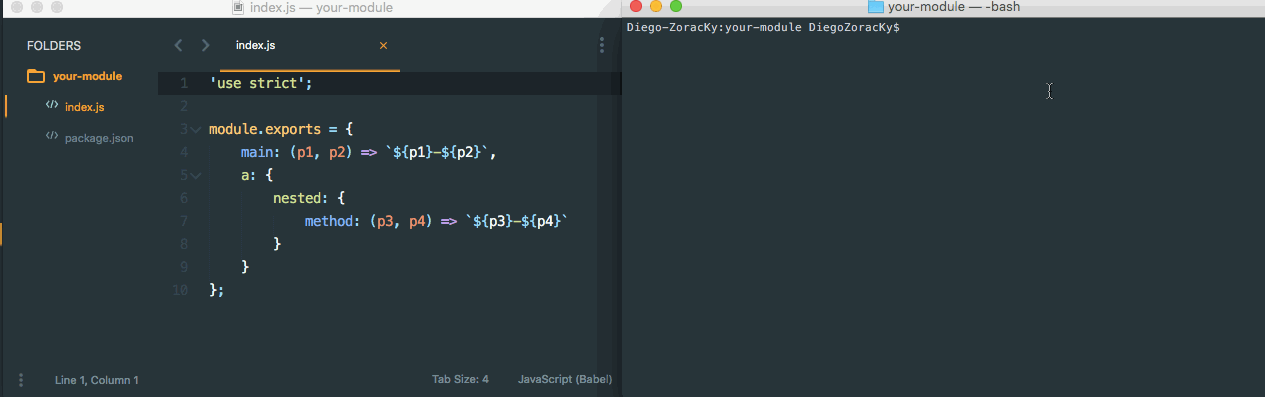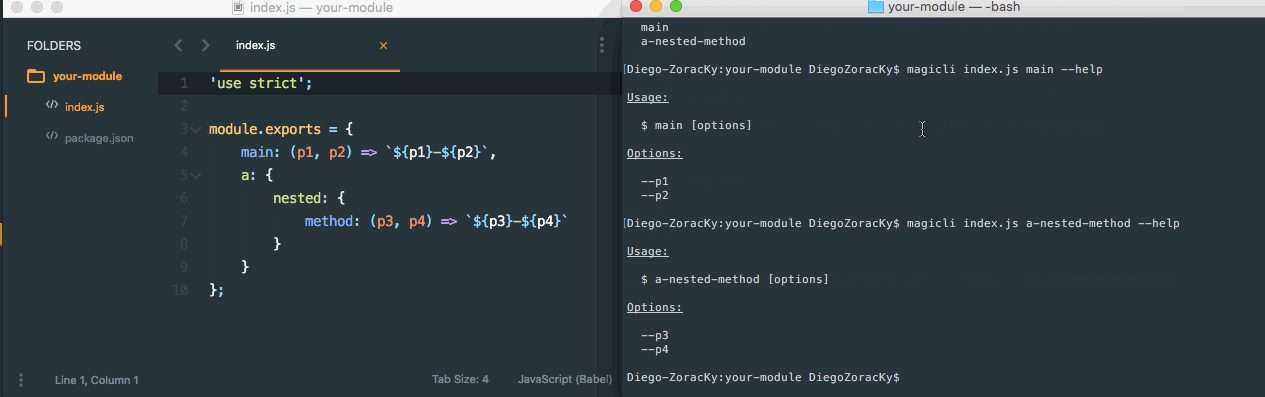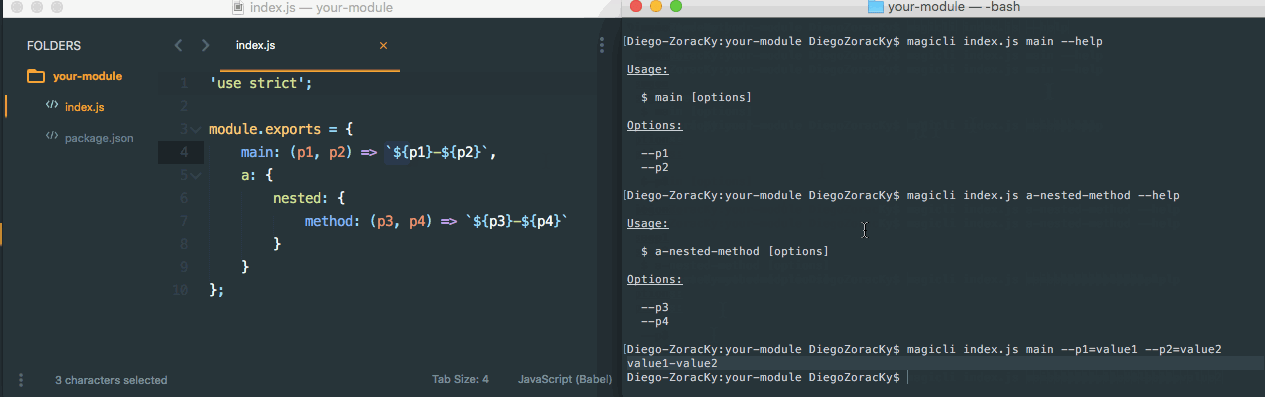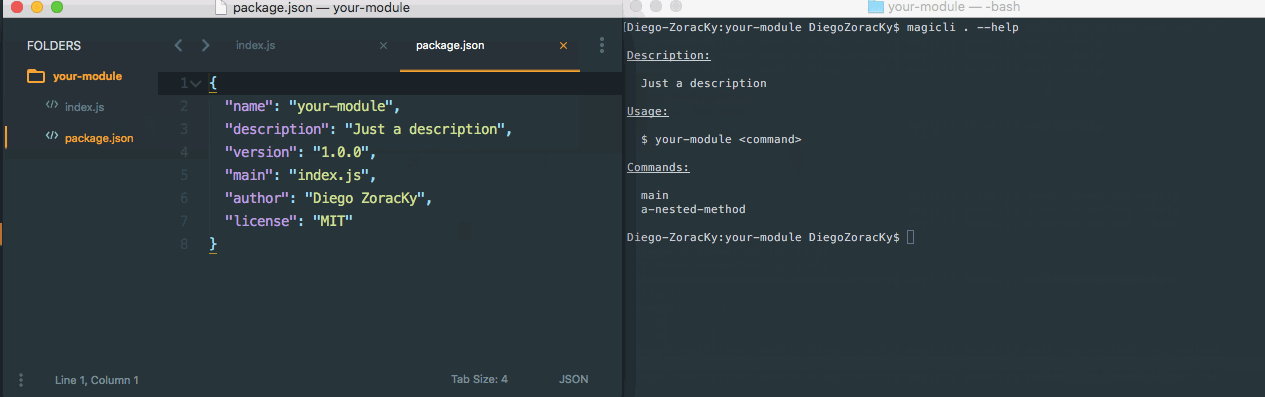
One AWS Lambda. All services via SDK Recently while designing a Step Function to perform ETL jobs, to train Machine Learning models and perform batch predictions, a pattern (as described at example) took its place. Due to the async nature of some of the involved services, like Glue and SageMaker, some steps would need to wait for a job to be completed before moving on to the next phase of the pipeline. Wait-Check Job Status Poller Job Status Poller Sample However, in the case, there were six of that in the pipeline. Which means six snippets of code to be written, to do the same thing. Yes, at first, thinking of the goals of the different steps, they seem to be different. The services and its methods to be called won’t be the same. But in the end, they all share a same pattern, which is: Call a method from a service with the following parameters and get its result . So, having that in mind, I’ve created a common to call any service via AWS SDK. Its source and documentation can be found here: Lambda AWS https://github.com/DiegoZoracKy/lambda-aws-sdk-call A bit of . The (a concept I truly believe in) from can tell something about what was applied here. Unix Philosophy Rule of Generation Eric Raymond’s 17 Unix Rule Rule of Generation Developers should and instead that generate code. This rule aims . avoid writing code by hand write abstract high-level programs to reduce human errors and save time I hope it can be helpful for others, and also, any feedback is welcome. Soon I’ll be posting a new article where I show how this generic Lambda can be used on Step Functions to trigger jobs and to wait for them to be completed. Update 2018-09-26: Based on a comment a user sent me on Reddit, regarding security and the least-privilege principle, I realized that other people could end up seeing only one way to apply what is being presented here. Being in the same as he saw it (one Lambda with all the privileges to be used at the whole company), that wouldn’t be the best way and could lead to those same concerns. First, one thing is the source code of a Lambda and the other one is the Lambda itself. You can have different Lambdas, with different privileges, but all having a same source code. At the case I mentioned, a Step Function would need to interact with 2 different services in at least 6 different ways. In any way some Lambdas will need to exist with the right privileges to handle those interactions. Given that scenario, you can have: A) 6 Lambdas, with 6 different source codes, where each of them have the right privileges. B) 6 Lambdas, with 1 source code (the same for all), where each of them have the right privileges. C) 1 Lambda, 1 source code, having only the same privileges that would have been given in any of the aforementioned cases (not full-access to everything). From a security point of view, there will be in any way 6 actions to be performed via Lambdas. Whether it is via six different lambdas or through only one. The last strategy even seems to be easier to be managed. Some benefits of going with the last case would be: The team doesn’t have to stop and write new code. That saves time, which is important, but more than that, it prevents new bugs to be born. Only one code to be tested and to be guaranteed that it works as expected. Less error-prone. Less room for bugs and unexpected behaviors. An uniform contract. Given that all calls shares the same structure for its input and output. This last one was really useful for our team, especially on the Step Function case. It gives us freedom to implement an entire pipeline having only to pay attention to our input and output data sequences, without worrying about the behavior of the resources being called.