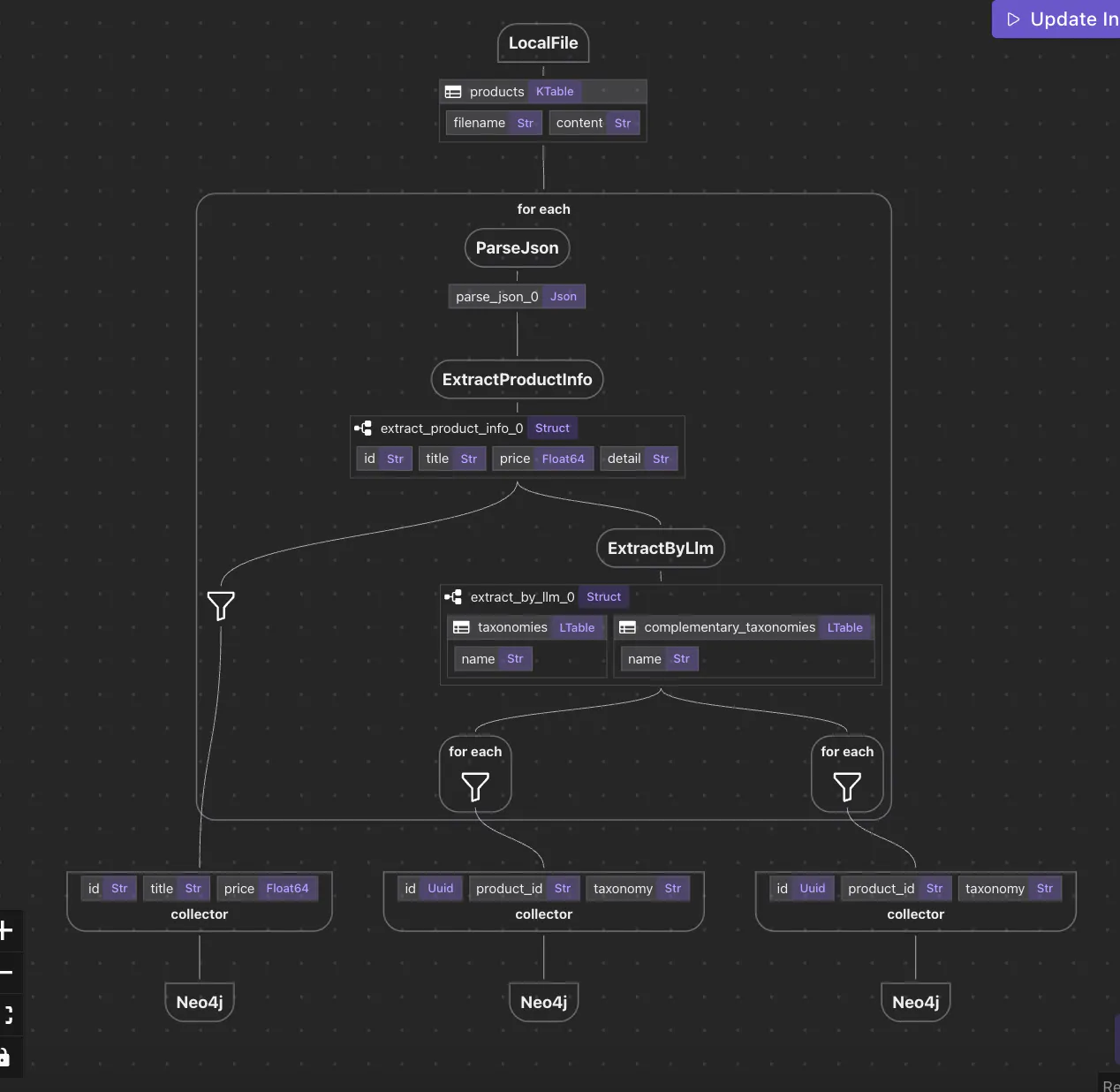
В большинстве рамок оркестрации данных, то, как данные обрабатываются, является последующей мыслью. Вы создаете рабочие процессы, соединяете компоненты вместе и надеетесь, что данные будут вести себя так, как вы ожидаете. Под крышкой значения мутируются, трансформируются имплицитно или скрываются в состоятельных компонентах. Если вы любите эту статью, пожалуйста, отпустите нам звезду ⭐ на Чтобы помочь нам расти. GitHub репо Но CocoIndex переворачивает этот подход на голову. Проработав в этой области в течение многих лет, мы наблюдали, что побочные эффекты в традиционных системах часто приводят к повышению сложности, проблемам с удалением данных и непредсказуемому поведению.Этот опыт привел нас к принятию чистого подхода к программированию потока данных в CocoIndex, где трансформации данных являются ясными, неизменными и отслеживаемыми, обеспечивая надежность и простоту на протяжении всего трубопровода. Вместо того чтобы рассматривать данные как черные ящики, которые проходят между задачами, Где находятся данные и их трансформации Этот сдвиг делает разницу в мире, когда вы работаете со сложными трубопроводами, особенно в области извлечения знаний, графика и семантического поиска. CocoIndex embraces the Data Flow Programming paradigm observable, traceable, and immutable Что такое Программирование потоков данных? является декларативной моделью программирования, в которой: Программирование потоков данных Данные «текут» через график трансформаций. Каждая трансформация чиста — никаких скрытых побочных эффектов, никаких мутаций состояния. Структура вашего кода отражает структуру вашей логики данных. Это принципиально отличается от оркестраторов рабочего процесса, где задачи оркестрируются во времени, а данные часто непрозрачны. В CocoIndex, Но не задания. data is the primary unit of composition Простой поток данных в CocoIndex Давайте рассмотрим концептуальный поток данных: Parse files → Data Mapping → Data Extraction → Knowledge Graph Каждая стрелка представляет собой трансформацию: функцию, которая принимает данные и производит новые данные.Результатом является цепочка отслеживаемых шагов, где вы можете проверять как входы, так и выходы — в любой точке. Каждая стрелка представляет собой трансформацию: функцию, которая принимает данные и производит новые данные.Результатом является цепочка отслеживаемых шагов, где вы можете проверять как входы, так и выходы — в любой точке. Каждое поле в этой диаграмме представляет собой — нет побочных эффектов, нет скрытой логики. Просто четкий, видимый поток данных. declarative transformation Пример кода: декларативный и прозрачный Вот как этот поток может выглядеть в CocoIndex: # ingest data['content'] = flow_builder.add_source(...) # transform data['out'] = data['content'] .transform(...) .transform(...) # collect data collector.collect(...) # export to db, vector db, graph db ... collector.export(...) Красота здесь такова: Каждый .transform() является детерминистским и отслеживаемым. Вы не пишете логику CRUD — цифры CocoIndex выводятся. Вы можете наблюдать за всеми данными до и после любой стадии. Нет императивных мутаций — просто логика В традиционных системах вы можете написать: if entity_exists(id): update_entity(id, data) else: create_entity(id, data) Но в CocoIndex вы говорите: data['entities'] = data['mapped'].transform(extract_entities) И система определяет, подразумевает ли это создание, обновление или удаление. , позволяя вам сосредоточиться на том, что действительно имеет значение: как должны быть ваши данные Не то, как оно должно храниться. abstracts away lifecycle logic derived Почему это важно: преимущества потока данных в CocoIndex Полная линейка данных С моделью потока данных CocoIndex вы можете проследить его обратно через каждую трансформацию в исходный файл или поле. Наблюдение на каждом шагу CocoIndex позволяет наблюдать за данными на любом этапе. чем в непрозрачных трубопроводах. significantly easier Реактивность Каждая последующая трансформация автоматически переоценивается. CocoIndex обеспечивает реактивные трубопроводы без дополнительной сложности. ♀️ Декларативная простота Вы не имеете дело с мутациями, ошибками в синхронизации состояния или ручной оркестрацией. Вы определяете логику один раз — и позволяете потоку данных. Смена парадигмы в строительных приложениях данных Модель программирования потока данных CocoIndex - это не просто функция - это Он изменяет то, как вы думаете о обработке данных: philosophical shift От оркестрации задач до трансформации данных От мутабельных трубопроводов к неизменным наблюдаемым От императивного CRUD кода → до декларативных формул Это делает ваш трубопровод . easier to test, easier to reason about, and easier to extend Окончательные мысли Если вы строите трубопроводы для извлечения объектов, поиска или графиков знаний, Вам больше не нужно перегружать операции хранения или отслеживать изменения состояния — вы просто определяете, как данные трансформируются. CocoIndex’s data flow programming model offers a new kind of clarity И это будущее, которое стоит строить. Мы постоянно совершенствуемся, и в скором времени появятся больше функций и примеров.Если вы любите эту статью, пожалуйста, бросьте нам звезду ⭐ на Чтобы помочь нам расти. GitHub репо