


























178 Stories To Learn About Essay


Jan 20, 1970
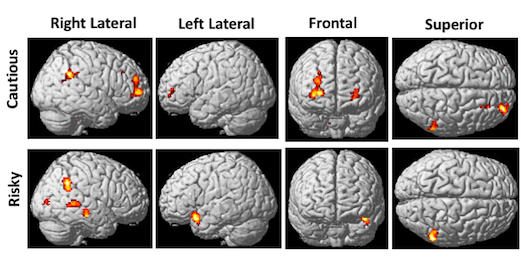
theorizing the human mind, based on the electrical and chemical signals of neurons. https://bitly.cx/uLMc
theorizing the human mind, based on the electrical and chemical signals of neurons. https://bitly.cx/uLMc

theorizing the human mind, based on the electrical and chemical signals of neurons. https://bitly.cx/uLMc
theorizing the human mind, based on the electrical and chemical signals of neurons. https://bitly.cx/uLMc

Jan 20, 1970
Jan 20, 1970


