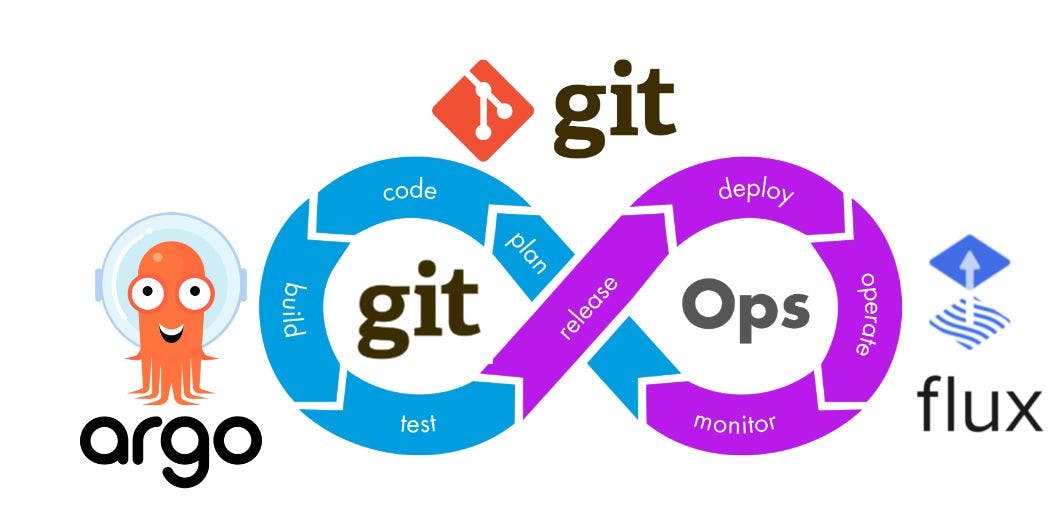
Trên một hãng hàng không mới. Một tiếp viên bước vào khoang hành khách: "Bạn đang ở trên hãng hàng không mới của chúng tôi. Ở mũi máy bay, chúng tôi có một phòng chiếu phim. Ở phần đuôi - một phòng máy đánh bạc. Ở boong dưới - một bể bơi. Trên boong trên - một phòng tắm hơi Bây giờ, các quý ông, hãy thắt dây an toàn, và với tất cả những thứ không cần thiết này, chúng ta sẽ cố gắng cất cánh. Xin chào, tên tôi là Andrii. Tôi đã làm việc trong ngành công nghệ thông tin trong phần lớn cuộc đời mình. Tôi rất quan tâm đến sự phát triển của kỹ thuật quản lý cấu hình cơ sở hạ tầng. Trong 8 năm qua, tôi đã tham gia . DevOps Một trong những xu hướng phổ biến mới là khái niệm , được giới thiệu vào năm 2017 bởi Alexis Richardson, Giám đốc điều hành của Weaworks. Weaworks là một công ty trưởng thành lớn, vào năm 2020, đã huy động được hơn 36 triệu đô la đầu tư để phát triển GitOps của mình. GitOps Bài viết trước của tôi đã thảo luận về một . Bây giờ, tôi sẽ cố gắng nói về những thách thức không rõ ràng có thể chờ đợi bạn khi áp dụng khái niệm này. Tóm lại, GitOps không phải là "Viên đạn bạc". Bạn có thể sẽ phải tổ chức lại với nhiều cách giải quyết phức tạp. Bản thân tôi cũng đã đi trên con đường này và muốn cho bạn thấy những vấn đề khó chịu nhất mà bạn không thể thấy khi đọc các bài viết khác về GitOps. câu chuyện thành công trong việc cắt giảm chi phí về cách chúng tôi chuyển từ Elastic Stack sang Grafana Tổng quan nội dung GitOps là gì và tại sao bạn (không) cần nó Sự cố máy chủ Snowflake GitOps - Thuốc chữa bách bệnh cho mọi vấn đề của bạn (hoặc không) Logic của việc sử dụng Flux với Helm Tài nguyên thông lượng tùy chỉnh Danh sách kiểm tra cho GitOps Vi phạm khái niệm nguồn chân lý duy nhất Kết luận nhỏ GitOps là gì và tại sao bạn (không) cần nó Hãy đi sâu vào ngay! Không trạng thái và có trạng thái Khái niệm xây dựng cơ sở hạ tầng hứa hẹn nhất hiện nay là cơ sở hạ tầng bất biến. Ý tưởng chính của nó là chia cơ sở hạ tầng thành 2 phần cơ bản khác nhau: Không trạng thái và Có trạng thái. Phần Stateless của cơ sở hạ tầng là bất biến và bình thường. Nó không tích lũy trạng thái (không lưu trữ dữ liệu) hoặc thay đổi hoạt động của nó tùy thuộc vào trạng thái tích lũy. Các phiên bản của phần Không trạng thái có thể chứa một số tạo tác cơ bản, tập lệnh và tập hợp. Theo quy định, tôi tạo chúng từ các hình ảnh cơ sở trong môi trường đám mây/ảo hóa. Chúng mong manh và phù du: Tôi cung cấp các phiên bản mới của ứng dụng bằng cách tạo lại các phiên bản từ các hình ảnh cơ sở mới. Dữ liệu liên tục được lưu trữ trong phần Trạng thái. Nó có thể được thực hiện bằng sơ đồ cổ điển với các máy chủ chuyên dụng hoặc bằng một số cơ chế đám mây (DBaaS, đối tượng hoặc lưu trữ khối). Để làm cho “sở thú” này có thể quản lý và hoạt động chính xác, chúng tôi cần sự hợp tác giữa các nhóm kỹ thuật và DevOps, cũng như các quy trình phân phối hoàn toàn tự động. phần CI Lập trình cực đoan là một trong những phương pháp phát triển nhanh. Nó được phân biệt bởi nhiều vòng lặp phản hồi, cho phép bạn duy trì sự đồng bộ hóa với nhu cầu của khách hàng. Chúng tôi triển khai tự động hóa các đường ống phân phối bằng hệ thống CI/CD. Thuật ngữ CI (Tích hợp liên tục) được Grady Booch đưa ra vào năm 1994, và vào năm 1997, Kent Beck và Ron Jeffries đã đưa nó vào lĩnh vực lập trình cực đoan. Trong CI, chúng tôi cần tích hợp các thay đổi của mình thường xuyên nhất có thể vào nhánh làm việc chính của dự án. Trước tiên, điều này đòi hỏi phải phân tách nhiệm vụ chi tiết hơn: những thay đổi nhỏ mang tính nguyên tử hơn và dễ theo dõi, hiểu và tích hợp hơn. Thứ hai, chúng ta không thể hợp nhất mã mới được viết. Trước khi hợp nhất các nhánh, chúng tôi phải đảm bảo rằng không có gì hoạt động trước đó bị hỏng. Để làm điều này, ứng dụng ít nhất phải được xây dựng. Nó cũng là một ý tưởng tốt để che mã bằng các bài kiểm tra. Và đây là nhiệm vụ được thực hiện bởi các hệ thống CI, hệ thống này đã trải qua một chặng đường dài trong quá trình phát triển và ở đâu đó ở giữa con đường này, đã trở thành hệ thống CI/CD. phần đĩa CD Đĩa CD là gì? : Martin Fowler phân biệt 2 định nghĩa về CD Giao Hàng Liên Tục. Đây là lúc, với sự trợ giúp của các phương pháp Tích hợp liên tục và văn hóa DevOps, bạn giữ cho nhánh chính của dự án luôn sẵn sàng để triển khai vào sản xuất. Triển khai liên tục. Đó là Phân phối liên tục, trong đó mọi thứ đi vào nhánh chính sẽ được đưa vào cụm của bạn, vào quá trình sản xuất của bạn. Hãy đi xa hơn nữa. Sự cố máy chủ Snowflake Thật không may, cơ sở hạ tầng bất biến có một số vấn đề. Phần lớn chúng được kế thừa từ khái niệm Cơ sở hạ tầng dưới dạng mã (IaC). Trước hết, đó là sự trôi dạt về cấu hình. Thuật ngữ này ra đời tại Puppet Labs (tác giả của Puppet SCM nổi tiếng) và tuyên bố rằng không phải tất cả các thay đổi trên hệ thống đích đều được thực hiện với sự trợ giúp của quản lý cấu hình hệ thống (SCM). Một số được thực hiện thủ công, bỏ qua chúng. Trong quá trình có nhiều thay đổi như vậy, cấu hình trôi dạt xuất hiện - sự khác biệt giữa cấu hình được mô tả trong SCM và trạng thái thực tế. Điều này dẫn đến một vòng xoáy sợ hãi tự động hóa. Càng thực hiện nhiều thay đổi thủ công, thì càng có nhiều khả năng việc chạy tập lệnh SCM sẽ phá vỡ các thay đổi không được ghi lại. Càng đáng sợ khi chạy nó, thì càng có nhiều khả năng các chỉnh sửa thủ công mới sẽ được thực hiện. Cuối cùng, phản hồi tích cực luẩn quẩn này dẫn đến việc hình thành các máy chủ bông tuyết, chúng trở nên không nhất quán đến mức không ai hiểu bên trong có gì nữa. Sau khi chỉnh sửa thủ công, nút trở nên độc nhất như từng bông tuyết riêng lẻ trong trận tuyết rơi. Sự trôi dạt này khiến các máy chủ ở cấp độ cao hơn trong cơ sở hạ tầng không thay đổi: bây giờ chúng ta có thể nói về Dự án GCP/AWS VPC/Kubernetes-cluster-snowflakes. Điều này xảy ra do việc thực hiện các thay đổi không được quy định trên cơ sở hạ tầng bất biến. Hơn nữa, không ai biết làm thế nào để làm điều đó đúng. GitOps - liều thuốc cho mọi vấn đề của bạn (hoặc không) Và sau đó Weaworks xuất hiện và nói: "Các bạn, chúng tôi có thứ bạn cần - GitOps". Để quảng bá GitOps, họ đã mời một nhân vật nặng ký như Kelsey Hightower, người đã tạo ra . Trong quá trình PR của mình, anh ấy đã truyền đi rất nhiều thông điệp, "Hãy là một người đàn ông, b...! Ngừng viết kịch bản và bắt đầu vận chuyển." Và anh ấy nói một số lượng nhất định tiếp thị trò chơi lô tô nhảm nhí. hướng dẫn "Kubernetes the hard way" Theo tôi, những lợi ích thú vị nhất là: Cải thiện tính nhất quán và tiêu chuẩn hóa triển khai Cải thiện đảm bảo an ninh Phục hồi dễ dàng hơn và nhanh hơn từ các lỗi Quản lý truy cập và bí mật dễ dàng hơn Triển khai tự ghi tài liệu Phân phối tri thức trong nhóm Và bất kỳ ai đang cố gắng tìm hiểu GitOps là gì đều bắt gặp slide sách giáo khoa này. Tiếp theo, chúng tôi tìm thấy các nguyên tắc GitOps, giống với các nguyên tắc IaC được tăng cường một chút: GitOps là khai báo Ứng dụng GitOps được phiên bản và không thay đổi Ứng dụng GitOps được kéo tự động Các ứng dụng GitOps liên tục được đối chiếu Tuy nhiên, đây là một mô tả hình cầu trong chân không, vì vậy chúng tôi tiếp tục nghiên cứu. Chúng tôi tìm thấy trang web GitOps.tech và trên đó có một số giải thích quan trọng. Đầu tiên, chúng ta biết rằng GitOps là mã giống như cơ sở hạ tầng trong Git với công cụ CD tự động áp dụng mã này cho cơ sở hạ tầng. Chúng ta phải có ít nhất 2 kho lưu trữ trong GitOps: Kho ứng dụng. Nó mô tả mã nguồn ứng dụng và các bảng kê khai mô tả việc triển khai ứng dụng đó. Kho cơ sở hạ tầng. Nó mô tả các bảng kê khai cơ sở hạ tầng và môi trường triển khai. Ngoài ra, trong hệ tư tưởng GitOps, cách tiếp cận theo hướng kéo được ưu tiên hơn cách tiếp cận theo hướng đẩy. Điều này hơi trái ngược với sự phát triển của các hệ thống SCM từ những quái vật kéo hạng nặng Puppet và Chef sang Ansible và Terraform dựa trên lực đẩy hạng nhẹ. Và nếu GitOps chủ yếu là một câu chuyện về bộ công cụ, thì sẽ rất hợp lý khi lấy khái niệm dựa trên Flux từ chính Weaworks và giải cấu trúc nó. Các tác giả của ý tưởng phải đã thực hiện một tài liệu tham khảo thực hiện. Flux hiện đã lên đến phiên bản 2 và về mặt kiến trúc bao gồm các bộ điều khiển hoạt động trong một cụm: bộ điều khiển nguồn tùy chỉnh bộ điều khiển bộ điều khiển HELM bộ điều khiển thông báo Bộ điều khiển tự động hóa hình ảnh Tiếp theo, hãy thảo luận về công việc với Flux và Helm. Logic của việc sử dụng Flux với Helm Tôi sẽ mô tả thêm ví dụ triển khai ứng dụng bằng trình quản lý gói Helm trong Flux 2. Tại sao? Theo , trình quản lý gói HELM là ứng dụng Đóng gói phổ biến nhất, với hơn 50% thị phần. Khảo sát của CNCF 2021 Thật không may, tôi không thể tìm thấy dữ liệu cập nhật hơn, nhưng tôi không nghĩ có gì thay đổi nhiều kể từ đó. Vì vậy, hãy xem qua logic cơ bản về cách Flux 2 hoạt động với Helm. Chúng tôi có 2 kho lưu trữ: ứng dụng và cơ sở hạ tầng. Chúng tôi tạo biểu đồ HELM và hình ảnh docker từ kho lưu trữ ứng dụng và thêm chúng vào kho lưu trữ biểu đồ Helm và đăng ký docker tương ứng. Tiếp theo, chúng ta có một cụm Kubernetes chạy bộ điều khiển thông lượng. Để triển khai ứng dụng của mình, chúng tôi chuẩn bị một YAML mô tả tài nguyên tùy chỉnh (CR) HelmRelease và thêm nó vào kho lưu trữ cơ sở hạ tầng. Để giúp flux có được nó, chúng tôi tạo CR GitRepository trong cụm Kubernetes. Bộ điều khiển nguồn nhìn thấy nó, truy cập git và tải xuống. Để triển khai YAML này thành một cụm, chúng tôi mô tả tài nguyên Tùy chỉnh. Bộ điều khiển Kustomize nhìn thấy nó, chuyển đến bộ điều khiển Nguồn, lấy YAML và triển khai nó vào cụm. Bộ điều khiển Helm thấy rằng một CR HelmRelease đã xuất hiện trong cụm và chuyển đến bộ điều khiển Nguồn để lấy biểu đồ HELM được mô tả. Để bộ điều khiển Nguồn cung cấp cho bộ điều khiển HELM biểu đồ được yêu cầu, chúng ta phải tạo Kho lưu trữ HelmRepository trong cụm CR. Helm-controller lấy một biểu đồ từ Source-controller, tạo một bản phát hành và triển khai nó vào cụm. Sau đó, Kubernetes tạo các nhóm cần thiết, chuyển đến sổ đăng ký docker và tải xuống các hình ảnh tương ứng. Theo đó, để triển khai phiên bản mới của ứng dụng, chúng tôi phải tạo một hình ảnh mới, tệp HelmRelease mới và có thể là biểu đồ HELM mới. Sau đó, chúng ta phải đặt chúng vào các kho lưu trữ thích hợp và đợi bộ điều khiển Flux lặp lại công việc trong chuỗi được mô tả ở trên. Và, để kết thúc công việc của mình, chúng tôi đặt Bộ điều khiển thông báo ở đâu đó để thông báo cho chúng tôi về những gì có thể đã xảy ra. Tài nguyên thông lượng tùy chỉnh Bây giờ hãy thảo luận về các tài nguyên tùy chỉnh mà Flux vận hành. Cái đầu tiên là kho lưu trữ Git. Ở đây chúng ta có thể chỉ định địa chỉ của kho lưu trữ Git (dòng 14) và nhánh mà nó xem xét (dòng 10). Vì vậy, chúng tôi chỉ tải xuống một nhánh duy nhất chứ không phải toàn bộ kho lưu trữ. Nhưng! Vì chúng tôi là những kỹ sư có trách nhiệm và cố gắng tuân thủ khái niệm Zero Trust, chúng tôi khóa quyền truy cập vào kho lưu trữ, tạo bí mật bằng khóa trong cụm Kubernetes và đưa nó cho Flux để nó có thể đến đó (dòng 12). Tiếp theo là Tùy chỉnh. Ở đây tôi muốn thu hút sự chú ý của bạn đến thực tế là bộ điều khiển Kustomize từ Flux và Kustomize từ các tác giả của Kubernetes là 2 thứ khác nhau. Tôi không biết tại sao lại chọn cách đặt tên gây mất phương hướng như vậy, nhưng điều quan trọng là không được nhầm lẫn chúng. Kustomization là một cách để triển khai YAML (bất kỳ) từ kho lưu trữ Git sang một cụm. Ở đây, chúng tôi phải chỉ định nguồn nơi chúng tôi đặt nó (dòng 12 - tên của CR GitRepository được mô tả ở trên), thư mục nơi chúng tôi lấy YAML từ đó (dòng 8) và chúng tôi có thể chỉ định không gian tên đích nơi gửi chúng (dòng 13). Tiếp theo là phát hành Helm. Ở đây chúng ta có thể chỉ định tên và phiên bản biểu đồ (dòng 10,11). Tại đây, bạn chỉ định các giá trị biến để Helm có thể tùy chỉnh bản phát hành từ môi trường này sang môi trường khác (dòng 15-19). Đây là một tính năng cực kỳ quan trọng và cần thiết vì môi trường của bạn có thể khác biệt đáng kể. Bạn cũng ghi rõ nguồn lấy biểu đồ Helm (dòng 12, 13, 14). Trong trường hợp này, đó là kho lưu trữ Helm. Nhưng! Vì chúng tôi vẫn là những kỹ sư chịu trách nhiệm, nên chúng tôi cũng có quyền truy cập gần vào kho lưu trữ Helm và cung cấp cho Flux một bí mật để đến đó (dòng 7, 8). Danh sách kiểm tra cho GitOps Vì vậy, hãy lập một danh sách kiểm tra nhỏ để nắm bắt những gì chúng ta vừa xem qua. Để bắt đầu thực hiện GitOps, chúng tôi phải đột ngột viết một loạt các tập lệnh (chúng tôi nhớ rằng Cơ sở hạ tầng không thay đổi là tất cả về các đường ống phân phối hoàn toàn tự động). Vì vậy, trước hết, chúng ta phải tạo: Tập lệnh để xây dựng và đẩy hình ảnh vào sổ đăng ký Docker Kho lưu trữ cơ sở hạ tầng Git Tài khoản truy cập hệ thống CI vào kho lưu trữ GIT cơ sở hạ tầng Tập lệnh để tạo và đẩy tệp HelmRelease Kho lưu trữ điều khiển Tài khoản truy cập hệ thống CI vào kho lưu trữ Helm Tập lệnh xây dựng và xuất bản biểu đồ Helm` Tài khoản thông lượng cho kho lưu trữ cơ sở hạ tầng Tài khoản thông lượng cho kho lưu trữ biểu đồ Helm Tuyệt vời, giờ bạn đã có một danh sách kiểm tra cho GitOps. Tiến lên. Vi phạm khái niệm nguồn chân lý duy nhất Hãy xem những gì chúng tôi nhận được với bản phát hành Helm nói chung. Rõ ràng là Git không thể là nguồn sự thật duy nhất trong trường hợp cụ thể này. Chúng tôi có ít nhất 2 tài nguyên, 2 hiện vật bên ngoài git, mà bản phát hành Helm này phụ thuộc vào: Biểu đồ mũ lái (dòng 8-14) Hình ảnh docker (dòng 19) Và chúng ta có thể phức tạp hóa mọi thứ hơn nữa và chỉ định phạm vi của các phiên bản biểu đồ Helm. Trong trường hợp này, Flux sẽ theo dõi và thiết lập các biểu đồ Helm mới xuất hiện trong phạm vi này. Ngoài ra, Bộ điều khiển nguồn mà chúng tôi có có thể sử dụng YAML làm nguồn, bao gồm các gói S3. Từ đó, chúng tôi có thể giữ cả biểu đồ YAML và Helm. Ngoài ra, chúng tôi có bộ điều khiển tự động hóa Hình ảnh có thể theo dõi các hình ảnh mới trong sổ đăng ký Docker và chỉnh sửa kho lưu trữ cơ sở hạ tầng. Nhưng chúng tôi không muốn Hoạt động repo Biểu đồ HELM hoặc Hoạt động đăng ký Docker. Chúng tôi muốn trở thành GitOps nhất có thể. Vì vậy, chúng tôi xem tài liệu và sửa các quy trình để triển khai biểu đồ Helm của chúng tôi từ kho lưu trữ GIT (chúng tôi chọn kho lưu trữ ứng dụng để lưu trữ nó). Điều này buộc chúng tôi phải tạo một CR GitRepository khác cho kho lưu trữ ứng dụng, một tài khoản để Flux truy cập nó và tạo một bí mật bằng các khóa. Đồng thời, chúng tôi không giải quyết vấn đề phụ thuộc phức tạp vào hình ảnh Docker theo bất kỳ cách nào. Kết luận nhỏ Tôi nghĩ thế là đủ cho ngày hôm nay. Trong phần 2, tôi sẽ cho bạn biết sự tốt lành này có những vấn đề gì. Tôi sẽ thảo luận: Vấn đề đa môi trường Giá trị từ Vấn đề bí mật CI Ops so với GitOps Bảo vệ quy trình quay lui Vấn đề nhiều cụm Ai thực sự cần GitOps? Tôi hy vọng bài viết này hữu ích cho bạn!