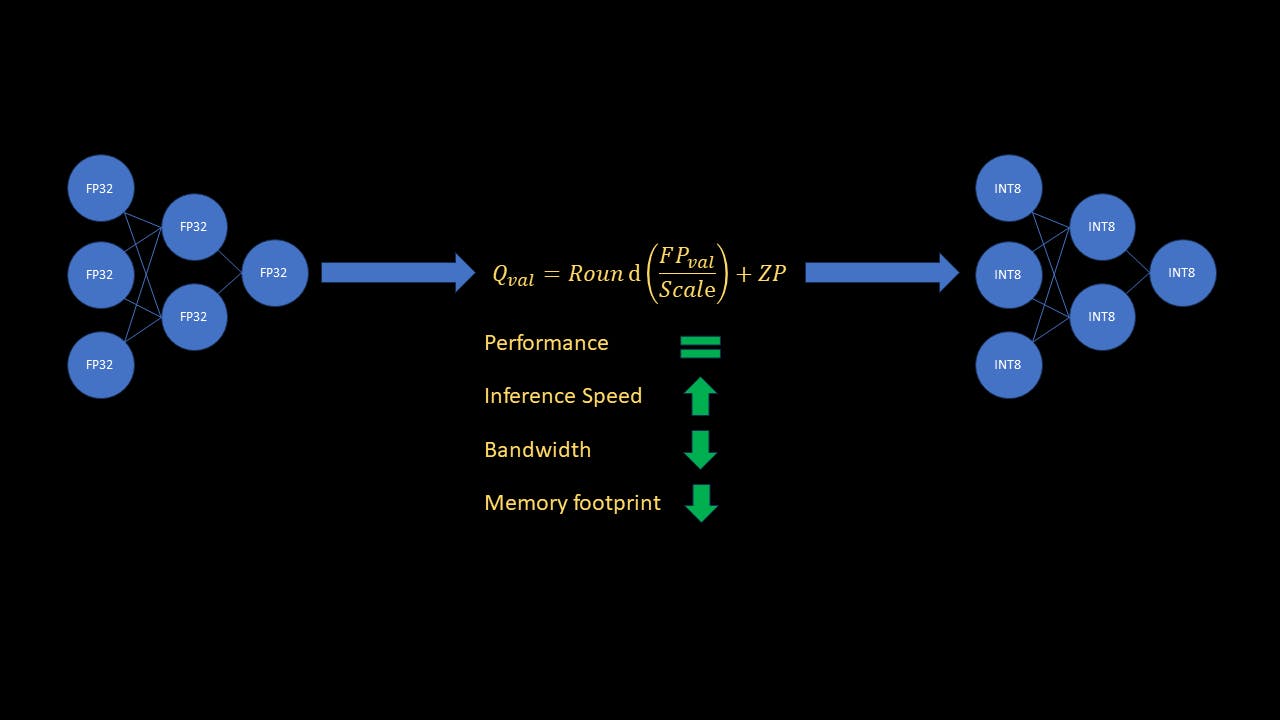
您是否知道在机器学习领域,深度学习 (DL) 模型的效率可以通过一种称为量化的技术显着提高?想象一下在不牺牲神经网络性能的情况下减少神经网络的计算负担。就像压缩大文件而不丢失其本质一样,模型量化可以让您的模型更小、更快。让我们深入探讨令人着迷的量化概念,并揭开优化神经网络以进行实际部署的秘密。 在我们深入研究之前,读者应该熟悉神经网络和量化的基本概念,包括术语尺度(S)和零点(ZP)。对于想要复习的读者, 和 解释了量化的广泛概念和类型。 本文 本文 在本指南中,我将简要解释为什么量化很重要,以及如何使用 Pytorch 实现它。我将主要关注称为“训练后静态量化”的量化类型,它使 ML 模型的内存占用减少 4 倍,并使推理速度提高 4 倍。 概念 为什么量化很重要? 神经网络计算最常使用 32 位浮点数执行。单个 32 位浮点数 (FP32) 需要 4 字节内存。相比之下,单个 8 位整数 (INT8) 仅需要 1 个字节的内存。此外,计算机处理整数运算比浮点运算快得多。您立即可以看到,将 ML 模型从 FP32 量化为 INT8 将导致内存减少 4 倍。此外,它还将推理速度提高 4 倍!随着大型模型现在风靡一时,对于从业者来说,能够优化训练模型的内存和速度以实现实时推理非常重要。 关键术语 训练过的神经网络的权重。 权重 - 就量化而言,激活不是 Sigmoid 或 ReLU 等激活函数。我所说的激活是指中间层的特征图输出,它们是下一层的输入。 激活—— 训练后静态量化 训练后静态量化意味着我们在训练原始模型后不需要训练或微调模型进行量化。我们也不需要量化中间层输入,称为动态激活。在这种量化模式中,通过计算每层的尺度和零点来直接量化权重。然而,对于激活而言,随着模型输入的变化,激活也会发生变化。我们不知道模型在推理过程中遇到的每个输入的范围。那么我们如何计算网络所有激活的尺度和零点呢? 我们可以通过使用良好的代表性数据集校准模型来做到这一点。然后,我们观察校准集的激活值范围,然后使用这些统计数据来计算比例和零点。这是通过在模型中插入观察者来完成的,观察者在校准期间收集数据统计数据。准备好模型(插入观察者)后,我们在校准数据集上运行模型的前向传播。观察者使用该校准数据来计算激活的比例和零点。现在推理只需将线性变换应用于具有各自比例和零点的所有层。 虽然整个推理是在 INT8 中完成的,但最终模型输出是反量化的(从 INT8 到 FP32)。 如果输入和网络权重已经量化,为什么还需要量化激活? 这是一个很好的问题。虽然网络输入和权重确实已经是 INT8 值,但该层的输出存储为 INT32,以避免溢出。为了降低处理下一层的复杂性,激活从 INT32 量化为 INT8。 概念清楚后,让我们深入研究代码,看看它是如何工作的! 对于此示例,我将使用在 Flowers102 数据集上微调的 resnet18 模型,该模型可直接在 Pytorch 中使用。但是,该代码适用于任何训练有素的 CNN,并具有适当的校准数据集。由于本教程的重点是量化,因此我不会介绍训练和微调部分。不过,所有代码都可以 找到。让我们潜入吧! 在这里 量化码 让我们导入量化所需的库并加载微调模型。 import torch import torchvision import torchvision.transforms as transforms from torchvision.models import resnet18 import torch.nn as nn from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping import warnings warnings.filterwarnings('ignore') 接下来,让我们定义一些参数,定义数据转换和数据加载器,并加载微调后的模型 model_path = 'flowers_model.pth' quantized_model_save_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) # Define train data loader, for using as calibration set trainset = torchvision.datasets.Flowers102(root='./data', split="train", download=True, transform=transform) trainLoader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2) # Load the finetuned resnet model model_to_quantize = resnet18(weights=None) num_features = model_to_quantize.fc.in_features model_to_quantize.fc = nn.Linear(num_features, num_classes) model_to_quantize.load_state_dict(torch.load(model_path)) model_to_quantize.eval() print('Loaded fine-tuned model') 对于这个例子,我将使用一些训练样本作为校准集。 现在,让我们定义用于量化模型的配置。 # Define quantization parameters config for the correct platform, # "x86" for x86 devices or "qnnpack" for arm devices qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) 在上面的代码片段中,我使用了默认配置,但 Pytorch 的 类用于描述模型或模型的一部分应如何量化。我们可以通过指定用于权重和激活的观察者类的类型来做到这一点。 QConfig 我们现在准备好量化模型 # Fuse conv-> relu, conv -> bn -> relu layer blocks and insert observers model_prep = prepare_fx(model=model_to_quantize, qconfig_mapping=qconfig_mapping, example_inputs=torch.randn((1,3,224,224))) 函数将观察者插入到模型中,并且还融合了conv→relu和conv→bn→relu模块。由于不需要存储这些模块的中间结果,这会导致更少的操作和更低的内存带宽。 prepare_fx 通过对校准数据进行前向传递来校准模型 # Run calibration for 10 batches (100 random samples in total) print('Running calibration') with torch.no_grad(): for i, data in enumerate(trainLoader): samples, labels = data _ = model_prep(samples) if i == 10: break 我们不需要对整个训练集进行校准!在此示例中,我使用 100 个随机样本,但实际上,您应该选择一个代表模型在部署期间将看到的数据集。 量化模型并保存量化权重! # Quantize calibrated model quantized_model = convert_fx(model_prep) print('Quantized model!') # Save quantized torch.save(quantized_model.state_dict(), quantized_model_save_path) print('Saved quantized model weights to disk') 就是这样!现在让我们看看如何加载量化模型,然后比较原始模型和量化模型的准确性、速度和内存占用。 加载量化模型 量化模型图与原始模型并不完全相同,即使两者具有相同的层。 打印两个模型的第一层 ( ) 显示出差异。 conv1 print('\nPrinting conv1 layer of fp32 and quantized model') print(f'fp32 model: {model_to_quantize.conv1}') print(f'quantized model: {quantized_model.conv1}') 您会注意到,除了不同的类之外,量化模型的 conv1 层还包含尺度和零点参数。 因此,我们需要按照量化过程(无需校准)创建模型图,然后加载量化权重。当然,如果我们将量化模型保存为 onnx 格式,我们可以像任何其他 onnx 模型一样加载它,而无需每次都运行量化函数。 同时,让我们定义一个用于加载量化模型的函数并将其保存到 。 inference_utils.py import torch from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping def load_quantized_model(model_to_quantize, weights_path): ''' Model only needs to be calibrated for the first time. Next time onwards, to load the quantized model, you still need to prepare and convert the model without calibrating it. After that, load the state dict as usual. ''' model_to_quantize.eval() qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) model_prep = prepare_fx(model_to_quantize, qconfig_mapping, torch.randn((1,3,224,224))) quantized_model = convert_fx(model_prep) quantized_model.load_state_dict(torch.load(weights_path)) return quantized_model 定义测量精度和速度的函数 测量精度 import torch def test_accuracy(model, testLoader): model.eval() running_acc = 0 num_samples = 0 with torch.no_grad(): for i, data in enumerate(testLoader): samples, labels = data outputs = model(samples) preds = torch.argmax(outputs, 1) running_acc += torch.sum(preds == labels) num_samples += samples.size(0) return running_acc / num_samples 这是一个非常简单的 Pytorch 代码。 测量推理速度(以毫秒 (ms) 为单位) import torch from time import time def test_speed(model): dummy_sample = torch.randn((1,3,224,224)) # Average out inference speed over multiple iterations # to get a true estimate num_iterations = 100 start = time() for _ in range(num_iterations): _ = model(dummy_sample) end = time() return (end-start)/num_iterations * 1000 在 中添加这两个函数。我们现在准备比较模型。让我们看一下代码。 inference_utils.py 比较模型的准确性、速度和尺寸 让我们首先导入必要的库、定义参数、数据转换和测试数据加载器。 import os import torch import torch.nn as nn import torchvision from torchvision.models import resnet18 import torchvision.transforms as transforms from inference_utils import test_accuracy, test_speed, load_quantized_model import copy import warnings warnings.filterwarnings('ignore') model_weights_path = 'flowers_model.pth' quantized_model_weights_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) testset = torchvision.datasets.Flowers102(root='./data', split="test", download=True, transform=transform) testLoader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2) 加载两个模型 # Load the finetuned resnet model and the quantized model model = resnet18(weights=None) num_features = model.fc.in_features model.fc = nn.Linear(num_features, num_classes) model.load_state_dict(torch.load(model_weights_path)) model.eval() model_to_quantize = copy.deepcopy(model) quantized_model = load_quantized_model(model_to_quantize, quantized_model_weights_path) 比较型号 # Compare accuracy fp32_accuracy = test_accuracy(model, testLoader) accuracy = test_accuracy(quantized_model, testLoader) print(f'Original model accuracy: {fp32_accuracy:.3f}') print(f'Quantized model accuracy: {accuracy:.3f}\n') # Compare speed fp32_speed = test_speed(model) quantized_speed = test_speed(quantized_model) print(f'Inference time for original model: {fp32_speed:.3f} ms') print(f'Inference time for quantized model: {quantized_speed:.3f} ms\n') # Compare file size fp32_size = os.path.getsize(model_weights_path)/10**6 quantized_size = os.path.getsize(quantized_model_weights_path)/10**6 print(f'Original model file size: {fp32_size:.3f} MB') print(f'Quantized model file size: {quantized_size:.3f} MB') 结果 可以看到,量化模型在测试数据上的准确率几乎和原始模型的准确率一样高!量化模型的推理速度快了约 3.6 倍 (!),并且量化模型所需的内存比原始模型少约 4 倍! 结论 在本文中,我们了解了 ML 模型量化的广泛概念,以及一种称为训练后静态量化的量化类型。我们还研究了为什么量化在大型模型时代很重要并且是一个强大的工具。最后,我们通过示例代码使用 Pytorch 量化经过训练的模型,并审查了结果。结果表明,量化原始模型不会影响性能,同时推理速度降低了约 3.6 倍,内存占用降低了约 4 倍! 需要注意的几点 - 静态量化对于 CNN 效果很好,但动态量化是序列模型的首选方法。此外,如果量化极大地影响模型性能,则可以通过称为量化感知训练 (QAT) 的技术来恢复准确性。 动态量化和 QAT 如何工作?这些是另一次的帖子。我希望通过本指南,您能够了解在自己的 Pytorch 模型上执行静态量化的知识。 参考 模型量化基础知识 张量量化 花 102 数据集 Pytorch 文档