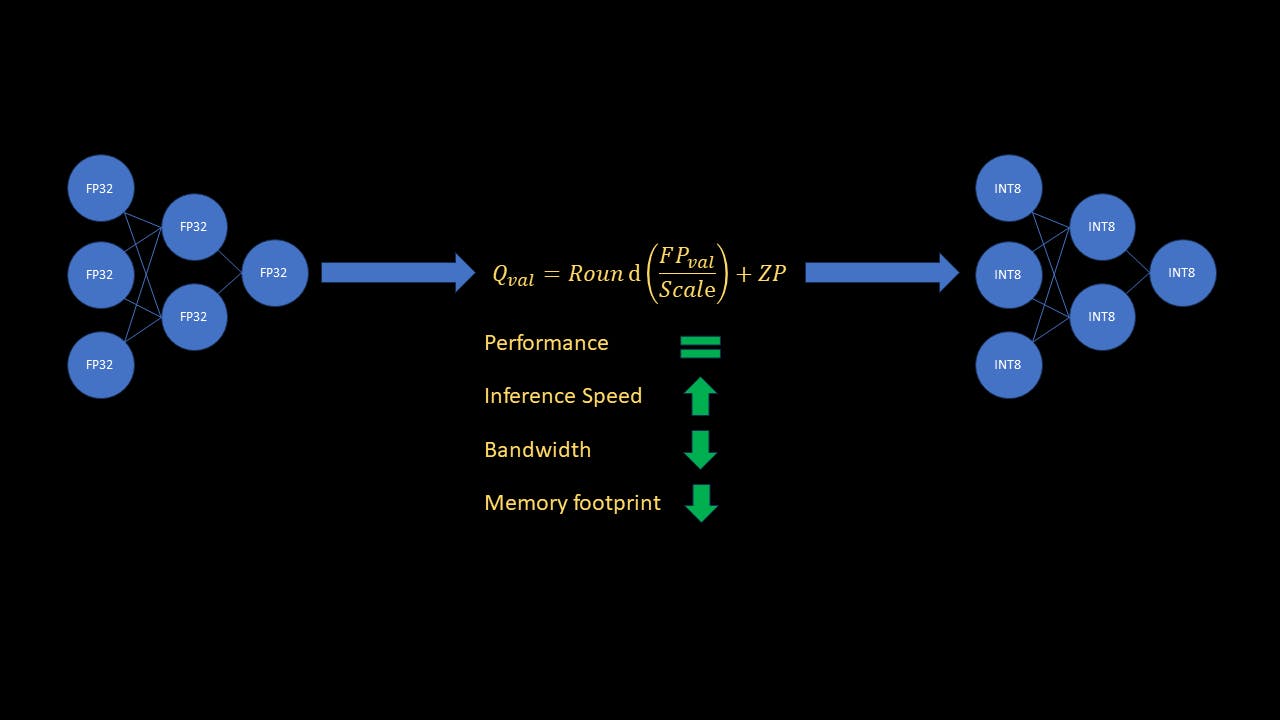
기계 학습의 세계에서 양자화라는 기술을 통해 딥 러닝(DL) 모델의 효율성이 크게 향상될 수 있다는 사실을 알고 계셨습니까? 성능을 저하시키지 않고 신경망의 계산 부담을 줄이는 것을 상상해 보십시오. 본질을 잃지 않고 대용량 파일을 압축하는 것처럼 모델 양자화를 사용하면 모델을 더 작고 빠르게 만들 수 있습니다. 양자화의 매혹적인 개념에 대해 자세히 알아보고 실제 배포를 위해 신경망을 최적화하는 비결을 알아보세요. 더 자세히 살펴보기 전에 독자는 스케일(S) 및 영점(ZP)이라는 용어를 포함하여 신경망과 양자화의 기본 개념에 대해 잘 알고 있어야 합니다. 복습을 원하는 독자를 위해 와 양자화의 광범위한 개념과 유형을 설명합니다. 이 기사 이 기사에서는 이 가이드에서는 양자화가 중요한 이유와 Pytorch를 사용하여 이를 구현하는 방법을 간략하게 설명합니다. 저는 주로 "훈련 후 정적 양자화"라는 양자화 유형에 초점을 맞추겠습니다. 이 양자화는 ML 모델의 메모리 공간을 4배 줄이고 추론을 최대 4배 빠르게 만듭니다. 개념 양자화가 왜 중요합니까? 신경망 계산은 가장 일반적으로 32비트 부동 소수점 숫자로 수행됩니다. 단일 32비트 부동 소수점 수(FP32)에는 4바이트의 메모리가 필요합니다. 이에 비해 단일 8비트 정수(INT8)에는 1바이트의 메모리만 필요합니다. 또한 컴퓨터는 부동 연산보다 정수 연산을 훨씬 빠르게 처리합니다. ML 모델을 FP32에서 INT8로 양자화하면 메모리가 4배 줄어드는 것을 바로 확인할 수 있습니다. 또한 추론 속도도 최대 4배 향상됩니다! 현재 대규모 모델이 대유행하고 있는 상황에서 실무자는 훈련된 모델을 실시간 추론을 위한 메모리 및 속도에 최적화할 수 있는 것이 중요합니다. 핵심 용어 훈련된 신경망의 가중치입니다. 가중치 - 양자화 측면에서 활성화는 Sigmoid 또는 ReLU와 같은 활성화 함수가 아닙니다. 활성화란 다음 레이어의 입력인 중간 레이어의 기능 맵 출력을 의미합니다. 활성화 - 훈련 후 정적 양자화 훈련 후 정적 양자화는 원래 모델을 훈련한 후 양자화를 위해 모델을 훈련하거나 미세 조정할 필요가 없음을 의미합니다. 또한 즉시 활성화라고 불리는 중간 계층 입력을 양자화할 필요도 없습니다. 이 양자화 모드에서는 각 레이어의 스케일과 영점을 계산하여 가중치를 직접 양자화합니다. 그러나 활성화의 경우 모델에 대한 입력이 변경되면 활성화도 변경됩니다. 우리는 추론 중에 모델이 접하게 될 각각의 모든 입력의 범위를 알 수 없습니다. 그렇다면 네트워크의 모든 활성화에 대한 스케일과 영점을 어떻게 계산할 수 있습니까? 이는 좋은 대표 데이터 세트를 사용하여 모델을 보정함으로써 수행할 수 있습니다. 그런 다음 교정 세트에 대한 활성화 값의 범위를 관찰한 다음 해당 통계를 사용하여 스케일과 영점을 계산합니다. 이는 교정 중에 데이터 통계를 수집하는 관찰자를 모델에 삽입하여 수행됩니다. 모델을 준비한 후(관찰자 삽입) 교정 데이터세트에서 모델의 순방향 전달을 실행합니다. 관찰자는 이 교정 데이터를 사용하여 활성화를 위한 척도와 영점을 계산합니다. 이제 추론은 각각의 스케일과 영점을 사용하여 모든 레이어에 선형 변환을 적용하는 문제일 뿐입니다. 전체 추론이 INT8에서 수행되는 동안 최종 모델 출력은 역양자화됩니다(INT8에서 FP32로). 입력 및 네트워크 가중치가 이미 양자화되어 있는데 활성화를 양자화해야 하는 이유는 무엇입니까? 이것은 훌륭한 질문입니다. 네트워크 입력과 가중치는 이미 INT8 값이지만, 오버플로를 방지하기 위해 레이어의 출력은 INT32로 저장됩니다. 다음 레이어 처리의 복잡성을 줄이기 위해 활성화는 INT32에서 INT8로 양자화됩니다. 개념이 명확해졌으니 코드를 자세히 살펴보고 작동 방식을 살펴보겠습니다. 이 예에서는 Pytorch에서 직접 사용할 수 있는 Flowers102 데이터 세트에서 미세 조정된 resnet18 모델을 사용하겠습니다. 그러나 코드는 적절한 교정 데이터 세트를 사용하여 훈련된 모든 CNN에서 작동합니다. 이 튜토리얼은 양자화에 중점을 두고 있으므로 학습 및 미세 조정 부분은 다루지 않겠습니다. 그러나 모든 코드는 찾을 수 있습니다. 다이빙하자! 여기에서 양자화 코드 양자화에 필요한 라이브러리를 가져오고 미세 조정된 모델을 로드하겠습니다. import torch import torchvision import torchvision.transforms as transforms from torchvision.models import resnet18 import torch.nn as nn from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping import warnings warnings.filterwarnings('ignore') 다음으로 몇 가지 매개변수를 정의하고, 데이터 변환 및 데이터 로더를 정의하고, 미세 조정된 모델을 로드하겠습니다. model_path = 'flowers_model.pth' quantized_model_save_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) # Define train data loader, for using as calibration set trainset = torchvision.datasets.Flowers102(root='./data', split="train", download=True, transform=transform) trainLoader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2) # Load the finetuned resnet model model_to_quantize = resnet18(weights=None) num_features = model_to_quantize.fc.in_features model_to_quantize.fc = nn.Linear(num_features, num_classes) model_to_quantize.load_state_dict(torch.load(model_path)) model_to_quantize.eval() print('Loaded fine-tuned model') 이 예에서는 일부 훈련 샘플을 교정 세트로 사용하겠습니다. 이제 모델을 양자화하는 데 사용되는 구성을 정의하겠습니다. # Define quantization parameters config for the correct platform, # "x86" for x86 devices or "qnnpack" for arm devices qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) 위의 코드 조각에서는 기본 구성을 사용했지만 Pytorch의 클래스는 모델 또는 모델의 일부를 양자화하는 방법을 설명하는 데 사용됩니다. 가중치와 활성화에 사용할 관찰자 클래스 유형을 지정하여 이를 수행할 수 있습니다. QConfig 이제 양자화를 위한 모델을 준비할 준비가 되었습니다. # Fuse conv-> relu, conv -> bn -> relu layer blocks and insert observers model_prep = prepare_fx(model=model_to_quantize, qconfig_mapping=qconfig_mapping, example_inputs=torch.randn((1,3,224,224))) 함수는 관찰자를 모델에 삽입하고, 또한 CNN→relu 및 conv→bn→relu 모듈을 융합합니다. 이로 인해 해당 모듈의 중간 결과를 저장할 필요가 없기 때문에 작업이 줄어들고 메모리 대역폭이 낮아집니다. prepare_fx 교정 데이터에 대해 정방향 전달을 실행하여 모델 교정 # Run calibration for 10 batches (100 random samples in total) print('Running calibration') with torch.no_grad(): for i, data in enumerate(trainLoader): samples, labels = data _ = model_prep(samples) if i == 10: break 전체 훈련 세트에 대해 교정을 실행할 필요가 없습니다! 이 예에서는 100개의 무작위 샘플을 사용하지만 실제로는 배포 중에 모델이 보게 될 내용을 대표하는 데이터 세트를 선택해야 합니다. 모델을 양자화하고 양자화된 가중치를 저장하세요! # Quantize calibrated model quantized_model = convert_fx(model_prep) print('Quantized model!') # Save quantized torch.save(quantized_model.state_dict(), quantized_model_save_path) print('Saved quantized model weights to disk') 그리고 그게 다야! 이제 양자화된 모델을 로드하는 방법을 살펴보고 원본 모델과 양자화된 모델의 정확도, 속도 및 메모리 공간을 비교해 보겠습니다. 양자화된 모델 로드 양자화된 모델 그래프는 원래 모델과 완전히 동일하지 않습니다. 둘 다 동일한 레이어를 가지고 있더라도 마찬가지입니다. 두 모델의 첫 번째 레이어( )를 인쇄하면 차이점이 나타납니다. conv1 print('\nPrinting conv1 layer of fp32 and quantized model') print(f'fp32 model: {model_to_quantize.conv1}') print(f'quantized model: {quantized_model.conv1}') 다른 클래스와 함께 양자화 모델의 CNN 레이어에도 스케일 및 영점 매개변수가 포함되어 있음을 알 수 있습니다. 따라서 우리가 해야 할 일은 양자화 프로세스(교정 없이)를 따라 모델 그래프를 생성한 다음 양자화된 가중치를 로드하는 것입니다. 물론, 양자화된 모델을 onnx 형식으로 저장하면 매번 양자화 함수를 실행하지 않고도 다른 onnx 모델처럼 로드할 수 있습니다. 그동안 양자화된 모델을 로드하는 함수를 정의하고 이를 에 저장해 보겠습니다. inference_utils.py import torch from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping def load_quantized_model(model_to_quantize, weights_path): ''' Model only needs to be calibrated for the first time. Next time onwards, to load the quantized model, you still need to prepare and convert the model without calibrating it. After that, load the state dict as usual. ''' model_to_quantize.eval() qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) model_prep = prepare_fx(model_to_quantize, qconfig_mapping, torch.randn((1,3,224,224))) quantized_model = convert_fx(model_prep) quantized_model.load_state_dict(torch.load(weights_path)) return quantized_model 정확도와 속도 측정을 위한 기능 정의 정확도 측정 import torch def test_accuracy(model, testLoader): model.eval() running_acc = 0 num_samples = 0 with torch.no_grad(): for i, data in enumerate(testLoader): samples, labels = data outputs = model(samples) preds = torch.argmax(outputs, 1) running_acc += torch.sum(preds == labels) num_samples += samples.size(0) return running_acc / num_samples 이것은 매우 간단한 Pytorch 코드입니다. 추론 속도를 밀리초(ms) 단위로 측정합니다. import torch from time import time def test_speed(model): dummy_sample = torch.randn((1,3,224,224)) # Average out inference speed over multiple iterations # to get a true estimate num_iterations = 100 start = time() for _ in range(num_iterations): _ = model(dummy_sample) end = time() return (end-start)/num_iterations * 1000 에 이 두 함수를 모두 추가하세요. 이제 모델을 비교할 준비가 되었습니다. 코드를 살펴보겠습니다. inference_utils.py 모델의 정확성, 속도, 크기 비교 먼저 필요한 라이브러리를 가져오고 매개변수, 데이터 변환 및 테스트 데이터로더를 정의하겠습니다. import os import torch import torch.nn as nn import torchvision from torchvision.models import resnet18 import torchvision.transforms as transforms from inference_utils import test_accuracy, test_speed, load_quantized_model import copy import warnings warnings.filterwarnings('ignore') model_weights_path = 'flowers_model.pth' quantized_model_weights_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) testset = torchvision.datasets.Flowers102(root='./data', split="test", download=True, transform=transform) testLoader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2) 두 모델 로드 # Load the finetuned resnet model and the quantized model model = resnet18(weights=None) num_features = model.fc.in_features model.fc = nn.Linear(num_features, num_classes) model.load_state_dict(torch.load(model_weights_path)) model.eval() model_to_quantize = copy.deepcopy(model) quantized_model = load_quantized_model(model_to_quantize, quantized_model_weights_path) 모델 비교 # Compare accuracy fp32_accuracy = test_accuracy(model, testLoader) accuracy = test_accuracy(quantized_model, testLoader) print(f'Original model accuracy: {fp32_accuracy:.3f}') print(f'Quantized model accuracy: {accuracy:.3f}\n') # Compare speed fp32_speed = test_speed(model) quantized_speed = test_speed(quantized_model) print(f'Inference time for original model: {fp32_speed:.3f} ms') print(f'Inference time for quantized model: {quantized_speed:.3f} ms\n') # Compare file size fp32_size = os.path.getsize(model_weights_path)/10**6 quantized_size = os.path.getsize(quantized_model_weights_path)/10**6 print(f'Original model file size: {fp32_size:.3f} MB') print(f'Quantized model file size: {quantized_size:.3f} MB') 결과 보시다시피, 테스트 데이터에 대한 양자화된 모델의 정확도는 원본 모델의 정확도와 거의 같습니다! 양자화된 모델의 추론은 ~3.6배 더 빠르며(!) 양자화된 모델은 원래 모델보다 ~4배 더 적은 메모리를 필요로 합니다! 결론 이 기사에서는 ML 모델 양자화의 광범위한 개념과 사후 훈련 정적 양자화라는 양자화 유형을 이해했습니다. 또한 대형 모델 시대에 양자화가 왜 중요하고 강력한 도구인지 살펴보았습니다. 마지막으로, Pytorch를 사용하여 훈련된 모델을 양자화하는 예제 코드를 살펴보고 결과를 검토했습니다. 결과에서 알 수 있듯이 원래 모델을 양자화해도 성능에 영향을 미치지 않았으며 동시에 추론 속도가 ~3.6배 감소하고 메모리 사용량이 ~4배 감소했습니다! 몇 가지 참고 사항 - 정적 양자화는 CNN에 적합하지만 동적 양자화는 시퀀스 모델에 선호되는 방법입니다. 또한 양자화가 모델 성능에 큰 영향을 미치는 경우 QAT(양자화 인식 훈련)라는 기술을 통해 정확도를 회복할 수 있습니다. 동적 양자화와 QAT는 어떻게 작동하나요? 그것은 다른 시간에 대한 게시물입니다. 이 가이드를 통해 귀하가 자신의 Pytorch 모델에서 정적 양자화를 수행하는 데 필요한 지식을 얻을 수 있기를 바랍니다. 참고자료 모델 양자화의 기초 텐서 양자화 꽃 102 데이터세트 파이토치 문서