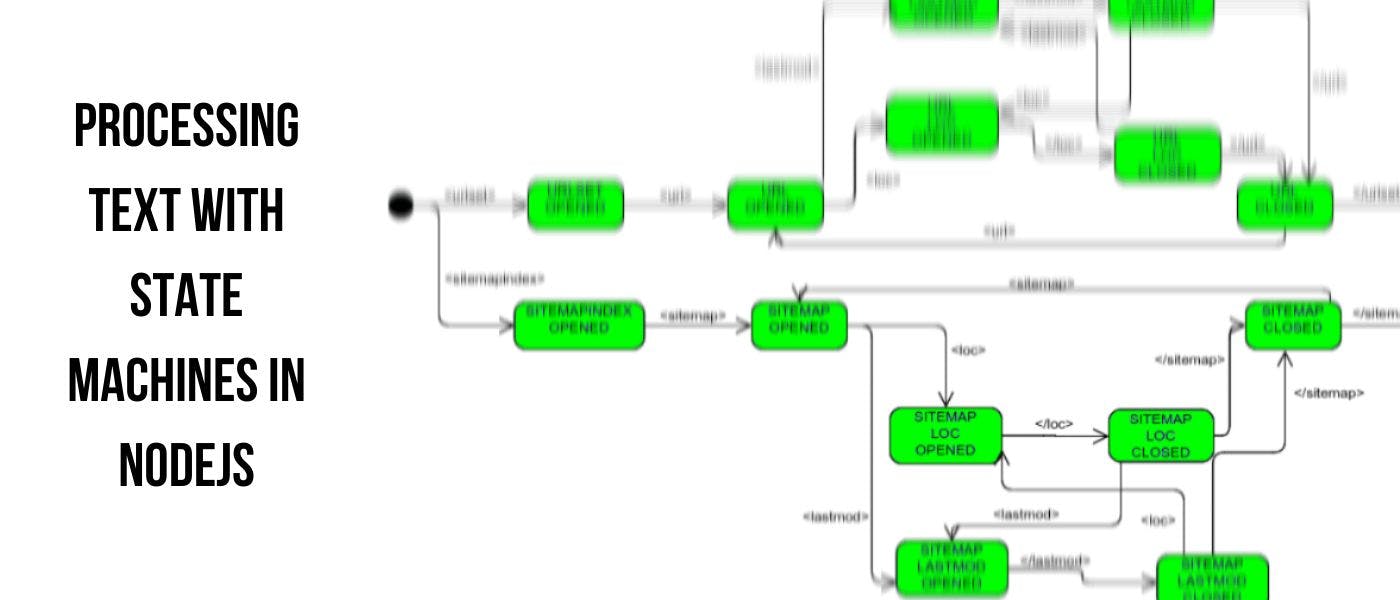
Processing text is a very common problem in computer science. Using state machines or finite automatons (FAs) is a great technique for processing text. This article provides a rough framework for tackling string processing problems. Finite automatons An FA is a mathematical model of computation. An FA has one "start" state, one or more "final" states, and zero or more intermediate states. The only information it stores is its current state. At any point of time during a computation, it does not know how it got to its current state. An FA has a transition function that maps the current state and input token to the next state. You can read more about . FAs on Wikipedia An alternate perspective Implementations of FAs can be simple or complex based on the input string and the problem being solved. Devs often try to use regular expressions or recursive algorithms to tackle problems that would be much simpler with an FA. I have also come across devs who have rejected this technique, finding it "hacky" and "unreliable". This happens because of a lack of knowledge about automata theory. However, it is easy to write programs that use FAs without going deep into the theory. We can think of an FA as an alternate way to structure the program. The program goes through a set of states as it processes the input. Behaviour of the program on the next input token is defined by its current state. The FA "accepts" or "rejects" an input string based on its final state. The sitemap parsing task An example of a string processing task is to parse a sitemap file and extract all the page links . This example is perfect because while the initial problem is simple, it becomes progressively harder as we move towards a more complete sitemap processor. (the contents of the <loc> tags) http://www.example.com/ 2005-01-01 http://www.example.com/catalog?item=12&amp;desc=vacation_hawaii http://www.example.com/catalog?item=73&amp;desc=vacation_new_zealand 2004-12-23 <?xml version="1.0" encoding="UTF-8"?> < = > urlset xmlns "http://www.sitemaps.org/schemas/sitemap/0.9" < > url < > loc </ > loc < > lastmod </ > lastmod </ > url < > url < > loc </ > loc </ > url < > url < > loc </ > loc < > lastmod </ > lastmod </ > url </ > urlset The library will be used for parsing the XML. This parser allows us to hook callbacks which are called whenever an XML tag is opened/closed as the parser processes the input. This makes our task trivial. Think of it as a two-stage parser where the first converts a string into XML tokens and the second converts XML tokens into the required output. htmlparser2 The input for our FA will look like: urlset loc / loc / /urlset url url url url Building an FA This FA can be used to extract all the page links. Our program should save the text content of a tag only when the current state is . LOC_OPENED Another convincing argument in favour of FAs is that it is easy to add new states and transitions to it. If the specification of the input string changes, states can be added or removed from an FA to accommodate those changes. This FA handles the tags as well. <lastmod> Implementation Our FA implementation does not require any extra libraries. A generic hashmap can be used to store the states. .exports = { : { : { : }, }, : { : { : }, }, : { : , : {}, }, : { : { : }, }, : { : { : , : , }, }, : { : { : }, : , }, : { : { : , : , }, }, : { : { : , }, }, : { : { : , : , }, }, }; // sitemapStates.js module START transitions urlset 'URLSET_OPENED' URLSET_OPENED transitions url 'URL_OPENED' URLSET_CLOSED final true transitions URL_OPENED transitions loc 'LOC_OPENED' URL_CLOSED transitions '/urlset' 'URLSET_CLOSED' url 'URL_OPENED' LOC_OPENED transitions '/loc' 'LOC_CLOSED' extractText true LOC_CLOSED transitions '/url' 'URL_CLOSED' lastmod 'LASTMOD_OPENED' LASTMOD_OPENED transitions '/lastmod' 'LASTMOD_CLOSED' LASTMOD_CLOSED transitions '/url' 'URL_CLOSED' loc 'LOC_OPENED' fs = ( ); htmlparser2 = ( ); sitemapStates = ( ); { state = sitemapStates.START; pageLinks = []; { nextStateName = state.transitions[name]; (nextStateName === ) ( ); state = sitemapStates[nextStateName]; } { tagWithWithSlash = ; nextStateName = state.transitions[tagWithWithSlash]; (nextStateName === ) ( ); state = sitemapStates[nextStateName]; } { (state.extractText) pageLinks.push(text); } parser = htmlparser2.Parser({ : onOpenTag, : onCloseTag, : onText, }); parser.write(sitemapBuffer); (!state.final) ( ); pageLinks; } fs.promises.readFile( ) .then(parseSitemap) .then( .log); // index.js const require 'fs' const require 'htmlparser2' const require './sitemapStates' ( ) function parseSitemap sitemapBuffer let const ( ) function onOpenTag name const if undefined throw new Error 'Failed to process input' ( ) function onCloseTag name const `/ ` ${name} const if undefined throw new Error 'Failed to process input' ( ) function onText text if const new onopentag onclosetag ontext if throw new Error 'Failed to process input' return 'sitemap.xml' console Running this will output: [ , , ] 'http://www.example.com/' 'http://www.example.com/catalog?item=12&amp;desc=vacation_hawaii' 'http://www.example.com/catalog?item=73&amp;desc=vacation_new_zealand' Getting real A sitemap file has a lot more than what we've dealt with till now. One sitemap file can link to other sitemap files as well. You can read more about the sitemap protocol on . sitemaps.org A sitemap file can either be a simple sitemap file: http://www.example.com/ 2005-01-01 http://www.example.com/catalog?item=12&amp;desc=vacation_hawaii http://www.example.com/catalog?item=73&amp;desc=vacation_new_zealand 2004-12-23 <?xml version="1.0" encoding="UTF-8"?> < = > urlset xmlns "http://www.sitemaps.org/schemas/sitemap/0.9" < > url < > loc </ > loc < > lastmod </ > lastmod </ > url < > url < > loc </ > loc </ > url < > url < > loc </ > loc < > lastmod </ > lastmod </ > url </ > urlset or a sitemap index file that links to other sitemaps: http://www.example.com/sitemap1.xml.gz 2004-10-01T18:23:17+00:00 http://www.example.com/sitemap2.xml.gz 2005-01-01 <?xml version="1.0" encoding="UTF-8"?> < = > sitemapindex xmlns "http://www.sitemaps.org/schemas/sitemap/0.9" < > sitemap < > loc </ > loc < > lastmod </ > lastmod </ > sitemap < > sitemap < > loc </ > loc < > lastmod </ > lastmod </ > sitemap </ > sitemapindex FAs that can handle this can be constructed easily. Please note that the sitemap spec defines two more tags <changefreq> and <priority> that we've omitted from our example. Learning more I hope this article provides a gist of how FAs can be used. Remember that while finite automatons look simple, also exist. These are required for more complex parsing tasks . more powerful automatons (for example: saving the text of the <loc> tags only when the date in <lastmod> is later than a given date) is a great resource for learning more about automata theory. This course on edX