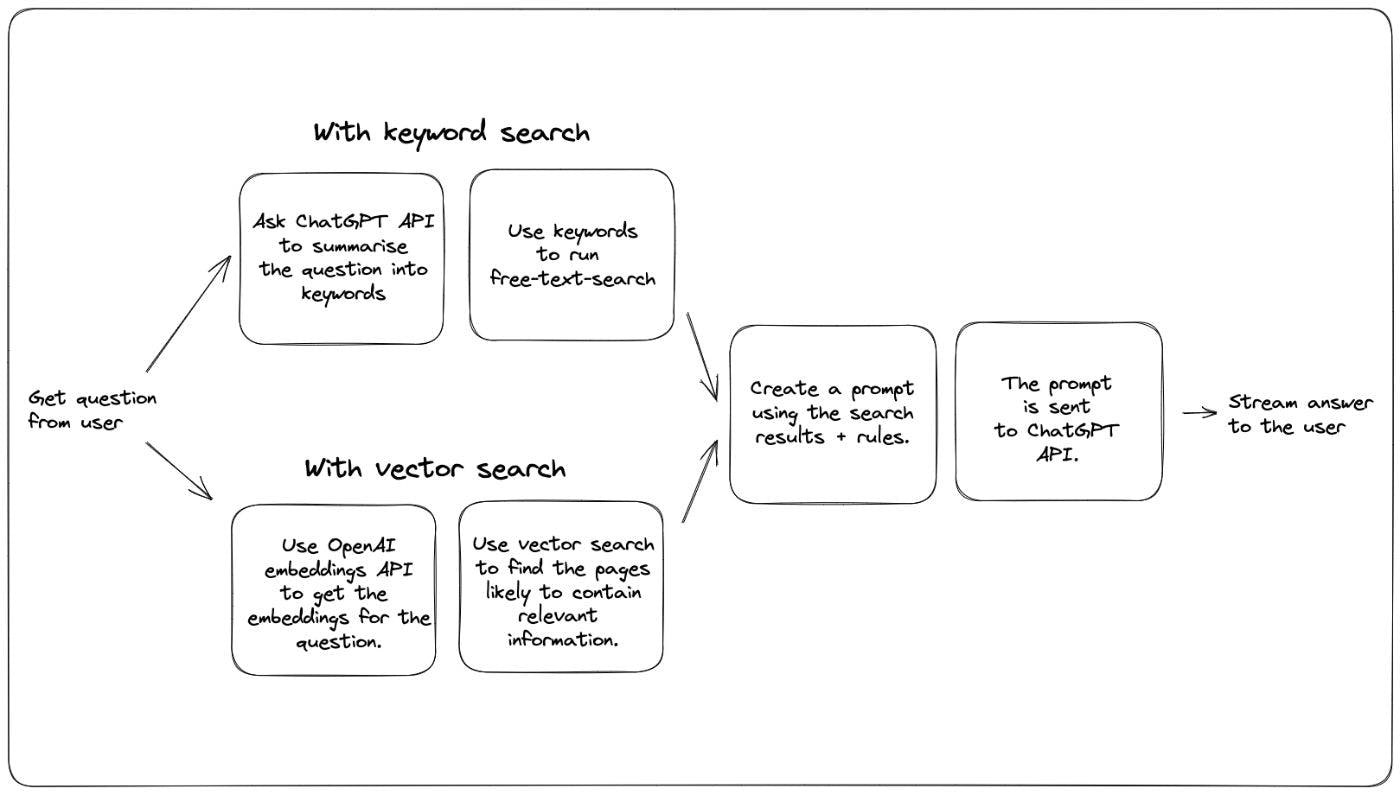
Na semana passada, adicionamos um bot de perguntas e respostas que responde a perguntas de . Isso aproveita a tecnologia ChatGPT para responder a perguntas da documentação Xata, mesmo que o modelo OpenAI GPT nunca tenha sido treinado nos documentos Xata. nossa documentação A maneira como fazemos isso é usando uma abordagem sugerida por Simon Willison nesta . A mesma abordagem também pode ser encontrada em um . A ideia é a seguinte: postagem do blog livro de receitas da OpenAI Execute uma pesquisa de texto na documentação para encontrar o conteúdo mais relevante para a pergunta feita pelo usuário. Produza um prompt com este formulário geral: With these rules: {rules} And this text: {context} Given the above text, answer the question: {question} Answer: Envie o prompt para a API ChatGPT e deixe o modelo concluir a resposta. Descobrimos que isso funciona muito bem e, combinado com uma temperatura de modelo relativamente baixa (o conceito de temperatura é explicado nesta ), isso tende a produzir resultados e trechos de código corretos, desde que a resposta possa ser encontrada no documentação. postagem do blog Uma limitação importante dessa abordagem é que o prompt criado na segunda etapa acima precisa ter no máximo 4.000 tokens (aproximadamente 3.000 palavras). Isso significa que o primeiro passo, a pesquisa de texto para selecionar os documentos mais relevantes, torna-se muito importante. Se a etapa de pesquisa fizer um bom trabalho e fornecer o contexto correto, o ChatGPT também tende a fazer um bom trabalho ao produzir um resultado correto e direto ao ponto. Então, qual é a melhor maneira de encontrar os conteúdos mais relevantes na documentação? O livro de receitas OpenAI, bem como o blog de Simon, usam o que é chamado de pesquisa semântica. A pesquisa semântica aproveita o modelo de linguagem para gerar incorporações tanto para a pergunta quanto para o conteúdo. Embeddings são matrizes de números que representam o texto em uma série de dimensões. Pedaços de texto que possuem incorporações semelhantes têm um significado semelhante. Isso significa que uma boa estratégia é encontrar as partes do conteúdo que mais se assemelham às incorporações de perguntas. Outra estratégia possível, baseada na pesquisa de palavras-chave mais clássica, é a seguinte: Peça ao ChatGPT para extrair as palavras-chave da pergunta, com um prompt como este: Extract keywords for a search query from the text provided. Add synonyms for words where a more common one exists. Use as palavras-chave fornecidas para executar uma pesquisa de texto livre e escolher os principais resultados Colocando em um único diagrama, os dois métodos ficam assim: Tentamos ambos em nossa documentação e notamos alguns prós e contras. Vamos começar comparando alguns resultados. Ambos são executados no mesmo banco de dados e usam o modelo ChatGPT . Como há aleatoriedade envolvida, executei cada pergunta 2 a 3 vezes e escolhi o que me pareceu o melhor resultado. gpt-3.5-turbo Pergunta: Como instalo o Xata CLI? Resposta com pesquisa vetorial: Responda com pesquisa por palavra-chave: : Ambas as versões forneceram a resposta correta, porém a pesquisa vetorial é um pouco mais completa. Ambos encontraram a página de documentos correta para isso, mas acho que nossa heurística baseada em destaques selecionou um pedaço de texto mais curto no caso da estratégia de palavra-chave. Veredicto Vencedor: pesquisa vetorial. Resultado: 1-0 Pergunta: Como você usa Xata com Deno? Resposta com pesquisa vetorial: Responda com pesquisa por palavra-chave: Resultado decepcionante para a pesquisa de vetores, que de alguma forma perdeu a página dedicada do Deno em nossos documentos. Ele encontrou algum outro conteúdo relevante do Deno, mas não a página que continha o exemplo muito útil. Veredicto: Vencedor: pesquisa por palavra-chave. Pontuação: 1-1 Pergunta: Como posso importar um arquivo CSV com tipos de coluna personalizados? Com pesquisa vetorial: Com pesquisa por palavra-chave: Ambos encontraram a página certa (“Importar um arquivo CSV”), mas a versão de pesquisa por palavra-chave conseguiu obter uma resposta mais completa. Eu fiz isso várias vezes para ter certeza de que não é um acaso. Acho que a diferença vem de como o fragmento de texto é selecionado (ao lado das palavras-chave no caso de pesquisa por palavra-chave, desde o início da página no caso de pesquisa vetorial). Veredicto: Vencedor: pesquisa por palavra-chave. Pontuação: 1-2 Descrição: Como posso filtrar uma tabela chamada Users pela coluna email? Com pesquisa vetorial: Com pesquisa por palavra-chave: A busca de vetores se saiu melhor neste aqui, pois encontrou a página “Filtragem” onde havia mais exemplos que o ChatGPT poderia usar para compor a resposta. A resposta da pesquisa por palavra-chave é sutilmente quebrada, porque usa “consulta” em vez de “filtro” para o nome do método. Veredicto: Vencedor: pesquisa vetorial. Pontuação: 2-2 Pergunta: O que é Xata? Com pesquisa vetorial: Com pesquisa por palavra-chave: Este é um empate, porque ambas as respostas são muito boas. Os dois escolheram páginas diferentes para resumir em uma resposta, mas ambos fizeram um bom trabalho e não consigo escolher um vencedor. Veredicto: Pontuação: 3-3 Configuração e ajuste Este é um exemplo de solicitação Xata usado para pesquisa de palavra-chave: // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "What is Xata?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "If you answer with Markdown snippets, prefer the GitHub flavour.", "Your name is DanGPT" ], "searchType": "keyword", "search": { "fuzziness": 1, "target": [ "slug", { "column": "title", "weight": 4 }, "content", "section", { "column": "keywords", "weight": 4 } ], "boosters": [ { "valueBooster": { "column": "section", "value": "guide", "factor": 18 } } ] } } E isso é o que usamos para a pesquisa de vetores: // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "How do I get a record by id?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "Your name is DanGPT" ], "searchType": "vector", "vectorSearch": { "column": "embeddings", "contentColumn": "content", "filter": { "section": "guide" } } } Como você pode ver, a versão de pesquisa de palavra-chave tem mais configurações, configurando imprecisão e reforços e pesos de coluna. A pesquisa vetorial usa apenas um filtro. Eu chamaria isso de vantagem para a pesquisa por palavra-chave: você tem mais mostradores para ajustar a pesquisa e, portanto, obter melhores respostas. Mas também dá mais trabalho, e os resultados da pesquisa vetorial são muito bons sem esse ajuste. Em nosso caso, já ajustamos a pesquisa por palavra-chave para nossa funcionalidade de pesquisa de documentos. Portanto, não foi necessariamente um trabalho extra e, ao brincar com o ChatGPT, descobrimos melhorias em nossos documentos e pesquisas também. Além disso, o Xata tem uma interface de usuário muito boa para ajustar sua pesquisa de palavras-chave, então o trabalho não foi difícil para começar (planejando uma postagem de blog separada sobre isso). Não há razão para que a pesquisa vetorial não possa ter reforços e pesos de coluna e coisas do gênero, mas ainda não temos isso no Xata e não conheço nenhuma outra solução que torne isso tão fácil quanto fazemos palavra-chave sintonia de busca. E, em geral, há mais arte anterior à pesquisa por palavra-chave, mas é bem possível que a pesquisa vetorial o alcance. Por enquanto, chamarei a pesquisa de palavras-chave de vencedora Pontuação: 3-4 Conveniência Nossa documentação já tinha uma função de pesquisa, dog-fooding Xata, de modo que era bastante simples estender para um bot de bate-papo. O Xata agora também oferece suporte nativo à pesquisa de vetores, mas usá-lo exigia a adição de incorporações para todas as páginas de documentação e descobrir uma boa estratégia de fragmentação. Usamos a API de embeddings OpenAI para produzir os embeddings de texto, que tiveram um custo mínimo. Vencedor: Pesquisa de palavras-chave Pontuação 3-5 Latência A abordagem de pesquisa de palavras-chave precisa de uma ida e volta extra para a API ChatGPT. Isso adiciona em termos de latência ao resultado que começou a ser transmitido na interface do usuário. Pelas minhas medições, isso adiciona cerca de 1,8s de tempo extra. Com pesquisa vetorial: Com pesquisa por palavra-chave: o tempo total e o tempo de download do conteúdo aqui não são relevantes, pois dependem principalmente da duração da resposta gerada. Observe a barra “Aguardando resposta do servidor” (a verde) para comparar. Observação: Vencedor: Pesquisa vetorial Pontuação: 4-5 Custo A versão de pesquisa por palavra-chave precisa fazer uma chamada API extra para a API ChatGPT, por outro lado, a versão de pesquisa vetorial precisa produzir incorporações para todos os documentos no banco de dados mais a pergunta. A menos que estejamos falando de muitos documentos, vou chamar isso de empate. Pontuação: 5-6 Conclusão A pontuação é apertada! No nosso caso, optamos por usar a pesquisa por palavra-chave por enquanto, principalmente porque temos mais maneiras de ajustá-la e, como resultado, ela gera respostas um pouco melhores para o nosso conjunto de perguntas do teste. Além disso, quaisquer melhorias que fizermos na pesquisa beneficiarão automaticamente os casos de uso de pesquisa e bate-papo. À medida que melhoramos nossos recursos de pesquisa vetorial com mais opções de ajuste, podemos mudar para a pesquisa vetorial ou uma abordagem híbrida no futuro. Se você gostaria de configurar um bot de bate-papo semelhante para sua própria documentação ou qualquer tipo de base de conhecimento, você pode implementar facilmente o acima usando o Xata ask endpoint. gratuitamente e junte-se a nós no . Ficarei feliz em ajudá-lo pessoalmente a colocá-lo em funcionamento! Crie uma conta Discord