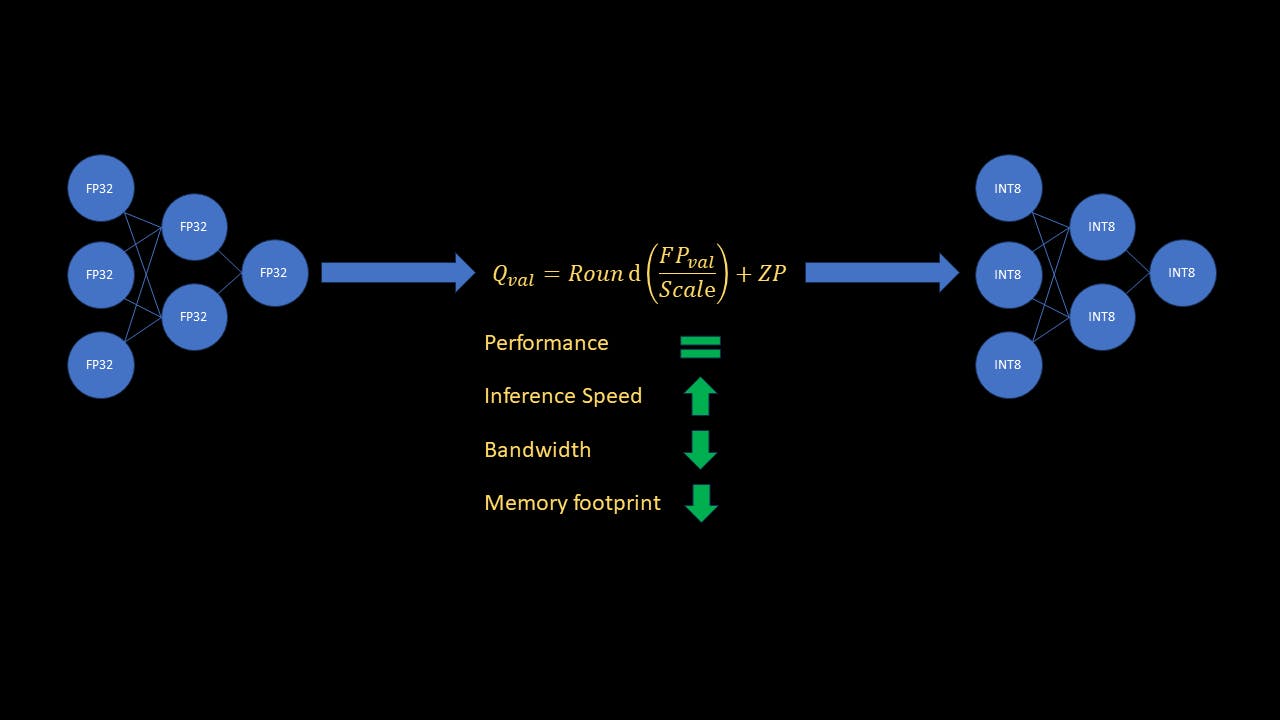
Você sabia que no mundo do aprendizado de máquina, a eficiência dos modelos de Deep Learning (DL) pode ser significativamente aumentada por uma técnica chamada quantização? Imagine reduzir a carga computacional da sua rede neural sem sacrificar seu desempenho. Assim como compactar um arquivo grande sem perder sua essência, a quantização de modelos permite torná-los menores e mais rápidos. Vamos mergulhar no fascinante conceito de quantização e desvendar os segredos da otimização de suas redes neurais para implantação no mundo real. Antes de nos aprofundarmos, os leitores devem estar familiarizados com as redes neurais e o conceito básico de quantização, incluindo os termos escala (S) e ponto zero (ZP). Para leitores que desejam se atualizar, e explicam o amplo conceito e os tipos de quantização. este artigo este artigo Neste guia explicarei brevemente por que a quantização é importante e como implementá-la usando Pytorch. Vou me concentrar principalmente no tipo de quantização chamada “quantização estática pós-treinamento”, que resulta em 4x menos consumo de memória do modelo ML e torna a inferência até 4x mais rápida. Conceitos Por que a quantização é importante? Cálculos de redes neurais são mais comumente realizados com números de ponto flutuante de 32 bits. Um único número de ponto flutuante de 32 bits (FP32) requer 4 bytes de memória. Em comparação, um único número inteiro de 8 bits (INT8) requer apenas 1 byte de memória. Além disso, os computadores processam aritmética inteira muito mais rápido do que operações flutuantes. Imediatamente, você pode ver que quantizar um modelo de ML de FP32 a INT8 resultará em 4x menos memória. Além disso, também irá acelerar a inferência em até 4x! Com modelos grandes sendo a última moda no momento, é importante que os profissionais sejam capazes de otimizar modelos treinados para memória e velocidade para inferência em tempo real. Termos chave Pesos da rede neural treinada. Pesos- Em termos de quantização, as ativações não são funções de ativação como Sigmoid ou ReLU. Por ativações, quero dizer as saídas do mapa de recursos das camadas intermediárias, que são entradas para as próximas camadas. Ativações – Quantização Estática Pós-Treinamento A quantização estática pós-treinamento significa que não precisamos treinar ou ajustar o modelo para quantização após treinar o modelo original. Também não precisamos quantizar as entradas da camada intermediária, chamadas ativações em tempo real. Neste modo de quantização, os pesos são quantizados diretamente calculando a escala e o ponto zero para cada camada. No entanto, para ativações, à medida que a entrada do modelo muda, as ativações também mudam. Não sabemos o intervalo de cada entrada que o modelo encontrará durante a inferência. Então, como podemos calcular a escala e o ponto zero para todas as ativações da rede? Podemos fazer isso calibrando o modelo, usando um bom conjunto de dados representativo. Em seguida, observamos a faixa de valores de ativações para o conjunto de calibração e, em seguida, usamos essas estatísticas para calcular a escala e o ponto zero. Isso é feito inserindo observadores no modelo, que coletam estatísticas de dados durante a calibração. Depois de preparar o modelo (inserir observadores), executamos o avanço do modelo no conjunto de dados de calibração. Os observadores usam esses dados de calibração para calcular a escala e o ponto zero para ativações. Agora a inferência é apenas uma questão de aplicar a transformada linear a todas as camadas com suas respectivas escalas e pontos zero. Embora toda a inferência seja feita no INT8, a saída final do modelo é desquantizada (do INT8 ao FP32). Por que as ativações precisam ser quantizadas se os pesos de entrada e de rede já estão quantizados? Esta é uma excelente pergunta. Embora a entrada e os pesos da rede já sejam valores INT8, a saída da camada é armazenada como INT32, para evitar estouro. Para reduzir a complexidade no processamento da próxima camada, as ativações são quantizadas de INT32 a INT8. Com os conceitos claros, vamos mergulhar no código e ver como funciona! Para este exemplo, usarei um modelo resnet18 ajustado no conjunto de dados Flowers102, disponível diretamente no Pytorch. No entanto, o código funcionará para qualquer CNN treinado, com o conjunto de dados de calibração apropriado. Como este tutorial é focado em quantização, não abordarei a parte de treinamento e ajuste fino. No entanto, todo o código pode ser encontrado . Vamos mergulhar! aqui Código de quantização Vamos importar as bibliotecas necessárias para a quantização e carregar o modelo ajustado. import torch import torchvision import torchvision.transforms as transforms from torchvision.models import resnet18 import torch.nn as nn from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping import warnings warnings.filterwarnings('ignore') A seguir, vamos definir alguns parâmetros, definir transformações e carregadores de dados e carregar o modelo ajustado model_path = 'flowers_model.pth' quantized_model_save_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) # Define train data loader, for using as calibration set trainset = torchvision.datasets.Flowers102(root='./data', split="train", download=True, transform=transform) trainLoader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2) # Load the finetuned resnet model model_to_quantize = resnet18(weights=None) num_features = model_to_quantize.fc.in_features model_to_quantize.fc = nn.Linear(num_features, num_classes) model_to_quantize.load_state_dict(torch.load(model_path)) model_to_quantize.eval() print('Loaded fine-tuned model') Para este exemplo, usarei algumas amostras de treinamento como conjunto de calibração. Agora, vamos definir a configuração utilizada para quantizar o modelo. # Define quantization parameters config for the correct platform, # "x86" for x86 devices or "qnnpack" for arm devices qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) No trecho acima, usei a configuração padrão, mas a classe do Pytorch é usada para descrever como o modelo, ou parte do modelo, deve ser quantizado. Podemos fazer isso especificando o tipo de classes de observadores a serem usadas para pesos e ativações. QConfig Agora estamos prontos para preparar o modelo para quantização # Fuse conv-> relu, conv -> bn -> relu layer blocks and insert observers model_prep = prepare_fx(model=model_to_quantize, qconfig_mapping=qconfig_mapping, example_inputs=torch.randn((1,3,224,224))) A função insere os observadores no modelo e também funde os módulos conv→relu e conv→bn→relu. Isso resulta em menos operações e menor largura de banda de memória devido à não necessidade de armazenar resultados intermediários desses módulos. prepare_fx Calibre o modelo executando a passagem direta nos dados de calibração # Run calibration for 10 batches (100 random samples in total) print('Running calibration') with torch.no_grad(): for i, data in enumerate(trainLoader): samples, labels = data _ = model_prep(samples) if i == 10: break Não precisamos executar a calibração em todo o conjunto de treinamento! Neste exemplo, estou usando 100 amostras aleatórias, mas na prática, você deve escolher um conjunto de dados que seja representativo do que o modelo verá durante a implantação. Quantize o modelo e salve os pesos quantizados! # Quantize calibrated model quantized_model = convert_fx(model_prep) print('Quantized model!') # Save quantized torch.save(quantized_model.state_dict(), quantized_model_save_path) print('Saved quantized model weights to disk') E é isso! Agora vamos ver como carregar um modelo quantizado e, em seguida, comparar a precisão, a velocidade e o consumo de memória dos modelos original e quantizado. Carregar um modelo quantizado Um gráfico de modelo quantizado não é exatamente igual ao modelo original, mesmo que ambos tenham as mesmas camadas. Imprimir a primeira camada ( ) de ambos os modelos mostra a diferença. conv1 print('\nPrinting conv1 layer of fp32 and quantized model') print(f'fp32 model: {model_to_quantize.conv1}') print(f'quantized model: {quantized_model.conv1}') Você notará que junto com as diferentes classes, a camada conv1 do modelo quantizado também contém os parâmetros de escala e ponto zero. Assim, o que precisamos fazer é seguir o processo de quantização (sem calibração) para criar o gráfico do modelo, e então carregar os pesos quantizados. Claro, se salvarmos o modelo quantizado no formato onnx, podemos carregá-lo como qualquer outro modelo onnx, sem executar as funções de quantização todas as vezes. Enquanto isso, vamos definir uma função para carregar o modelo quantizado e salvá-lo em . inference_utils.py import torch from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping def load_quantized_model(model_to_quantize, weights_path): ''' Model only needs to be calibrated for the first time. Next time onwards, to load the quantized model, you still need to prepare and convert the model without calibrating it. After that, load the state dict as usual. ''' model_to_quantize.eval() qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) model_prep = prepare_fx(model_to_quantize, qconfig_mapping, torch.randn((1,3,224,224))) quantized_model = convert_fx(model_prep) quantized_model.load_state_dict(torch.load(weights_path)) return quantized_model Definir funções para medir precisão e velocidade Medir a precisão import torch def test_accuracy(model, testLoader): model.eval() running_acc = 0 num_samples = 0 with torch.no_grad(): for i, data in enumerate(testLoader): samples, labels = data outputs = model(samples) preds = torch.argmax(outputs, 1) running_acc += torch.sum(preds == labels) num_samples += samples.size(0) return running_acc / num_samples Este é um código Pytorch bastante simples. Meça a velocidade de inferência em milissegundos (ms) import torch from time import time def test_speed(model): dummy_sample = torch.randn((1,3,224,224)) # Average out inference speed over multiple iterations # to get a true estimate num_iterations = 100 start = time() for _ in range(num_iterations): _ = model(dummy_sample) end = time() return (end-start)/num_iterations * 1000 Adicione essas duas funções em . Agora estamos prontos para comparar modelos. Vamos examinar o código. inference_utils.py Compare modelos em termos de precisão, velocidade e tamanho Vamos primeiro importar as bibliotecas necessárias, definir parâmetros, transformações de dados e o carregador de dados de teste. import os import torch import torch.nn as nn import torchvision from torchvision.models import resnet18 import torchvision.transforms as transforms from inference_utils import test_accuracy, test_speed, load_quantized_model import copy import warnings warnings.filterwarnings('ignore') model_weights_path = 'flowers_model.pth' quantized_model_weights_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) testset = torchvision.datasets.Flowers102(root='./data', split="test", download=True, transform=transform) testLoader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2) Carregue os dois modelos # Load the finetuned resnet model and the quantized model model = resnet18(weights=None) num_features = model.fc.in_features model.fc = nn.Linear(num_features, num_classes) model.load_state_dict(torch.load(model_weights_path)) model.eval() model_to_quantize = copy.deepcopy(model) quantized_model = load_quantized_model(model_to_quantize, quantized_model_weights_path) Comparar modelos # Compare accuracy fp32_accuracy = test_accuracy(model, testLoader) accuracy = test_accuracy(quantized_model, testLoader) print(f'Original model accuracy: {fp32_accuracy:.3f}') print(f'Quantized model accuracy: {accuracy:.3f}\n') # Compare speed fp32_speed = test_speed(model) quantized_speed = test_speed(quantized_model) print(f'Inference time for original model: {fp32_speed:.3f} ms') print(f'Inference time for quantized model: {quantized_speed:.3f} ms\n') # Compare file size fp32_size = os.path.getsize(model_weights_path)/10**6 quantized_size = os.path.getsize(quantized_model_weights_path)/10**6 print(f'Original model file size: {fp32_size:.3f} MB') print(f'Quantized model file size: {quantized_size:.3f} MB') Resultados Como você pode ver, a precisão do modelo quantizado nos dados de teste é quase igual à precisão do modelo original! A inferência com o modelo quantizado é ~3,6x mais rápida (!) e o modelo quantizado requer ~4x menos memória que o modelo original! Conclusão Neste artigo, entendemos o conceito amplo de quantização de modelo de ML e um tipo de quantização chamada Quantização Estática Pós-Treinamento. Também analisamos por que a quantização é importante e uma ferramenta poderosa na época de grandes modelos. Por fim, analisamos um código de exemplo para quantizar um modelo treinado usando Pytorch e revisamos os resultados. Como os resultados mostraram, a quantização do modelo original não afetou o desempenho e, ao mesmo tempo, diminuiu a velocidade de inferência em aproximadamente 3,6x e reduziu o consumo de memória em aproximadamente 4x! Alguns pontos a serem observados: a quantização estática funciona bem para CNNs, mas a quantização dinâmica é o método preferido para modelos de sequência. Além disso, se a quantização impactar drasticamente o desempenho do modelo, a precisão pode ser recuperada por uma técnica chamada Quantization Aware Training (QAT). Como funcionam a Quantização Dinâmica e o QAT? Essas são postagens para outra hora. Espero que com este guia você tenha o conhecimento necessário para realizar a quantização estática em seus próprios modelos Pytorch. Referências Noções básicas de quantização de modelo Quantização tensorial Conjunto de dados Flores 102 Documentos Pytorch