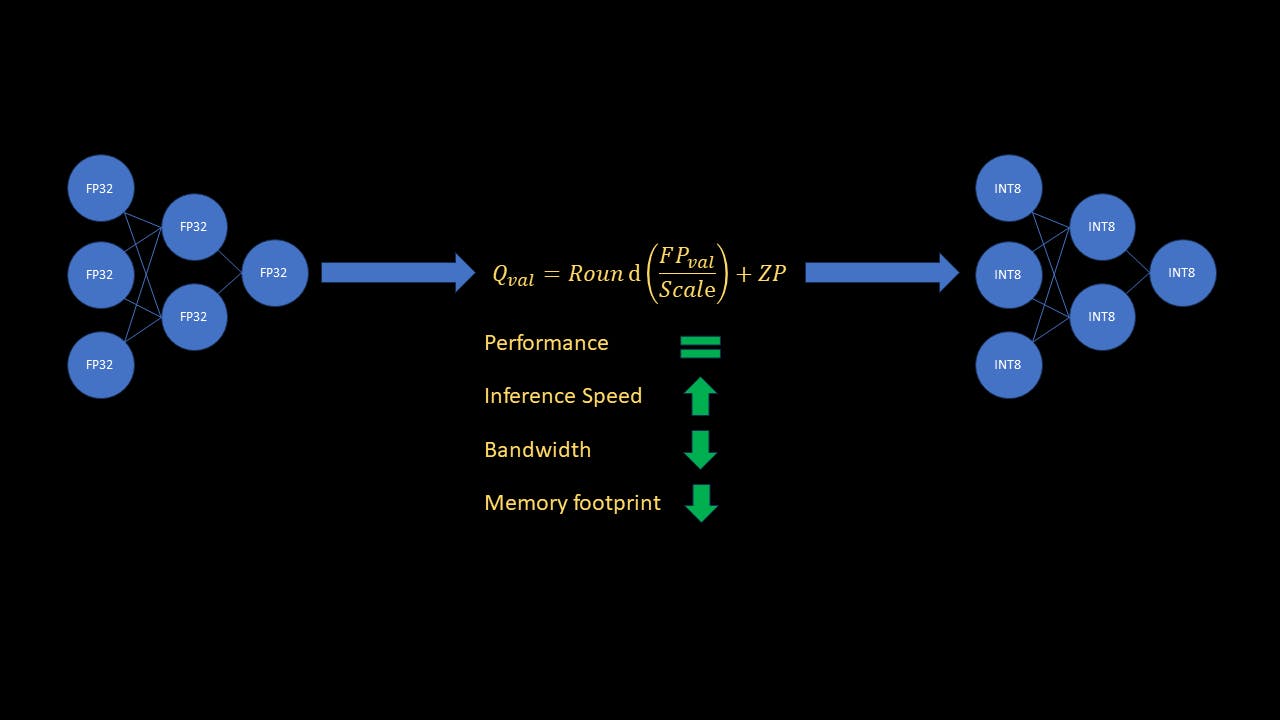
क्या आप जानते हैं कि मशीन लर्निंग की दुनिया में, डीप लर्निंग (डीएल) मॉडल की दक्षता को क्वांटाइजेशन नामक तकनीक द्वारा काफी बढ़ाया जा सकता है? अपने तंत्रिका नेटवर्क के प्रदर्शन से समझौता किए बिना उसके कम्प्यूटेशनल बोझ को कम करने की कल्पना करें। किसी बड़ी फ़ाइल को उसके सार को खोए बिना संपीड़ित करने की तरह, मॉडल परिमाणीकरण आपको अपने मॉडल को छोटा और तेज़ बनाने की अनुमति देता है। आइए परिमाणीकरण की आकर्षक अवधारणा में गोता लगाएँ और वास्तविक दुनिया में तैनाती के लिए अपने तंत्रिका नेटवर्क को अनुकूलित करने के रहस्यों का खुलासा करें। इससे पहले कि हम गहराई से जानें, पाठकों को तंत्रिका नेटवर्क और परिमाणीकरण की मूल अवधारणा से परिचित होना चाहिए, जिसमें स्केल (एस) और शून्य बिंदु (जेडपी) शब्द शामिल हैं। उन पाठकों के लिए जो पुनश्चर्या चाहते हैं, और परिमाणीकरण की व्यापक अवधारणा और प्रकारों की व्याख्या करता है। यह लेख यह लेख इस गाइड में मैं संक्षेप में बताऊंगा कि परिमाणीकरण क्यों मायने रखता है, और पाइटोरच का उपयोग करके इसे कैसे लागू किया जाए। मैं मुख्य रूप से "प्रशिक्षण के बाद स्थैतिक परिमाणीकरण" नामक परिमाणीकरण के प्रकार पर ध्यान केंद्रित करूंगा, जिसके परिणामस्वरूप एमएल मॉडल की मेमोरी फ़ुटप्रिंट 4x कम हो जाती है, और अनुमान 4x तक तेज़ हो जाता है। अवधारणाओं परिमाणीकरण क्यों मायने रखता है? न्यूरल नेटवर्क की गणना आमतौर पर 32 बिट फ्लोटिंग पॉइंट नंबरों के साथ की जाती है। एक 32 बिट फ्लोटिंग पॉइंट नंबर (FP32) के लिए 4 बाइट्स मेमोरी की आवश्यकता होती है। इसकी तुलना में, एक 8 बिट पूर्णांक संख्या (INT8) के लिए केवल 1 बाइट मेमोरी की आवश्यकता होती है। इसके अलावा, कंप्यूटर फ्लोट ऑपरेशन की तुलना में पूर्णांक अंकगणित को बहुत तेजी से संसाधित करते हैं। तुरंत, आप देख सकते हैं कि एमएल मॉडल को FP32 से INT8 तक परिमाणित करने से 4x कम मेमोरी प्राप्त होगी। इसके अलावा, इससे अनुमान लगाने की गति भी 4 गुना तक बढ़ जाएगी! चूंकि बड़े मॉडल इस समय बहुत लोकप्रिय हैं, इसलिए अभ्यासकर्ताओं के लिए यह महत्वपूर्ण है कि वे वास्तविक समय अनुमान के लिए स्मृति और गति के लिए प्रशिक्षित मॉडल को अनुकूलित करने में सक्षम हों। महत्वपूर्ण पदों प्रशिक्षित तंत्रिका नेटवर्क का वज़न। वज़न- परिमाणीकरण के संदर्भ में, सक्रियण सिग्मॉइड या ReLU जैसे सक्रियण कार्य नहीं हैं। सक्रियणों से मेरा तात्पर्य मध्यवर्ती परतों के फीचर मैप आउटपुट से है, जो अगली परतों के लिए इनपुट हैं। सक्रियण- प्रशिक्षण के बाद स्थैतिक परिमाणीकरण प्रशिक्षण के बाद स्थैतिक परिमाणीकरण का मतलब है कि हमें मूल मॉडल को प्रशिक्षित करने के बाद परिमाणीकरण के लिए मॉडल को प्रशिक्षित या परिष्कृत करने की आवश्यकता नहीं है। हमें मध्यवर्ती परत इनपुट को परिमाणित करने की भी आवश्यकता नहीं है, जिसे तुरंत सक्रियण कहा जाता है। परिमाणीकरण की इस विधा में, प्रत्येक परत के लिए पैमाने और शून्य बिंदु की गणना करके वजन को सीधे परिमाणित किया जाता है। हालाँकि, सक्रियणों के लिए, जैसे-जैसे मॉडल में इनपुट बदलता है, सक्रियताएँ भी बदल जाएंगी। हम प्रत्येक इनपुट की सीमा नहीं जानते हैं जिसका मॉडल अनुमान के दौरान सामना करेगा। तो हम नेटवर्क के सभी सक्रियणों के लिए पैमाने और शून्य बिंदु की गणना कैसे कर सकते हैं? हम एक अच्छे प्रतिनिधि डेटासेट का उपयोग करके मॉडल को कैलिब्रेट करके ऐसा कर सकते हैं। फिर हम अंशांकन सेट के लिए सक्रियणों के मूल्यों की सीमा का निरीक्षण करते हैं, और फिर पैमाने और शून्य बिंदु की गणना करने के लिए उन आंकड़ों का उपयोग करते हैं। यह मॉडल में पर्यवेक्षकों को सम्मिलित करके किया जाता है, जो अंशांकन के दौरान डेटा आँकड़े एकत्र करते हैं। मॉडल तैयार करने (पर्यवेक्षकों को सम्मिलित करने) के बाद, हम अंशांकन डेटासेट पर मॉडल का फॉरवर्ड पास चलाते हैं। पर्यवेक्षक इस अंशांकन डेटा का उपयोग सक्रियण के लिए पैमाने और शून्य बिंदु की गणना करने के लिए करते हैं। अब अनुमान केवल सभी परतों पर उनके संबंधित पैमाने और शून्य बिंदुओं के साथ रैखिक परिवर्तन लागू करने का मामला है। जबकि संपूर्ण अनुमान INT8 में किया जाता है, अंतिम मॉडल आउटपुट को डीक्वांटाइज़ किया जाता है (INT8 से FP32 तक)। यदि इनपुट और नेटवर्क भार पहले से ही परिमाणित हैं तो सक्रियणों को परिमाणित करने की आवश्यकता क्यों है? यह एक अच्छा सवाल है। जबकि नेटवर्क इनपुट और वज़न वास्तव में पहले से ही INT8 मान हैं, अतिप्रवाह से बचने के लिए परत का आउटपुट INT32 के रूप में संग्रहीत किया जाता है। अगली परत को संसाधित करने में जटिलता को कम करने के लिए सक्रियणों को INT32 से INT8 तक परिमाणित किया गया है। अवधारणाओं को स्पष्ट करने के साथ, आइए कोड में गोता लगाएँ और देखें कि यह कैसे काम करता है! इस उदाहरण के लिए, मैं फ्लावर्स102 डेटासेट पर फाइन-ट्यून किए गए एक रेसनेट18 मॉडल का उपयोग करूंगा, जो सीधे पाइटोरच में उपलब्ध है। हालाँकि, कोड उपयुक्त अंशांकन डेटासेट के साथ किसी भी प्रशिक्षित सीएनएन के लिए काम करेगा। चूँकि यह ट्यूटोरियल परिमाणीकरण पर केंद्रित है, इसलिए मैं प्रशिक्षण और फ़ाइन-ट्यूनिंग भाग को कवर नहीं करूँगा। हालाँकि, सभी कोड पाए जा सकते हैं। चलो अंदर गोता लगाएँ! यहां परिमाणीकरण कोड आइए हम परिमाणीकरण और सुव्यवस्थित मॉडल को लोड करने के लिए आवश्यक पुस्तकालयों को आयात करें। import torch import torchvision import torchvision.transforms as transforms from torchvision.models import resnet18 import torch.nn as nn from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping import warnings warnings.filterwarnings('ignore') इसके बाद, आइए कुछ मापदंडों को परिभाषित करें, डेटा ट्रांसफॉर्म और डेटा लोडर को परिभाषित करें, और फाइन-ट्यून मॉडल को लोड करें model_path = 'flowers_model.pth' quantized_model_save_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) # Define train data loader, for using as calibration set trainset = torchvision.datasets.Flowers102(root='./data', split="train", download=True, transform=transform) trainLoader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2) # Load the finetuned resnet model model_to_quantize = resnet18(weights=None) num_features = model_to_quantize.fc.in_features model_to_quantize.fc = nn.Linear(num_features, num_classes) model_to_quantize.load_state_dict(torch.load(model_path)) model_to_quantize.eval() print('Loaded fine-tuned model') इस उदाहरण के लिए, मैं अंशांकन सेट के रूप में कुछ प्रशिक्षण नमूनों का उपयोग करूंगा। अब, आइए हम मॉडल को परिमाणित करने के लिए प्रयुक्त कॉन्फ़िगरेशन को परिभाषित करें। # Define quantization parameters config for the correct platform, # "x86" for x86 devices or "qnnpack" for arm devices qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) उपरोक्त स्निपेट में, मैंने डिफ़ॉल्ट कॉन्फ़िगरेशन का उपयोग किया है, लेकिन पाइटोरच के वर्ग का उपयोग यह वर्णन करने के लिए किया जाता है कि मॉडल, या मॉडल के एक हिस्से को कैसे परिमाणित किया जाना चाहिए। हम वज़न और सक्रियण के लिए उपयोग किए जाने वाले पर्यवेक्षक वर्गों के प्रकार को निर्दिष्ट करके ऐसा कर सकते हैं। QConfig अब हम परिमाणीकरण के लिए मॉडल तैयार करने के लिए तैयार हैं # Fuse conv-> relu, conv -> bn -> relu layer blocks and insert observers model_prep = prepare_fx(model=model_to_quantize, qconfig_mapping=qconfig_mapping, example_inputs=torch.randn((1,3,224,224))) फ़ंक्शन पर्यवेक्षकों को मॉडल में सम्मिलित करता है, और conv→relu और conv→bn→relu मॉड्यूल को फ़्यूज़ भी करता है। इसके परिणामस्वरूप उन मॉड्यूल के मध्यवर्ती परिणामों को संग्रहीत करने की आवश्यकता नहीं होने के कारण कम संचालन और कम मेमोरी बैंडविड्थ होती है। prepare_fx अंशांकन डेटा पर फॉरवर्ड पास चलाकर मॉडल को अंशांकित करें # Run calibration for 10 batches (100 random samples in total) print('Running calibration') with torch.no_grad(): for i, data in enumerate(trainLoader): samples, labels = data _ = model_prep(samples) if i == 10: break हमें संपूर्ण प्रशिक्षण सेट पर अंशांकन चलाने की आवश्यकता नहीं है! इस उदाहरण में, मैं 100 यादृच्छिक नमूनों का उपयोग कर रहा हूं, लेकिन व्यवहार में, आपको एक ऐसा डेटासेट चुनना चाहिए जो इस बात का प्रतिनिधि हो कि मॉडल तैनाती के दौरान क्या देखेगा। मॉडल को परिमाणित करें और परिमाणित वजन को बचाएं! # Quantize calibrated model quantized_model = convert_fx(model_prep) print('Quantized model!') # Save quantized torch.save(quantized_model.state_dict(), quantized_model_save_path) print('Saved quantized model weights to disk') और बस! आइए अब देखें कि क्वांटाइज्ड मॉडल को कैसे लोड किया जाए, और फिर मूल और क्वांटाइज्ड मॉडल की सटीकता, गति और मेमोरी फ़ुटप्रिंट की तुलना करें। एक परिमाणित मॉडल लोड करें एक परिमाणित मॉडल ग्राफ़ मूल मॉडल के समान नहीं है, भले ही दोनों की परतें समान हों। दोनों मॉडलों की पहली परत ( ) को प्रिंट करने से अंतर पता चलता है। conv1 print('\nPrinting conv1 layer of fp32 and quantized model') print(f'fp32 model: {model_to_quantize.conv1}') print(f'quantized model: {quantized_model.conv1}') आप देखेंगे कि विभिन्न वर्ग के साथ-साथ, परिमाणित मॉडल की conv1 परत में स्केल और शून्य बिंदु पैरामीटर भी शामिल हैं। इस प्रकार, हमें मॉडल ग्राफ़ बनाने के लिए परिमाणीकरण प्रक्रिया (अंशांकन के बिना) का पालन करना होगा, और फिर परिमाणित भार को लोड करना होगा। निःसंदेह, यदि हम परिमाणित मॉडल को ओएनएक्स प्रारूप में सहेजते हैं, तो हम इसे किसी भी अन्य ओएनएक्स मॉडल की तरह लोड कर सकते हैं, हर बार परिमाणीकरण कार्यों को चलाए बिना। इस बीच, आइए हम परिमाणित मॉडल को लोड करने के लिए एक फ़ंक्शन को परिभाषित करें और इसे में सहेजें। inference_utils.py import torch from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping def load_quantized_model(model_to_quantize, weights_path): ''' Model only needs to be calibrated for the first time. Next time onwards, to load the quantized model, you still need to prepare and convert the model without calibrating it. After that, load the state dict as usual. ''' model_to_quantize.eval() qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) model_prep = prepare_fx(model_to_quantize, qconfig_mapping, torch.randn((1,3,224,224))) quantized_model = convert_fx(model_prep) quantized_model.load_state_dict(torch.load(weights_path)) return quantized_model सटीकता और गति को मापने के लिए कार्यों को परिभाषित करें सटीकता मापें import torch def test_accuracy(model, testLoader): model.eval() running_acc = 0 num_samples = 0 with torch.no_grad(): for i, data in enumerate(testLoader): samples, labels = data outputs = model(samples) preds = torch.argmax(outputs, 1) running_acc += torch.sum(preds == labels) num_samples += samples.size(0) return running_acc / num_samples यह एक बहुत ही सीधा पाइटोरच कोड है। अनुमान गति को मिलीसेकंड (एमएस) में मापें import torch from time import time def test_speed(model): dummy_sample = torch.randn((1,3,224,224)) # Average out inference speed over multiple iterations # to get a true estimate num_iterations = 100 start = time() for _ in range(num_iterations): _ = model(dummy_sample) end = time() return (end-start)/num_iterations * 1000 इन दोनों फ़ंक्शन को में जोड़ें। अब हम मॉडलों की तुलना करने के लिए तैयार हैं। आइए कोड के माध्यम से चलते हैं। inference_utils.py सटीकता, गति और आकार के लिए मॉडलों की तुलना करें आइए पहले आवश्यक पुस्तकालयों को आयात करें, पैरामीटर, डेटा ट्रांसफ़ॉर्म और परीक्षण डेटालोडर को परिभाषित करें। import os import torch import torch.nn as nn import torchvision from torchvision.models import resnet18 import torchvision.transforms as transforms from inference_utils import test_accuracy, test_speed, load_quantized_model import copy import warnings warnings.filterwarnings('ignore') model_weights_path = 'flowers_model.pth' quantized_model_weights_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) testset = torchvision.datasets.Flowers102(root='./data', split="test", download=True, transform=transform) testLoader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2) दो मॉडल लोड करें # Load the finetuned resnet model and the quantized model model = resnet18(weights=None) num_features = model.fc.in_features model.fc = nn.Linear(num_features, num_classes) model.load_state_dict(torch.load(model_weights_path)) model.eval() model_to_quantize = copy.deepcopy(model) quantized_model = load_quantized_model(model_to_quantize, quantized_model_weights_path) मॉडलों की तुलना करें # Compare accuracy fp32_accuracy = test_accuracy(model, testLoader) accuracy = test_accuracy(quantized_model, testLoader) print(f'Original model accuracy: {fp32_accuracy:.3f}') print(f'Quantized model accuracy: {accuracy:.3f}\n') # Compare speed fp32_speed = test_speed(model) quantized_speed = test_speed(quantized_model) print(f'Inference time for original model: {fp32_speed:.3f} ms') print(f'Inference time for quantized model: {quantized_speed:.3f} ms\n') # Compare file size fp32_size = os.path.getsize(model_weights_path)/10**6 quantized_size = os.path.getsize(quantized_model_weights_path)/10**6 print(f'Original model file size: {fp32_size:.3f} MB') print(f'Quantized model file size: {quantized_size:.3f} MB') परिणाम जैसा कि आप देख सकते हैं, परीक्षण डेटा पर परिमाणित मॉडल की सटीकता लगभग मूल मॉडल की सटीकता जितनी है! परिमाणित मॉडल के साथ अनुमान ~3.6x तेज (!) है और परिमाणित मॉडल के लिए मूल मॉडल की तुलना में ~4x कम मेमोरी की आवश्यकता होती है! निष्कर्ष इस लेख में, हमने एमएल मॉडल क्वांटाइजेशन की व्यापक अवधारणा और पोस्ट ट्रेनिंग स्टेटिक क्वांटाइजेशन नामक एक प्रकार के क्वांटाइजेशन को समझा। हमने यह भी देखा कि बड़े मॉडलों के समय में परिमाणीकरण क्यों महत्वपूर्ण और एक शक्तिशाली उपकरण है। अंत में, हमने पाइटोरच का उपयोग करके एक प्रशिक्षित मॉडल को परिमाणित करने के लिए उदाहरण कोड का अध्ययन किया और परिणामों की समीक्षा की। जैसा कि परिणामों से पता चला, मूल मॉडल को परिमाणित करने से प्रदर्शन पर कोई प्रभाव नहीं पड़ा, और साथ ही अनुमान की गति ~3.6x कम हो गई और मेमोरी फ़ुटप्रिंट ~4x कम हो गया! ध्यान देने योग्य कुछ बिंदु- स्थैतिक परिमाणीकरण सीएनएन के लिए अच्छा काम करता है, लेकिन गतिशील परिमाणीकरण अनुक्रम मॉडल के लिए पसंदीदा तरीका है। इसके अतिरिक्त, यदि परिमाणीकरण मॉडल के प्रदर्शन पर भारी प्रभाव डालता है, तो सटीकता को क्वांटाइजेशन अवेयर ट्रेनिंग (क्यूएटी) नामक तकनीक द्वारा पुनः प्राप्त किया जा सकता है। डायनामिक क्वांटाइज़ेशन और QAT कैसे काम करते हैं? वे किसी और समय के लिए पोस्ट हैं। मुझे आशा है कि इस गाइड के साथ, आपको अपने स्वयं के पाइटोरच मॉडल पर स्थैतिक परिमाणीकरण करने का ज्ञान प्रदान किया जाएगा। संदर्भ मॉडल परिमाणीकरण की मूल बातें टेन्सर परिमाणीकरण फूल 102 डेटासेट पाइटोरच डॉक्स