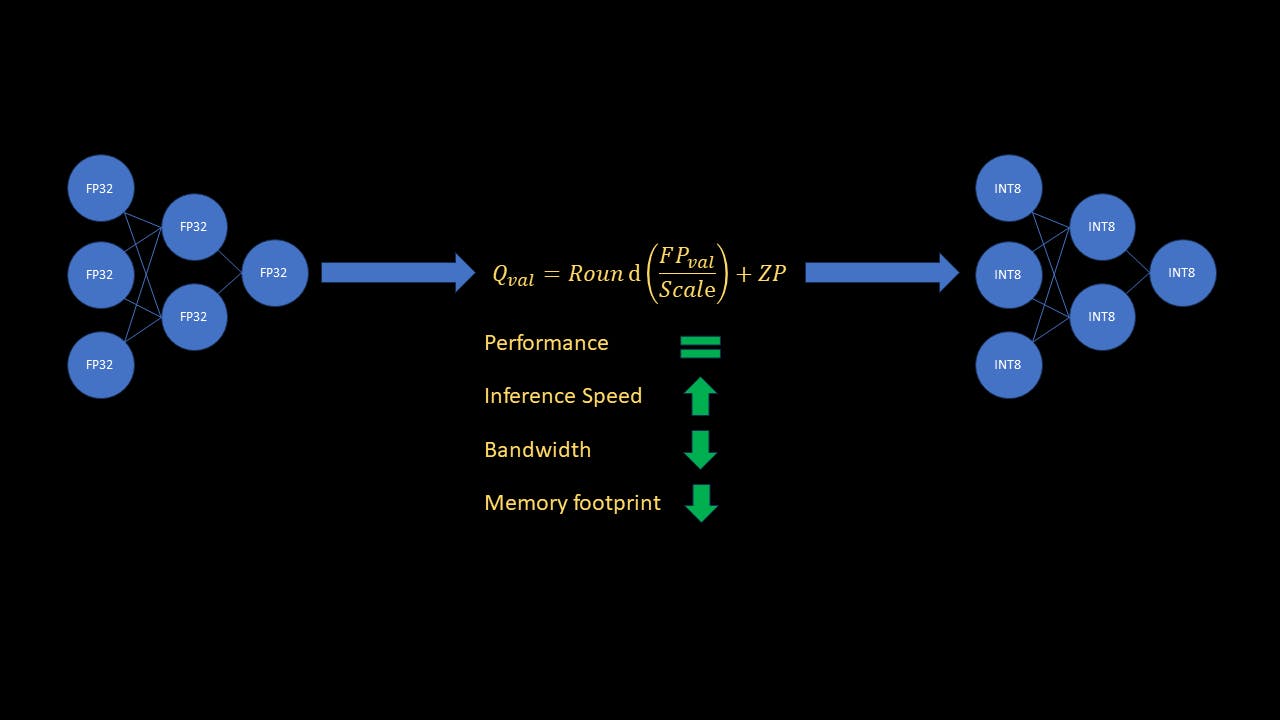
Bạn có biết rằng trong thế giới máy học, hiệu quả của các mô hình Deep Learning (DL) có thể được tăng lên đáng kể nhờ một kỹ thuật gọi là lượng tử hóa? Hãy tưởng tượng việc giảm gánh nặng tính toán của mạng lưới thần kinh của bạn mà không làm giảm hiệu suất của nó. Cũng giống như nén một tệp lớn mà không làm mất đi bản chất của nó, lượng tử hóa mô hình cho phép bạn làm cho mô hình của mình nhỏ hơn và nhanh hơn. Hãy cùng đi sâu vào khái niệm lượng tử hóa hấp dẫn và tiết lộ bí mật tối ưu hóa mạng lưới thần kinh của bạn để triển khai trong thế giới thực. Trước khi tìm hiểu sâu hơn, người đọc nên làm quen với mạng lưới thần kinh và khái niệm cơ bản về lượng tử hóa, bao gồm các thuật ngữ thang đo (S) và điểm 0 (ZP). Đối với những độc giả muốn ôn lại, và giải thích khái niệm rộng và các loại lượng tử hóa. bài viết này bài viết này Trong hướng dẫn này, tôi sẽ giải thích ngắn gọn tại sao lượng tử hóa lại quan trọng và cách triển khai nó bằng Pytorch. Tôi sẽ tập trung chủ yếu vào loại lượng tử hóa được gọi là “lượng tử hóa sau đào tạo”, dẫn đến dung lượng bộ nhớ ít hơn 4 lần so với mô hình ML và giúp suy luận nhanh hơn tới 4 lần. Các khái niệm Tại sao lượng tử hóa lại quan trọng? Tính toán Mạng thần kinh được thực hiện phổ biến nhất với số dấu phẩy động 32 bit. Một số dấu phẩy động 32 bit (FP32) yêu cầu 4 byte bộ nhớ. Để so sánh, một số nguyên 8 bit (INT8) chỉ cần 1 byte bộ nhớ. Hơn nữa, máy tính xử lý số học số nguyên nhanh hơn nhiều so với các phép toán float. Ngay lập tức, bạn có thể thấy rằng việc lượng tử hóa mô hình ML từ FP32 đến INT8 sẽ dẫn đến bộ nhớ ít hơn gấp 4 lần. Hơn nữa, nó cũng sẽ tăng tốc độ suy luận lên gấp 4 lần! Với các mô hình lớn hiện đang thịnh hành, điều quan trọng đối với những người thực hành là có thể tối ưu hóa các mô hình đã được đào tạo về bộ nhớ và tốc độ để suy luận theo thời gian thực. Điều khoản quan trọng Trọng lượng của mạng lưới thần kinh được đào tạo. Trọng số- Về mặt lượng tử hóa, kích hoạt không phải là các hàm kích hoạt như Sigmoid hoặc ReLU. Khi kích hoạt, ý tôi là đầu ra bản đồ tính năng của các lớp trung gian, là đầu vào cho các lớp tiếp theo. Kích hoạt- Lượng tử hóa tĩnh sau đào tạo Lượng tử hóa sau đào tạo có nghĩa là chúng ta không cần đào tạo hoặc hoàn thiện mô hình để lượng tử hóa sau khi đào tạo mô hình gốc. Chúng ta cũng không cần lượng tử hóa các đầu vào của lớp trung gian, được gọi là kích hoạt nhanh chóng. Trong chế độ lượng tử hóa này, các trọng số được lượng tử hóa trực tiếp bằng cách tính toán tỷ lệ và điểm 0 cho mỗi lớp. Tuy nhiên, đối với các kích hoạt, khi đầu vào của mô hình thay đổi, các kích hoạt cũng sẽ thay đổi. Chúng tôi không biết phạm vi của từng đầu vào mà mô hình sẽ gặp trong quá trình suy luận. Vậy làm cách nào chúng ta có thể tính toán tỷ lệ và điểm 0 cho tất cả các kích hoạt của mạng? Chúng ta có thể làm điều này bằng cách hiệu chỉnh mô hình, sử dụng bộ dữ liệu đại diện tốt. Sau đó, chúng tôi quan sát phạm vi giá trị kích hoạt cho bộ hiệu chuẩn và sau đó sử dụng các số liệu thống kê đó để tính toán tỷ lệ và điểm 0. Điều này được thực hiện bằng cách chèn người quan sát vào mô hình để thu thập số liệu thống kê dữ liệu trong quá trình hiệu chuẩn. Sau khi chuẩn bị mô hình (chèn người quan sát), chúng tôi chạy chuyển tiếp mô hình trên tập dữ liệu hiệu chuẩn. Người quan sát sử dụng dữ liệu hiệu chuẩn này để tính toán thang đo và điểm 0 cho các lần kích hoạt. Bây giờ suy luận chỉ là vấn đề áp dụng phép biến đổi tuyến tính cho tất cả các lớp có tỷ lệ tương ứng và điểm 0. Trong khi toàn bộ quá trình suy luận được thực hiện trong INT8, đầu ra mô hình cuối cùng được khử lượng tử (từ INT8 đến FP32). Tại sao các kích hoạt cần phải được lượng tử hóa nếu trọng số đầu vào và mạng đã được lượng tử hóa? Đây là một câu hỏi tuyệt vời. Mặc dù đầu vào và trọng số của mạng thực sự đã có giá trị INT8, nhưng đầu ra của lớp được lưu dưới dạng INT32, để tránh tràn. Để giảm độ phức tạp trong việc xử lý lớp tiếp theo, các kích hoạt được lượng tử hóa từ INT32 đến INT8. Với các khái niệm rõ ràng, hãy đi sâu vào mã và xem nó hoạt động như thế nào! Trong ví dụ này, tôi sẽ sử dụng mô hình resnet18 được tinh chỉnh trên tập dữ liệu Flowers102, có sẵn trực tiếp trong Pytorch. Tuy nhiên, mã sẽ hoạt động với bất kỳ CNN đã được đào tạo nào, với tập dữ liệu hiệu chỉnh thích hợp. Vì hướng dẫn này tập trung vào lượng tử hóa nên tôi sẽ không đề cập đến phần đào tạo và tinh chỉnh. Tuy nhiên, tất cả các mã có thể được tìm thấy . Hãy đi sâu vào! ở đây Mã lượng tử hóa Hãy để chúng tôi nhập các thư viện cần thiết cho việc lượng tử hóa và tải mô hình tinh chỉnh. import torch import torchvision import torchvision.transforms as transforms from torchvision.models import resnet18 import torch.nn as nn from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping import warnings warnings.filterwarnings('ignore') Tiếp theo, chúng ta hãy xác định một số tham số, xác định các biến đổi dữ liệu và trình tải dữ liệu cũng như tải mô hình tinh chỉnh model_path = 'flowers_model.pth' quantized_model_save_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) # Define train data loader, for using as calibration set trainset = torchvision.datasets.Flowers102(root='./data', split="train", download=True, transform=transform) trainLoader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2) # Load the finetuned resnet model model_to_quantize = resnet18(weights=None) num_features = model_to_quantize.fc.in_features model_to_quantize.fc = nn.Linear(num_features, num_classes) model_to_quantize.load_state_dict(torch.load(model_path)) model_to_quantize.eval() print('Loaded fine-tuned model') Trong ví dụ này, tôi sẽ sử dụng một số mẫu huấn luyện làm tập hiệu chuẩn. Bây giờ, chúng ta hãy xác định cấu hình được sử dụng để lượng tử hóa mô hình. # Define quantization parameters config for the correct platform, # "x86" for x86 devices or "qnnpack" for arm devices qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) Trong đoạn mã trên, tôi đã sử dụng cấu hình mặc định, nhưng lớp của Pytorch được sử dụng để mô tả cách lượng tử hóa mô hình hoặc một phần của mô hình. Chúng ta có thể thực hiện điều này bằng cách chỉ định loại lớp quan sát viên sẽ được sử dụng cho trọng số và kích hoạt. QConfig Bây giờ chúng ta đã sẵn sàng chuẩn bị mô hình cho lượng tử hóa # Fuse conv-> relu, conv -> bn -> relu layer blocks and insert observers model_prep = prepare_fx(model=model_to_quantize, qconfig_mapping=qconfig_mapping, example_inputs=torch.randn((1,3,224,224))) Hàm chèn các trình quan sát vào mô hình, đồng thời kết hợp các mô-đun conv→relu và conv→bn→relu. Điều này dẫn đến hoạt động ít hơn và băng thông bộ nhớ thấp hơn do không cần lưu trữ kết quả trung gian của các mô-đun đó. prepare_fx Hiệu chỉnh mô hình bằng cách chạy chuyển tiếp dữ liệu hiệu chuẩn # Run calibration for 10 batches (100 random samples in total) print('Running calibration') with torch.no_grad(): for i, data in enumerate(trainLoader): samples, labels = data _ = model_prep(samples) if i == 10: break Chúng tôi không cần chạy hiệu chỉnh trên toàn bộ tập huấn luyện! Trong ví dụ này, tôi đang sử dụng 100 mẫu ngẫu nhiên, nhưng trên thực tế, bạn nên chọn tập dữ liệu đại diện cho những gì mô hình sẽ thấy trong quá trình triển khai. Lượng tử hóa mô hình và lưu trọng số lượng tử hóa! # Quantize calibrated model quantized_model = convert_fx(model_prep) print('Quantized model!') # Save quantized torch.save(quantized_model.state_dict(), quantized_model_save_path) print('Saved quantized model weights to disk') Và thế là xong! Bây giờ chúng ta hãy xem cách tải một mô hình lượng tử hóa, sau đó so sánh độ chính xác, tốc độ và dung lượng bộ nhớ của mô hình gốc và mô hình lượng tử hóa. Tải một mô hình lượng tử hóa Đồ thị mô hình lượng tử hóa không hoàn toàn giống với mô hình ban đầu, ngay cả khi cả hai đều có cùng các lớp. In lớp đầu tiên ( ) của cả hai mô hình cho thấy sự khác biệt. conv1 print('\nPrinting conv1 layer of fp32 and quantized model') print(f'fp32 model: {model_to_quantize.conv1}') print(f'quantized model: {quantized_model.conv1}') Bạn sẽ nhận thấy rằng cùng với lớp khác, lớp đối lưu của mô hình lượng tử hóa cũng chứa các tham số tỷ lệ và điểm 0. Vì vậy, những gì chúng ta cần làm là tuân theo quy trình lượng tử hóa (không cần hiệu chuẩn) để tạo biểu đồ mô hình, sau đó tải các trọng số lượng tử hóa. Tất nhiên, nếu lưu mô hình lượng tử hóa sang định dạng onnx, chúng ta có thể tải nó giống như bất kỳ mô hình onnx nào khác mà không cần chạy các hàm lượng tử hóa mỗi lần. Trong thời gian chờ đợi, chúng ta hãy xác định một hàm để tải mô hình lượng tử hóa và lưu nó vào . inference_utils.py import torch from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping def load_quantized_model(model_to_quantize, weights_path): ''' Model only needs to be calibrated for the first time. Next time onwards, to load the quantized model, you still need to prepare and convert the model without calibrating it. After that, load the state dict as usual. ''' model_to_quantize.eval() qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) model_prep = prepare_fx(model_to_quantize, qconfig_mapping, torch.randn((1,3,224,224))) quantized_model = convert_fx(model_prep) quantized_model.load_state_dict(torch.load(weights_path)) return quantized_model Xác định các hàm đo độ chính xác và tốc độ Đo độ chính xác import torch def test_accuracy(model, testLoader): model.eval() running_acc = 0 num_samples = 0 with torch.no_grad(): for i, data in enumerate(testLoader): samples, labels = data outputs = model(samples) preds = torch.argmax(outputs, 1) running_acc += torch.sum(preds == labels) num_samples += samples.size(0) return running_acc / num_samples Đây là một mã Pytorch khá đơn giản. Đo tốc độ suy luận tính bằng mili giây (ms) import torch from time import time def test_speed(model): dummy_sample = torch.randn((1,3,224,224)) # Average out inference speed over multiple iterations # to get a true estimate num_iterations = 100 start = time() for _ in range(num_iterations): _ = model(dummy_sample) end = time() return (end-start)/num_iterations * 1000 Thêm cả hai hàm này vào . Bây giờ chúng ta đã sẵn sàng để so sánh các mô hình. Chúng ta hãy đi qua mã. inference_utils.py So sánh các mô hình về độ chính xác, tốc độ và kích thước Trước tiên chúng ta hãy nhập các thư viện cần thiết, xác định tham số, biến đổi dữ liệu và trình tải dữ liệu thử nghiệm. import os import torch import torch.nn as nn import torchvision from torchvision.models import resnet18 import torchvision.transforms as transforms from inference_utils import test_accuracy, test_speed, load_quantized_model import copy import warnings warnings.filterwarnings('ignore') model_weights_path = 'flowers_model.pth' quantized_model_weights_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) testset = torchvision.datasets.Flowers102(root='./data', split="test", download=True, transform=transform) testLoader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2) Tải hai mô hình # Load the finetuned resnet model and the quantized model model = resnet18(weights=None) num_features = model.fc.in_features model.fc = nn.Linear(num_features, num_classes) model.load_state_dict(torch.load(model_weights_path)) model.eval() model_to_quantize = copy.deepcopy(model) quantized_model = load_quantized_model(model_to_quantize, quantized_model_weights_path) So sánh các mô hình # Compare accuracy fp32_accuracy = test_accuracy(model, testLoader) accuracy = test_accuracy(quantized_model, testLoader) print(f'Original model accuracy: {fp32_accuracy:.3f}') print(f'Quantized model accuracy: {accuracy:.3f}\n') # Compare speed fp32_speed = test_speed(model) quantized_speed = test_speed(quantized_model) print(f'Inference time for original model: {fp32_speed:.3f} ms') print(f'Inference time for quantized model: {quantized_speed:.3f} ms\n') # Compare file size fp32_size = os.path.getsize(model_weights_path)/10**6 quantized_size = os.path.getsize(quantized_model_weights_path)/10**6 print(f'Original model file size: {fp32_size:.3f} MB') print(f'Quantized model file size: {quantized_size:.3f} MB') Kết quả Như bạn có thể thấy, độ chính xác của mô hình lượng tử hóa trên dữ liệu thử nghiệm gần như bằng độ chính xác của mô hình gốc! Suy luận với mô hình lượng tử hóa nhanh hơn ~ 3,6 lần (!) Và mô hình lượng tử hóa yêu cầu bộ nhớ ít hơn ~ 4 lần so với mô hình ban đầu! Phần kết luận Trong bài viết này, chúng tôi đã hiểu khái niệm rộng về lượng tử hóa mô hình ML và một loại lượng tử hóa được gọi là Lượng tử hóa tĩnh sau đào tạo. Chúng tôi cũng xem xét lý do tại sao lượng tử hóa lại quan trọng và là một công cụ mạnh mẽ trong thời đại của các mô hình lớn. Cuối cùng, chúng tôi xem qua mã ví dụ để lượng tử hóa một mô hình được đào tạo bằng Pytorch và xem xét kết quả. Như kết quả cho thấy, việc lượng tử hóa mô hình ban đầu không ảnh hưởng đến hiệu suất, đồng thời giảm tốc độ suy luận xuống ~ 3,6 lần và giảm mức chiếm dụng bộ nhớ xuống ~ 4 lần! Một số điểm cần lưu ý- Lượng tử hóa tĩnh hoạt động tốt đối với CNN, nhưng lượng tử hóa động là phương pháp ưa thích cho các mô hình chuỗi. Ngoài ra, nếu lượng tử hóa tác động mạnh đến hiệu suất của mô hình, thì độ chính xác có thể được lấy lại bằng kỹ thuật có tên là Đào tạo nhận biết lượng tử hóa (QAT). Lượng tử hóa động và QAT hoạt động như thế nào? Đó là những bài viết cho một thời điểm khác. Tôi hy vọng với hướng dẫn này, bạn được cung cấp kiến thức để thực hiện lượng tử hóa tĩnh trên các mô hình Pytorch của riêng mình. Người giới thiệu Cơ bản về lượng tử hóa mô hình Lượng tử hóa tensor Tập dữ liệu hoa 102 tài liệu Pytorch