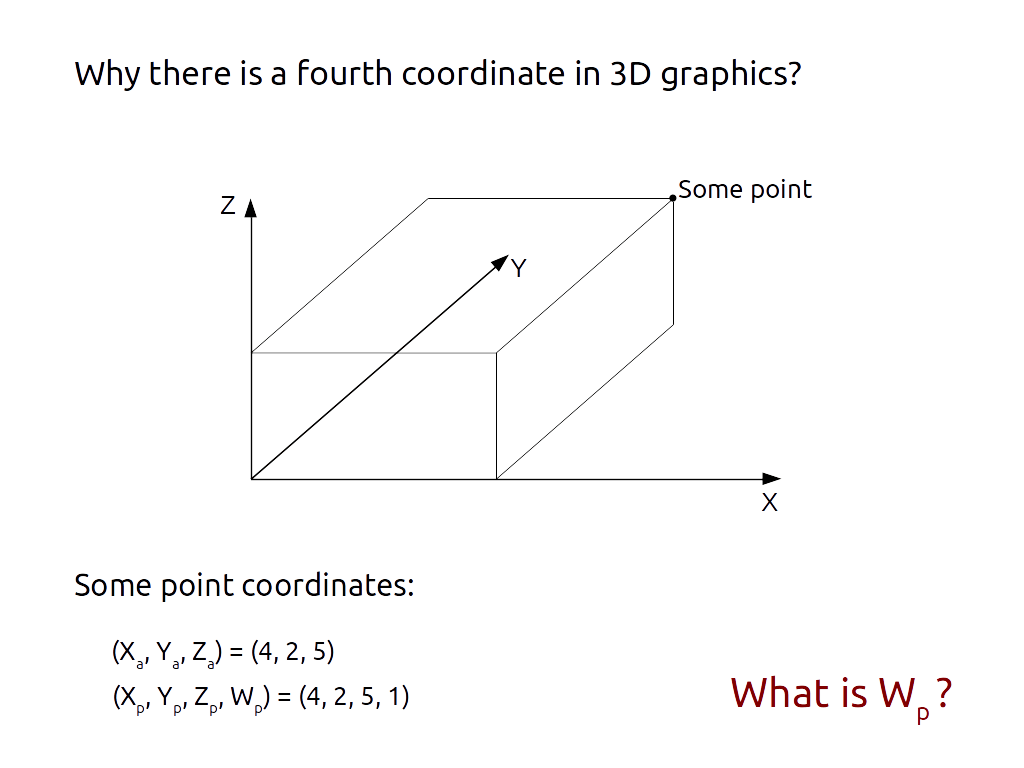An interactive version of this article is available here: http://wordsandbuttons.online/interactive_guide_to_homogeneous_coordinates.html Why would you care about some homogeneous coordinates, whatever they are? Well, if you work with geometry: 3D-graphics, image processing, physical simulation, the answer is obvious. Knowing the mathematics behind your framework of choice lets you write more efficient code. I once had to speed up one .NET application that bends pictures and simply re-implementing some primitive operations the right way . gave me 100 times performance boost But even if you don’t work with geometry at all, you still might benefit from learning the concept of homogeneous coordinates. This is the one rare example of mathematical magic when a small complication benefits in enormous simplification. One little obscurity pays off in terms of unification and homogenization. I think, learning this particular piece of geometry is a valuable experience in its own right. And you know how it works. More experience, higher level, better loot. So if you do work with 3D graphics, you might notice that it is quite common to write 3D points as a tuple of 4 numbers. The usual question here is: “what does that fourth coordinate stand for?” And the usual answer is: “Just set it to 1 and hope you wouldn’t screw anything!” And that is not the worst answer ever, because setting it to 1 indeed makes everything work like in good old Cartesian coordinates. But the fourth coordinate is much more interesting than that. Cartesian coordinates are just the first 3 numbers of homogeneous coordinates divided by the fourth. So if it is , then homogeneous coordinates is basically the same thing as Cartesian. But the smaller it gets, the further the point in Cartesian coordinates travels from the null. That’s all rather simple until one moment. What if the fourth coordinate is ? 1 0 Intuition tells, that it should be further from the 0 than every other point. Every other point in Euclidean space that is. Homogeneous coordinates indeed denote points not only in Euclidean or, more general, affine space, but in projective space that includes and expands affine one. From the pragmatic point of view, this lets us compose 3D-scene in a manner that every object that can be reached would fit in affine space with the coordinates , and all the objects that can never be reached will belong to projective extension . (x, y, z, 1) (x, y, z, 0) In this regard point on that extension in a way set a general direction and not a specific point in Euclidean space. A ray that starts at null and has no length, has no ending, only the direction. But could we just set the point very-very far and not get into this ‘1/0’ thing? Sometimes we can, but this might not always work as expected. The thing is, usually used to store geometry are not that large as they seem. Yes, they can technically store numbers from to but not in the same expression. Numbers with different exponent loose precision on every operation, and numbers with the same exponent only have 23 meaningful binary digits. This roughly denotes a range from to . If you want to have millimeter-sized details in every part of your scene, this means your scene should not be larger than 8 kilometers. Good enough for a third-person shooter, but not for a space simulator. floating point numbers 0.000000000000000000000000000000001 10000000000000000000000000000000000 0 8000000 Using projective space gives you more options. But that’s not all it is good for. In fact, we are only starting to get into the benefits. Central projection by Henrik Haggrén; Axonometric projection by Yuri Raysper [Public domain or Public domain], via Wikimedia Commons There are two kinds of projection in Euclidean space: central and parallel. Central projection is what makes the perspective, so the closer things seem bigger, and that’s what we use in video games to render a 3D scene into a flat picture on a screen. The parallel projection preserves proportions so that’s what we usually use in CAD systems to show bolts and nuts on drawings. In projective space they are the same. You see, in affine space you can set a center for a central projection very-very far away from the scene you want to render. This will make disproportion very small. But in projective space you can hurl a center infinitely far — further away than any point in affine space at all — and the disproportion will disappear completely. So bear in mind, if you want to make a game about zombies who happen to be CAD engineers, you don’t have to implement both kinds of projections. Just set the central projection to and this will automatically turn it into parallel. (x, y, z, 0) Quadrics are by Sam Derbyshire (Own work) [CC BY-SA 3.0 ( )], via Wikimedia Commons http://creativecommons.org/licenses/by-sa/3.0 I remember on my first year in college we were studying quadric surfaces and one of the exercises allegedly made up to help us learn their classification was to make an album. It was 17 sheets of paper with different graphics and formulas sewed together only to be briefly examined by the professor and thrown away a day after. You might imagine we were not fond of this activity. Now in projective space this excercise would have been much more environmental friendly. That’s because in homogenous coordinates all the algebraic surfaces are homogenous too. This means every piece of a polynomial that defines the surface has the same degree. It may contain different variables with different degrees of their own, but they all magically add up to the very same degree for every element in the sum. And this means only one drawing with one formula to be drawn and thrown away and not seventeen. That should sum up to a couple of dead trees through the years. But the most important benefit of homogenous coordinates is about how you do transformations on them. In affine world there are formulas for translation, rotation and scaling. There is more general formula for affine transformation that covers them and add some more like skewing. And there is even more general formula that covers affine transformations as a corner case but introduces projection. In projective world they are not only formulas, but matrices. It’s rather easy really. You want to do a translation. You take and multiply it on the translation matrix. You get this vector in the result: , or . If you transform an euclidean point then and you get the exactly affine translation. (x, y, w) (1 * x + 0 * y + A * w, 0 * x + 1 * y + B * , 0 *x + o * y + 1 * w) (x + Aw, Y + Bw, w) w = 1 But it works even if you don’t. multiplied on the same translation matrix results in . Which shows exactly what translation does to the point out of affine space — nothing! (x, y, 0) (x, y, 0) But what’s even more interesting, all the matrices for translation, rotation, scaling, skewing, affine and projective transformations form the same group in algebraic sense. This means that you can rotate and translate your object as much as you want, you will still get a single projective matrix in the end. It also means that according to the group properties you can actually parallelize your transformation pipeline because of the associativity property. And you can also define an inverse transformation for any number of consequent transformations and it will be a single projective matrix too. So instead of five or six different formulas applied in strict order you have matrices for everything. And you can precalculate and store them conveniently. It’s all that simple! Now let me show you one exercise. Let’s say we don’t have a predefined order of transformations, we just have a result — some 4 points transformed into another 4 points — and you want to get a matrix for that. We have a formula for the transformation, and we have numbers for the corners of singular cube before and after the transformation. What we don’t have is coefficients. . The dilemma here is, even if we write down an every coordinate transformation as a linear equation, and we can do that, there are still more coefficients than equations. Can we really solve this? A, B, C, D, E, F, a, b, c Of course we can. In fact, when we have less equations than variables, it only gets easier, as there are more solutions than 1. We can’t find a single solution, but we can settle with every one of them. In our case this makes total sense as there is not one transformation matrix, but the whole class. Remember, and is the same point in homogenous coordinates. Just as well we can multiply a projective matrix to the scalar and it will still denote the same projection. (1, 1, 1) (2, 2, 2) So among all the matrices that suffice our equations let’s just pick the one which has . Then the system to find all the remaining coefficients will look like this: c = 1 C = x1`F = y1`B + C - x2`b = x2`E + F - y2`b = y2`A + B + C - x3`a - x3`b = x3`D + E + F - y3`a - y3`b = y3`A + C - x4`a = x4`D + F - y4`a = y4` There is a symbolic solution to that, but it’s rather lengthy and not specifically interesting. The main lesson here is: there is a class of projective matrices that do the same transformation, and you can use any of them to get your job done. Here is a selection of other exercises I found useful. You can go through them if you want. I know you wouldn’t though. I’m just playing academics. So here are the points to learn from these exercises written in plain text. Skip them if for some reason you’re eager to do the exercises yourself. Inverse transformation does the trick for 2.1, but you can use the projective transformation equations and do the math yourself. By settling with the solution instead of calculating a fair inverse matrix you basically skip finding a 3x3 determinant. That works roughly 2 times faster than the conventional method. c=1 Inverse transformation works for 2.3 too, but you don’t really have to do even the simplified version, as you only need to determine 6 coefficients and not 9. It takes about two third of projective inversion in terms of performance. But these performance tricks are actually more fun than useful. Usually we lose performance not because some small computational inefficiency, but because of needless layering. And the layering occurs because people don’t understand and don’t trust the beauty of the plain mathematics. I hope this text reveals a bit of it. I hope it makes it more trustworthy. If you liked this, you might also enjoy: _Preface_hackernoon.com Floating point numbers explained with the Walpiri language, big boring tables, and a bit of algebra… _Systems of linear equations are usually taught in high school or college. Chances are, you already know how to solve…_hackernoon.com Programmer’s guide to linear systems