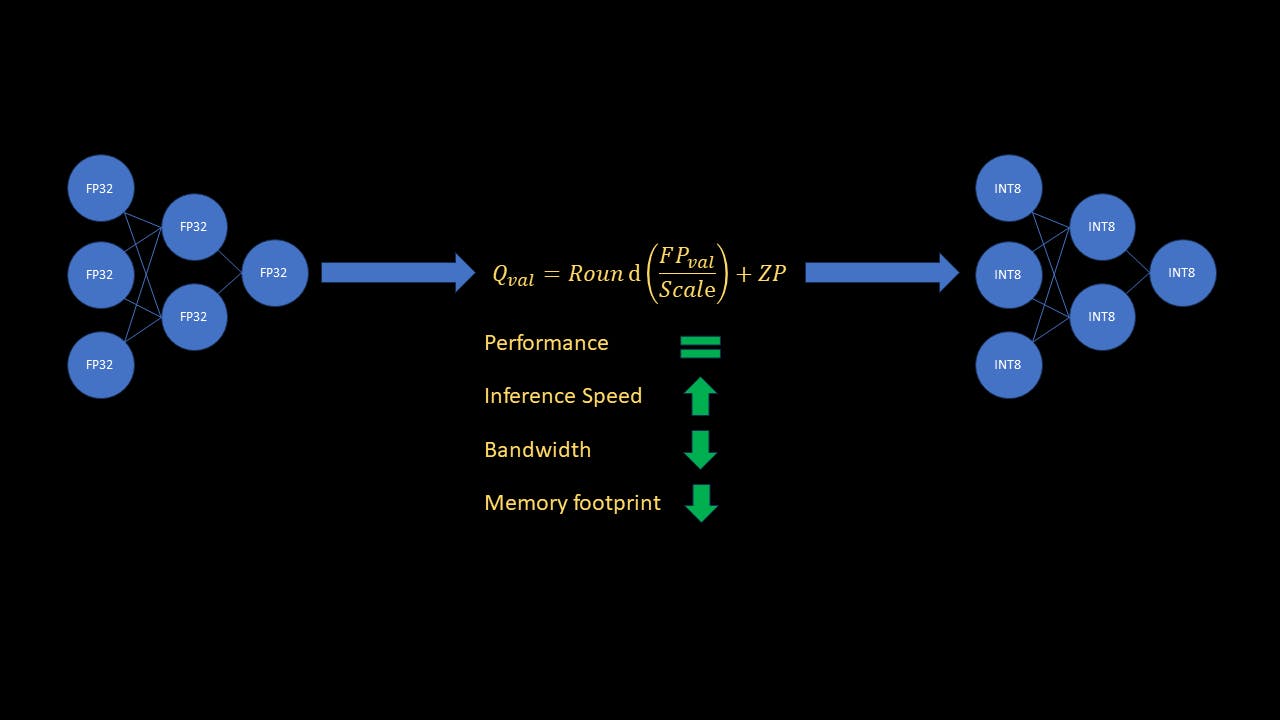
Знаете ли вы, что в мире машинного обучения эффективность моделей глубокого обучения (DL) можно значительно повысить с помощью метода, называемого квантованием? Представьте себе, что вы снижаете вычислительную нагрузку вашей нейронной сети, не жертвуя при этом ее производительностью. Точно так же, как сжатие большого файла без потери его сути, квантование модели позволяет сделать ваши модели меньше и быстрее. Давайте углубимся в увлекательную концепцию квантования и раскроем секреты оптимизации ваших нейронных сетей для реального использования. Прежде чем мы углубимся, читатели должны быть знакомы с нейронными сетями и базовой концепцией квантования, включая термины масштаб (S) и нулевая точка (ZP). Для читателей, которые хотели бы освежить знания, и объясняют общую концепцию и типы квантования. эта статья эта статья В этом руководстве я кратко объясню, почему квантование важно и как его реализовать с помощью Pytorch. Я сосредоточусь в основном на типе квантования, называемом «статическое квантование после обучения», которое приводит к уменьшению объема памяти модели ML в 4 раза и ускорению вывода до 4 раз. Концепции Почему квантование имеет значение? Вычисления в нейронных сетях чаще всего выполняются с 32-битными числами с плавающей запятой. Одно 32-битное число с плавающей запятой (FP32) требует 4 байта памяти. Для сравнения, одно 8-битное целое число (INT8) требует всего 1 байт памяти. Кроме того, компьютеры обрабатывают целочисленные арифметические операции гораздо быстрее, чем операции с плавающей запятой. Сразу видно, что квантование модели ML с FP32 на INT8 приведет к уменьшению памяти в 4 раза. Кроме того, это также ускорит вывод в 4 раза! Поскольку большие модели сейчас в моде, практикам важно иметь возможность оптимизировать обученные модели с точки зрения памяти и скорости для вывода в реальном времени. Ключевые термины веса обученной нейронной сети. Веса – С точки зрения квантования активации не являются функциями активации, такими как Sigmoid или ReLU. Под активациями я подразумеваю выходные данные карты объектов промежуточных слоев, которые являются входными данными для следующих слоев. Активации. Статическое квантование после обучения Статическое квантование после обучения означает, что нам не нужно обучать или настраивать модель для квантования после обучения исходной модели. Нам также не нужно квантовать входные данные промежуточного слоя, называемые активациями на лету. В этом режиме квантования веса квантуются напрямую путем вычисления масштаба и нулевой точки для каждого слоя. Однако для активаций по мере изменения входных данных в модель, активации также будут меняться. Мы не знаем диапазон каждого входного сигнала, с которым модель столкнется во время вывода. Итак, как мы можем вычислить масштаб и нулевую точку для всех активаций сети? Мы можем сделать это, откалибровав модель, используя хороший репрезентативный набор данных. Затем мы наблюдаем диапазон значений активаций для калибровочного набора, а затем используем эту статистику для расчета масштаба и нулевой точки. Это делается путем добавления в модель наблюдателей, которые собирают статистику данных во время калибровки. После подготовки модели (вставки наблюдателей) мы запускаем прямой проход модели к набору калибровочных данных. Наблюдатели используют эти калибровочные данные для расчета масштаба и нулевой точки для активаций. Теперь вывод — это всего лишь вопрос применения линейного преобразования ко всем слоям с соответствующим масштабом и нулевыми точками. Хотя весь вывод выполняется в INT8, конечный результат модели деквантуется (от INT8 до FP32). Почему активации необходимо квантовать, если входные и сетевые веса уже квантованы? Это отличный вопрос. Хотя входные данные сети и веса действительно уже являются значениями INT8, выходные данные слоя сохраняются как INT32, чтобы избежать переполнения. Чтобы уменьшить сложность обработки следующего уровня, активации квантуются от INT32 до INT8. Разобравшись с концепциями, давайте углубимся в код и посмотрим, как он работает! В этом примере я буду использовать модель resnet18, настроенную на наборе данных Flowers102, доступном непосредственно в Pytorch. Однако код будет работать для любой обученной CNN с соответствующим набором калибровочных данных. Поскольку это руководство посвящено квантованию, я не буду рассматривать часть обучения и тонкой настройки. Однако весь код можно найти . Давайте погрузимся! здесь Код квантования Импортируем библиотеки, необходимые для квантования и загрузим доработанную модель. import torch import torchvision import torchvision.transforms as transforms from torchvision.models import resnet18 import torch.nn as nn from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping import warnings warnings.filterwarnings('ignore') Далее давайте определим некоторые параметры, определим преобразования данных и загрузчики данных, а также загрузим точно настроенную модель. model_path = 'flowers_model.pth' quantized_model_save_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) # Define train data loader, for using as calibration set trainset = torchvision.datasets.Flowers102(root='./data', split="train", download=True, transform=transform) trainLoader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2) # Load the finetuned resnet model model_to_quantize = resnet18(weights=None) num_features = model_to_quantize.fc.in_features model_to_quantize.fc = nn.Linear(num_features, num_classes) model_to_quantize.load_state_dict(torch.load(model_path)) model_to_quantize.eval() print('Loaded fine-tuned model') В этом примере я буду использовать несколько обучающих выборок в качестве калибровочного набора. Теперь давайте определим конфигурацию, используемую для квантования модели. # Define quantization parameters config for the correct platform, # "x86" for x86 devices or "qnnpack" for arm devices qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) В приведенном выше фрагменте я использовал конфигурацию по умолчанию, но класс Pytorch используется для описания того, как модель или часть модели должна быть квантована. Мы можем сделать это, указав тип классов-наблюдателей, которые будут использоваться для весов и активаций. QConfig Теперь мы готовы подготовить модель к квантованию. # Fuse conv-> relu, conv -> bn -> relu layer blocks and insert observers model_prep = prepare_fx(model=model_to_quantize, qconfig_mapping=qconfig_mapping, example_inputs=torch.randn((1,3,224,224))) Функция вставляет наблюдателей в модель, а также объединяет модули conv→relu и conv→bn→relu. Это приводит к меньшему количеству операций и снижению пропускной способности памяти из-за отсутствия необходимости хранить промежуточные результаты этих модулей. prepare_fx Откалибруйте модель, выполнив прямой проход по калибровочным данным. # Run calibration for 10 batches (100 random samples in total) print('Running calibration') with torch.no_grad(): for i, data in enumerate(trainLoader): samples, labels = data _ = model_prep(samples) if i == 10: break Нам не нужно проводить калибровку всего обучающего набора! В этом примере я использую 100 случайных выборок, но на практике вам следует выбрать набор данных, который будет репрезентативным для того, что модель увидит во время развертывания. Квантуйте модель и сохраните квантованные веса! # Quantize calibrated model quantized_model = convert_fx(model_prep) print('Quantized model!') # Save quantized torch.save(quantized_model.state_dict(), quantized_model_save_path) print('Saved quantized model weights to disk') Вот и все! Теперь давайте посмотрим, как загрузить квантованную модель, а затем сравним точность, скорость и объем памяти исходной и квантованной моделей. Загрузите квантованную модель Граф квантованной модели не совсем такой же, как исходная модель, даже если обе имеют одинаковые слои. Печать первого слоя ( ) обеих моделей показывает разницу. conv1 print('\nPrinting conv1 layer of fp32 and quantized model') print(f'fp32 model: {model_to_quantize.conv1}') print(f'quantized model: {quantized_model.conv1}') Вы заметите, что наряду с другим классом слой conv1 квантованной модели также содержит параметры масштаба и нулевой точки. Таким образом, нам нужно следовать процессу квантования (без калибровки), чтобы создать граф модели, а затем загрузить квантованные веса. Конечно, если мы сохраним квантованную модель в формате onnx, мы сможем загрузить ее как любую другую модель onnx, не запуская каждый раз функции квантования. А пока давайте определим функцию для загрузки квантованной модели и сохраним ее в . inference_utils.py import torch from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping def load_quantized_model(model_to_quantize, weights_path): ''' Model only needs to be calibrated for the first time. Next time onwards, to load the quantized model, you still need to prepare and convert the model without calibrating it. After that, load the state dict as usual. ''' model_to_quantize.eval() qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) model_prep = prepare_fx(model_to_quantize, qconfig_mapping, torch.randn((1,3,224,224))) quantized_model = convert_fx(model_prep) quantized_model.load_state_dict(torch.load(weights_path)) return quantized_model Определить функции для измерения точности и скорости Точность измерения import torch def test_accuracy(model, testLoader): model.eval() running_acc = 0 num_samples = 0 with torch.no_grad(): for i, data in enumerate(testLoader): samples, labels = data outputs = model(samples) preds = torch.argmax(outputs, 1) running_acc += torch.sum(preds == labels) num_samples += samples.size(0) return running_acc / num_samples Это довольно простой код Pytorch. Измерьте скорость вывода в миллисекундах (мс) import torch from time import time def test_speed(model): dummy_sample = torch.randn((1,3,224,224)) # Average out inference speed over multiple iterations # to get a true estimate num_iterations = 100 start = time() for _ in range(num_iterations): _ = model(dummy_sample) end = time() return (end-start)/num_iterations * 1000 Добавьте обе эти функции в . Теперь мы готовы сравнить модели. Давайте пройдемся по коду. inference_utils.py Сравнивайте модели по точности, скорости и размеру. Давайте сначала импортируем необходимые библиотеки, определим параметры, преобразования данных и тестовый загрузчик данных. import os import torch import torch.nn as nn import torchvision from torchvision.models import resnet18 import torchvision.transforms as transforms from inference_utils import test_accuracy, test_speed, load_quantized_model import copy import warnings warnings.filterwarnings('ignore') model_weights_path = 'flowers_model.pth' quantized_model_weights_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) testset = torchvision.datasets.Flowers102(root='./data', split="test", download=True, transform=transform) testLoader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2) Загрузите две модели # Load the finetuned resnet model and the quantized model model = resnet18(weights=None) num_features = model.fc.in_features model.fc = nn.Linear(num_features, num_classes) model.load_state_dict(torch.load(model_weights_path)) model.eval() model_to_quantize = copy.deepcopy(model) quantized_model = load_quantized_model(model_to_quantize, quantized_model_weights_path) Сравнить модели # Compare accuracy fp32_accuracy = test_accuracy(model, testLoader) accuracy = test_accuracy(quantized_model, testLoader) print(f'Original model accuracy: {fp32_accuracy:.3f}') print(f'Quantized model accuracy: {accuracy:.3f}\n') # Compare speed fp32_speed = test_speed(model) quantized_speed = test_speed(quantized_model) print(f'Inference time for original model: {fp32_speed:.3f} ms') print(f'Inference time for quantized model: {quantized_speed:.3f} ms\n') # Compare file size fp32_size = os.path.getsize(model_weights_path)/10**6 quantized_size = os.path.getsize(quantized_model_weights_path)/10**6 print(f'Original model file size: {fp32_size:.3f} MB') print(f'Quantized model file size: {quantized_size:.3f} MB') Полученные результаты Как видите, точность квантованной модели на тестовых данных почти равна точности исходной модели! Вывод с помощью квантовой модели выполняется примерно в 3,6 раза быстрее (!), а квантованная модель требует примерно в 4 раза меньше памяти, чем исходная модель! Заключение В этой статье мы поняли широкую концепцию квантования модели ML и тип квантования, называемый статическим квантованием после обучения. Мы также рассмотрели, почему квантование важно и является мощным инструментом во времена больших моделей. Наконец, мы рассмотрели пример кода для квантования обученной модели с помощью Pytorch и рассмотрели результаты. Как показали результаты, квантование исходной модели не повлияло на производительность и в то же время снизило скорость вывода примерно в 3,6 раза и уменьшило объем памяти примерно в 4 раза! Несколько замечаний: статическое квантование хорошо работает для CNN, но динамическое квантование является предпочтительным методом для моделей последовательностей. Кроме того, если квантование резко влияет на производительность модели, точность можно восстановить с помощью метода, называемого обучением с учетом квантования (QAT). Как работают динамическое квантование и QAT? Это посты для другого раза. Я надеюсь, что это руководство предоставит вам знания для выполнения статического квантования на ваших собственных моделях Pytorch. Рекомендации Основы квантования модели Тензорное квантование Набор данных Цветы 102 Документы Pytorch