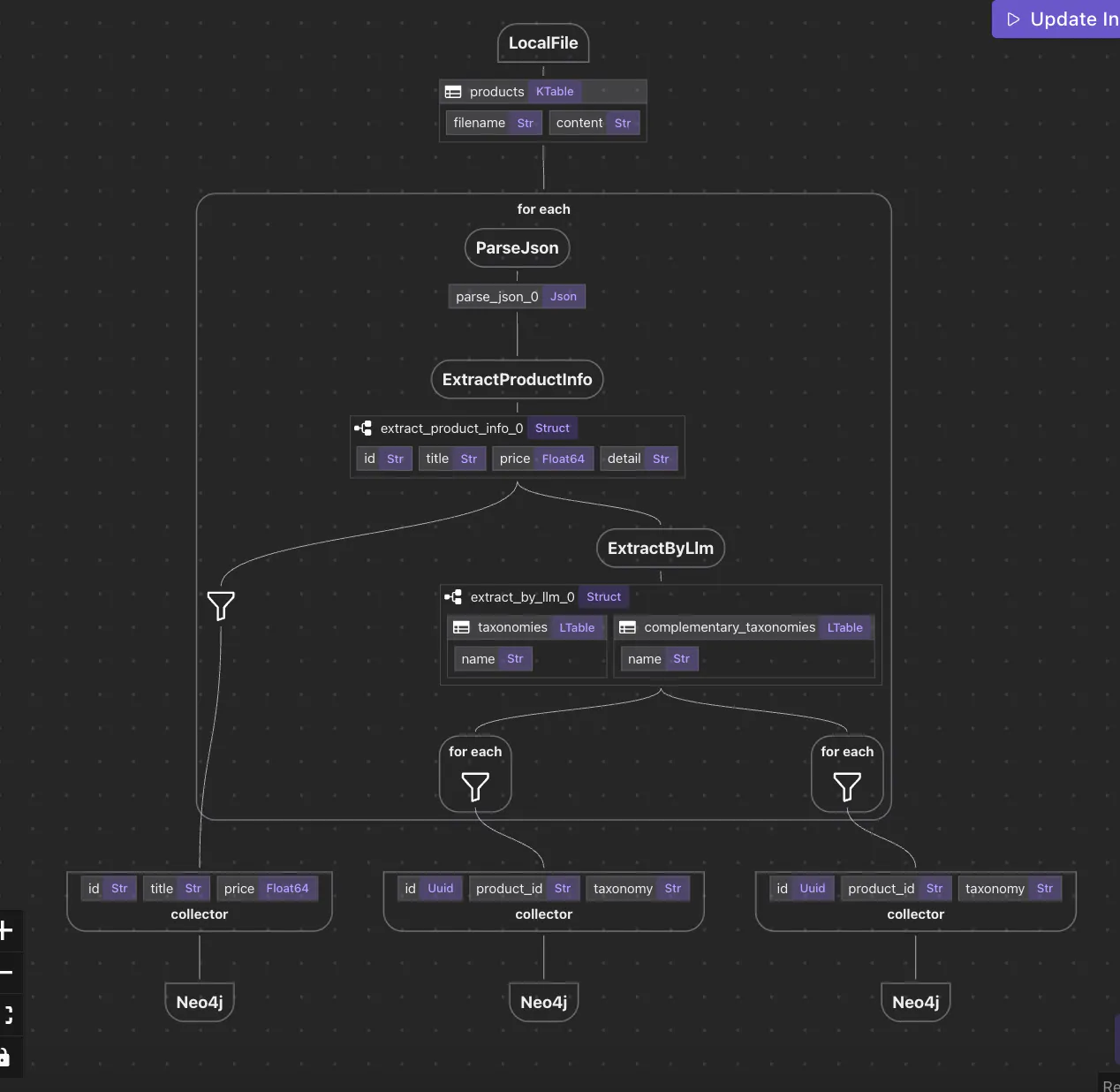
ほとんどのデータオーケストラリングフレームワークでは、データを処理する方法は後で考えられます。ワークフローを構築し、コンポーネントを組み合わせ、データがあなたが期待するように振る舞うことを希望します。 私たちを成長させるために GitHub レポ しかし、CocoIndexはそのアプローチを頭に置く。 長年にわたりこの分野で働いてきた後、従来のシステムにおける副作用がしばしば複雑さ、デバッグの課題、および予測不能な行動を増加させることを観察しました。この経験は、データ変換が明確で不変性があり、追跡可能であるCocoIndexにおける純粋なデータフロープログラミングアプローチを採用し、パイプライン全体で信頼性とシンプルさを確保しました。 データをタスク間を通過するブラックボックスとして扱う代わりに、 データとその変換がどこにあるか この変化は、複雑なパイプラインで作業するときに世界を変える - 特に知識抽出、グラフビルディング、セマンティック検索で。 CocoIndex embraces the Data Flow Programming paradigm observable, traceable, and immutable データフロープログラミングとは? 宣言型プログラミングモデルは、 データフロープログラミング データは変換のグラフを通して「流れ」します。 すべての変換は純粋で、隠された副作用も、状態の変異もありません。 コードの構造は、データの論理の構造を反映します。 これは、タスクが時間的にオーケストラ化され、データがしばしば曖昧であるワークフローオーケストラとは根本的に異なります。 ココインデックスでは、 タスクじゃない。 data is the primary unit of composition CocoIndex でのシンプルなデータフロー コンセプトデータフローを見てみましょう: Parse files → Data Mapping → Data Extraction → Knowledge Graph 各矢印は変換を表す:データを収集し、新しいデータを生成する関数. 結果は、入力と出力の両方をあらゆる点でチェックできる追跡可能なステップの連鎖です。 各矢印は変換を表す:データを収集し、新しいデータを生成する関数. 結果は、入力と出力の両方をあらゆる点でチェックできる追跡可能なステップの連鎖です。 この図表の各ボックスは、a — 副作用なし、隠された論理なし. 単に明確で目に見えるデータフローだけ。 declarative transformation コード例: Declarative and Transparent 以下は、CocoIndexでこのフローがどう見えるかです。 # ingest data['content'] = flow_builder.add_source(...) # transform data['out'] = data['content'] .transform(...) .transform(...) # collect data collector.collect(...) # export to db, vector db, graph db ... collector.export(...) 美しさは、これです: すべての .transform() は、決定的であり、追跡可能である。 あなたはCRUDの論理を書いていません - CocoIndexの数字が表示されます。 すべてのステージの前と後でデータを観察することができます。 No Imperative Mutations (Just Logic) 伝統的なシステムでは、あなたは書くことができます: if entity_exists(id): update_entity(id, data) else: create_entity(id, data) しかし、CocoIndexでは、あなたは言う: data['entities'] = data['mapped'].transform(extract_entities) そして、システムは、それが作成、更新、または削除を意味するかどうかを計算します。 , あなたが本当に重要なものに焦点を当てることを可能にします: あなたのデータがどのように処理されるべきか どのように保管するかではなく、 abstracts away lifecycle logic derived なぜ重要なのか:CocoIndexにおけるデータフローの利点 完全なデータライン CocoIndexのデータフローモデルを使用すると、すべての変換を元のファイルまたはフィールドに追跡することができます。 各ステップでの観察力 CocoIndexは、データをあらゆる段階で観察できるようにします。 透明なパイプラインシステムよりも significantly easier 反応性 源を変更する? すべてのダウンストリーム変換は自動的に再評価されます CocoIndexは、追加の複雑さなしに反応パイプラインを可能にします。 ♀️シンプルな表現 あなたは変異、ステータス同期のエラー、または手動オーケストレーションに取り組んでいません. You define the logic once — and let the data flow. ビルドデータアプリケーションにおけるパラダイムの変化 CocoIndexのデータフロープログラミングモデルは単なる機能ではなく、 データ処理について考える方法を変更します: philosophical shift タスクオーケストラからデータ変換へ Mutable Pipelines から Immutable Observables へ Imperative CRUD から declarative formula へ あなたのパイプラインを作る . easier to test, easier to reason about, and easier to extend 最終思考 エンティティ抽出、検索、または知識グラフのためのパイプラインを構築している場合は、 もはや、ストレージ操作をジョギングしたり、状態の変更を追跡したりする必要はありません - データがどのように変換されるかを定義するだけです。 CocoIndex’s data flow programming model offers a new kind of clarity それこそが、築く価値のある未来です。 我々は絶えず改善し、より多くの機能と例が間もなく来る. あなたがこの記事を愛している場合は、私たちに星を落としてください ⭐ 私たちを成長させるために GitHub レポ