
1,166 lecturas
La aplicación de modelos de aprendizaje automático en el reconocimiento de usuarios mediante dinámica de pulsaciones de teclas
by byBogdan Tudorache@tudoracheabogdan
byBogdan Tudorache@tudoracheabogdan
Consistency and Continuity. I am an engineer by day, python developer & founder by night
2023/10/10


















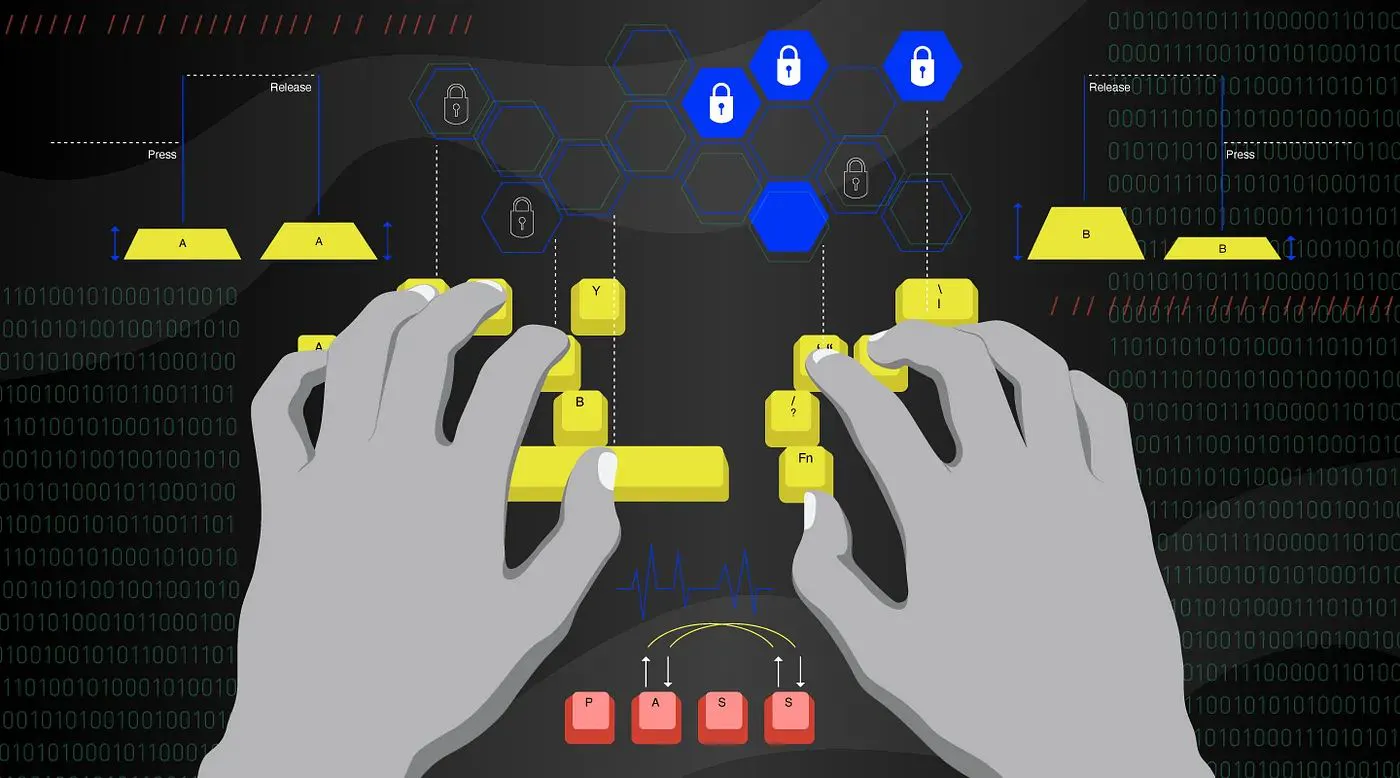
Consistency and Continuity. I am an engineer by day, python developer & founder by night
Story's Credibility


Consistency and Continuity. I am an engineer by day, python developer & founder by night
Story's Credibility
About Author

Consistency and Continuity. I am an engineer by day, python developer & founder by night
COMENTARIOS












