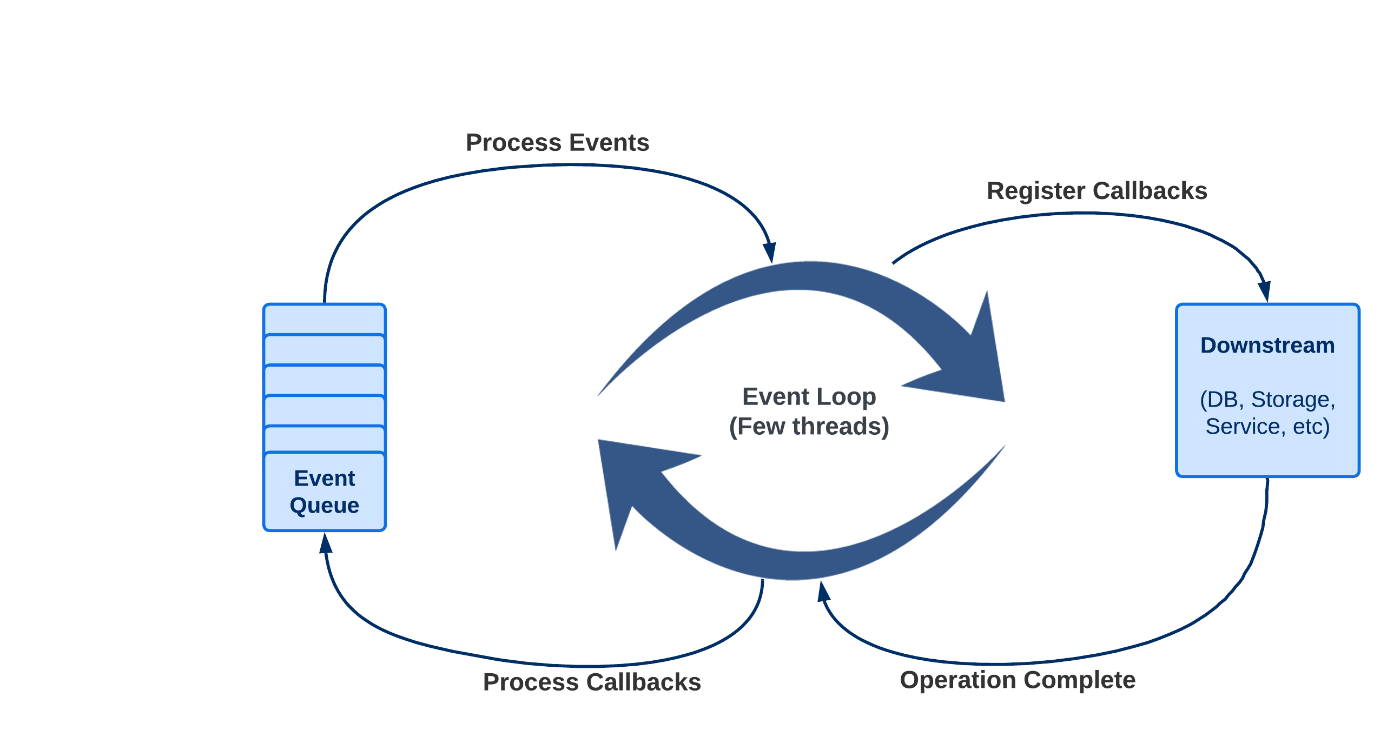
Spring est un framework Web réactif et non bloquant pour la création d'applications Web modernes et évolutives en Java. Il fait partie du Spring Framework et utilise la bibliothèque Reactor pour implémenter la programmation réactive en Java. WebFlux Avec WebFlux, vous pouvez créer des applications Web hautes performances et évolutives capables de gérer un grand nombre de requêtes et de flux de données simultanés. Il prend en charge un large éventail de cas d'utilisation, des API REST simples au streaming de données en temps réel et aux événements envoyés par le serveur. Spring WebFlux fournit un modèle de programmation basé sur des flux réactifs, qui vous permet de composer des opérations asynchrones et non bloquantes dans un pipeline d'étapes de traitement de données. Il fournit également un riche ensemble de fonctionnalités et d'outils pour créer des applications Web réactives, y compris la prise en charge de l'accès réactif aux données, de la sécurité réactive et des tests réactifs. Extrait de la : documentation officielle de Spring Le terme « réactif » fait référence aux modèles de programmation qui sont construits autour de la réaction au changement : les composants réseau réagissent aux événements d'E/S, les contrôleurs d'interface utilisateur réagissent aux événements de souris, etc. En ce sens, le non-blocage est réactif, car, au lieu d'être bloqué, nous sommes maintenant en mode de réaction aux notifications lorsque les opérations sont terminées ou que les données deviennent disponibles. Modèle de filetage L'une des principales caractéristiques de la programmation réactive est son modèle de threading, qui est différent du modèle traditionnel de thread par requête utilisé dans de nombreux frameworks Web synchrones. Dans le modèle traditionnel, un nouveau thread est créé pour gérer chaque requête entrante, et ce thread est bloqué jusqu'à ce que la requête ait été traitée. Cela peut entraîner des problèmes d'évolutivité lors du traitement de volumes élevés de demandes, car le nombre de threads requis pour gérer les demandes peut devenir très important et le changement de contexte de thread peut devenir un goulot d'étranglement. En revanche, WebFlux utilise un modèle non bloquant, piloté par les événements, dans lequel un petit nombre de threads peut gérer un grand nombre de requêtes. Lorsqu'une requête arrive, elle est gérée par l'un des threads disponibles, qui délègue ensuite le traitement réel à un ensemble de tâches asynchrones. Ces tâches sont exécutées de manière non bloquante, ce qui permet au thread de passer à la gestion d'autres requêtes pendant que les tâches sont exécutées en arrière-plan. Dans Spring WebFlux (et les serveurs non bloquants en général), on suppose que les applications ne bloquent pas. Par conséquent, les serveurs non bloquants utilisent un petit pool de threads de taille fixe (travailleurs de boucle d'événements) pour gérer les requêtes. Le modèle de threading simplifié d'un conteneur de servlet classique ressemble à : Bien que le traitement des requêtes WebFlux soit légèrement différent : Sous la capuche Allons-y et voyons ce qui se cache derrière la théorie brillante. Nous avons besoin d'une application assez minimaliste générée par . Le code est disponible dans le . Spring Initializr dépôt GitHub Tous les sujets liés aux threads dépendent beaucoup du processeur. Habituellement, le nombre de threads de traitement qui gèrent les requêtes est lié au nombre de À des fins éducatives, vous pouvez facilement manipuler le nombre de threads dans un pool en limitant les CPU lors de l'exécution du conteneur Docker : cœurs de processeur . docker run --cpus=1 -d --rm --name webflux-threading -p 8081:8080 local/webflux-threading Si vous voyez toujours plus d'un thread dans un pool, ce n'est pas grave. Il peut y avoir définies par WebFlux. des valeurs par défaut Notre application est une simple diseuse de bonne aventure. En appelant endpoint, vous obtiendrez 5 enregistrements avec . Chaque ajustement est un nombre entier qui représente un karma qui vous est donné. Oui, nous sommes très généreux car l'application ne génère que des nombres positifs. Plus de malchance ! /karma balanceAdjustment Traitement par défaut Commençons par un exemple très basique. La méthode de contrôleur suivante renvoie un flux contenant 5 éléments de karma. @GetMapping("/karma") public Flux<Karma> karma() { return prepareKarma() .map(Karma::new) .log(); } private Flux<Integer> prepareKarma() { Random random = new Random(); return Flux.fromStream( Stream.generate(() -> random.nextInt(10)) .limit(5)); } La méthode est une chose cruciale ici. Il observe tous les signaux Reactive Streams et les trace dans des journaux sous le niveau INFO. log La sortie des journaux sur curl est la suivante : localhost:8081/karma Comme nous pouvons le voir, le traitement se produit sur le pool de threads IO. Le nom du fil signifie . Les tâches étaient exécutées immédiatement sur un thread qui les soumettait. Reactor n'a vu aucune instruction pour les programmer sur un autre pool. ctor-http-nio-2 reactor-http-nio-2 Retard et traitement parallèle La prochaine opération va retarder chaque élément émettant de 100ms (alias émulation de base de données) @GetMapping("/delayedKarma") public Flux<Karma> delayedKarma() { return karma() .delayElements(Duration.ofMillis(100)); } Nous n'avons pas besoin d'ajouter la méthode ici car elle a déjà été déclarée dans l'appel d'origine. log karma() Dans les journaux, nous pouvons voir l'image suivante : Cette fois, seul le tout premier élément a été reçu sur le fil d'E/S . Le traitement des 4 autres était dédié à un pool de threads . reactor-http-nio-4 parallel Javadoc de le confirme : delayElements Les signaux sont retardés et continuent sur le planificateur parallèle par défaut Vous pouvez obtenir le même effet sans délai en spécifiant n'importe où dans la chaîne d'appel. .subscribeOn(Schedulers.parallel()) L'utilisation du planificateur peut améliorer les performances et l'évolutivité en permettant l'exécution simultanée de plusieurs tâches sur différents threads, ce qui peut mieux utiliser les ressources du processeur et gérer un grand nombre de demandes simultanées. parallel Cependant, cela peut également augmenter la complexité du code et l'utilisation de la mémoire, et potentiellement conduire à l'épuisement du pool de threads si le nombre maximal de threads de travail est dépassé. Par conséquent, la décision d'utiliser un pool de threads doit être basée sur les exigences spécifiques et les compromis de l'application. parallel Sous-chaîne Voyons maintenant un exemple plus complexe. Le code est toujours assez simple et direct, mais la sortie est bien plus intéressante. Nous allons utiliser une et rendre une diseuse de bonne aventure plus . Pour chaque instance de Karma, il multipliera l'ajustement d'origine par 10 et générera les ajustements opposés, créant ainsi une transaction équilibrée qui compense celle d'origine. flatMap juste @GetMapping("/fairKarma") public Flux<Karma> fairKarma() { return delayedKarma() .flatMap(this::makeFair); } private Flux<Karma> makeFair(Karma original) { return Flux.just(new Karma(original.balanceAdjustment() * 10), new Karma(original.balanceAdjustment() * -10)) .subscribeOn(Schedulers.boundedElastic()) .log(); } Comme vous le voyez, le Flux doit être abonné à un pool de threads . Vérifions ce que nous avons dans les journaux pour les deux premiers Karmas : makeFair's boundedElastic Reactor s'abonne au premier élément avec sur le thread IO balanceAdjustment=9 Ensuite, le pool fonctionne sur l'équité Karma en émettant des ajustements et sur le thread boundedElastic 90 -90 boundedElastic-1 Les éléments après le premier sont abonnés sur le pool de threads parallèles (car nous avons encore dans la chaîne) delayedElements planificateur Qu'est-ce qu'un boundedElastic ? Il s'agit d'un pool de threads qui ajuste dynamiquement le nombre de threads de travail en fonction de la charge de travail. Il est optimisé pour les tâches liées aux E/S, telles que les requêtes de base de données et les requêtes réseau, et est conçu pour gérer un grand nombre de tâches de courte durée sans créer trop de threads ni gaspiller de ressources. Par défaut, le pool de threads une taille maximale du nombre de processeurs disponibles multiplié par 10, mais vous pouvez le configurer pour utiliser une taille maximale différente si nécessaire boundedElastic a En utilisant un pool de threads asynchrones comme , vous pouvez décharger des tâches sur des threads séparés et libérer le thread principal pour gérer d'autres requêtes. La nature limitée du pool de threads peut empêcher la famine des threads et l'utilisation excessive des ressources, tandis que l'élasticité du pool lui permet d'ajuster dynamiquement le nombre de threads de travail en fonction de la charge de travail. boundedElastic Autres types de pools de threads Il existe deux autres types de pools fournis par la classe prête à l'emploi, tels que : Scheduler : il s'agit d'un contexte d'exécution sérialisé à thread unique conçu pour une exécution synchrone. Il est utile lorsque vous devez vous assurer qu'une tâche est exécutée dans l'ordre et qu'aucune tâche n'est exécutée simultanément. single : il s'agit d'une implémentation triviale et sans opération d'un planificateur qui exécute immédiatement des tâches sur le thread appelant sans aucun changement de thread. immediate Conclusion Le modèle de threading dans Spring WebFlux est conçu pour être non bloquant et asynchrone, permettant une gestion efficace d'un grand nombre de requêtes avec une utilisation minimale des ressources. Au lieu de s'appuyer sur des threads dédiés par connexion, WebFlux utilise un petit nombre de threads de boucle d'événements pour gérer les demandes entrantes et distribuer le travail aux threads de travail à partir de divers pools de threads. Cependant, il est important de choisir le bon pool de threads pour votre cas d'utilisation afin d'éviter la famine des threads et d'assurer une utilisation efficace des ressources système.