
1,173 чтения
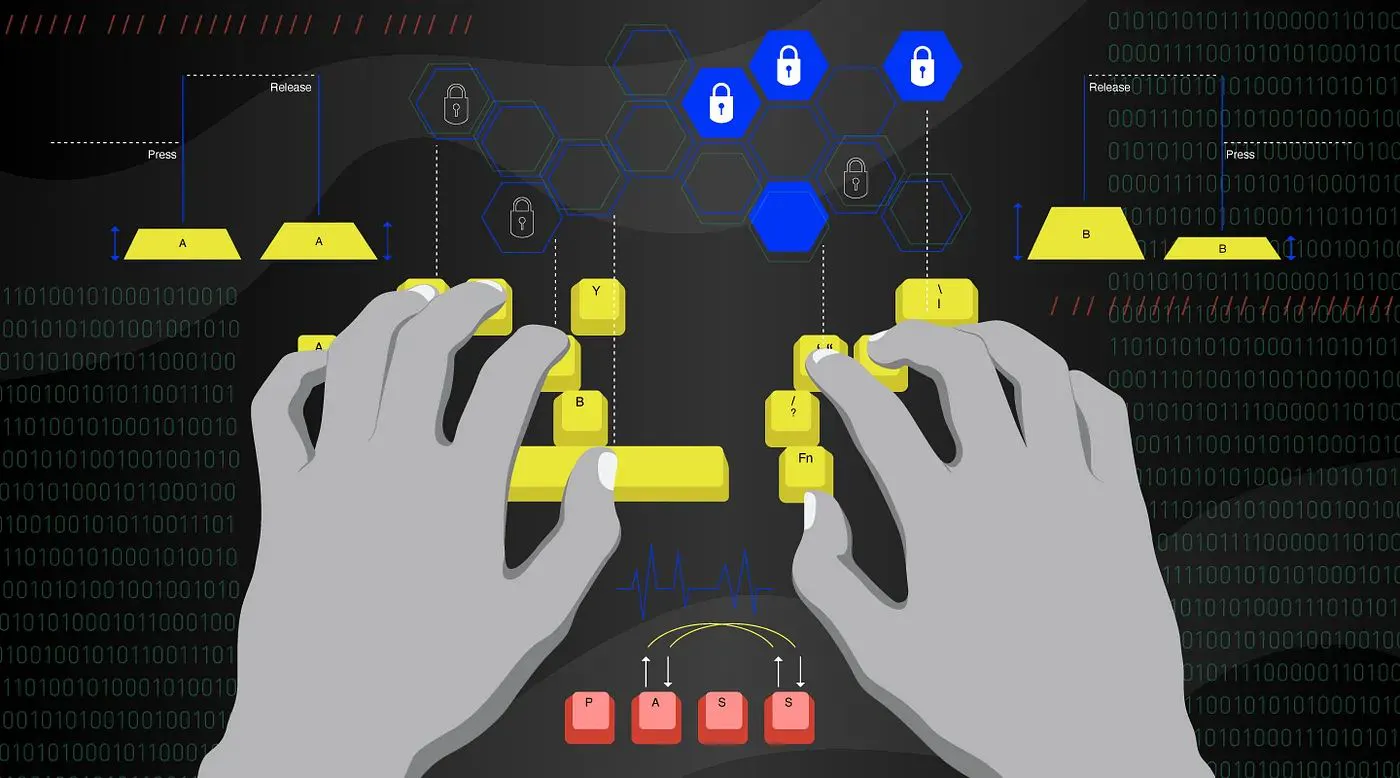
Применение моделей машинного обучения для распознавания пользователей с помощью динамики нажатия клавиш
by byBogdan Tudorache@tudoracheabogdan
byBogdan Tudorache@tudoracheabogdan
Consistency and Continuity. I am an engineer by day, python developer & founder by night
2023/10/10


















Consistency and Continuity. I am an engineer by day, python developer & founder by night
Story's Credibility


Consistency and Continuity. I am an engineer by day, python developer & founder by night
Story's Credibility
About Author

Consistency and Continuity. I am an engineer by day, python developer & founder by night
КОММЕНТАРИИ












