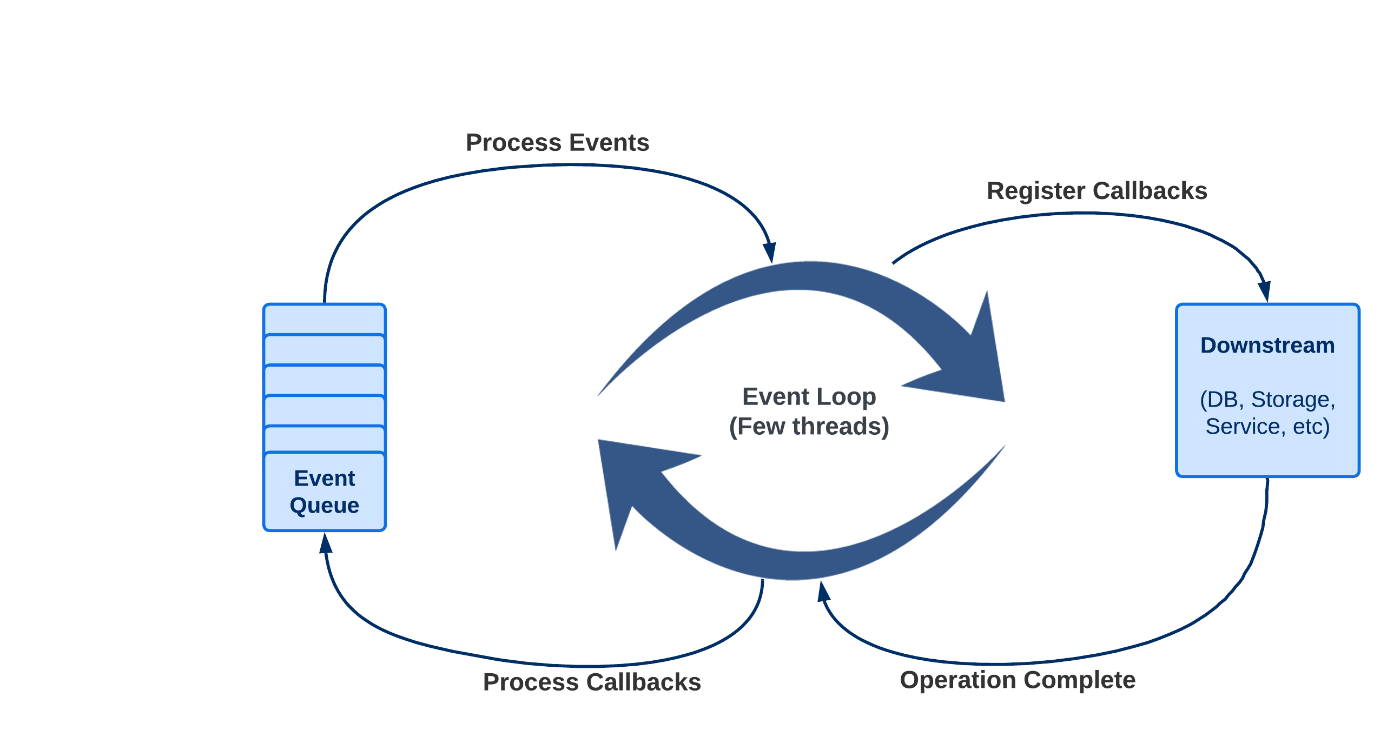
Spring ist ein reaktives, nicht blockierendes Webframework zum Erstellen moderner, skalierbarer Webanwendungen in Java. Es ist Teil des Spring Frameworks und nutzt die Reactor-Bibliothek zur Implementierung reaktiver Programmierung in Java. WebFlux Mit WebFlux können Sie leistungsstarke, skalierbare Webanwendungen erstellen, die eine große Anzahl gleichzeitiger Anfragen und Datenströme verarbeiten können. Es unterstützt eine Vielzahl von Anwendungsfällen, von einfachen REST-APIs bis hin zu Echtzeit-Datenstreaming und vom Server gesendeten Ereignissen. Spring WebFlux bietet ein auf reaktiven Streams basierendes Programmiermodell, mit dem Sie asynchrone und nicht blockierende Vorgänge in einer Pipeline von Datenverarbeitungsstufen zusammenfassen können. Es bietet außerdem zahlreiche Funktionen und Tools zum Erstellen reaktiver Webanwendungen, einschließlich Unterstützung für reaktiven Datenzugriff, reaktive Sicherheit und reaktives Testen. Aus dem : offiziellen Spring-Dokument Der Begriff „reaktiv“ bezieht sich auf Programmiermodelle, die darauf basieren, auf Änderungen zu reagieren – Netzwerkkomponenten reagieren auf E/A-Ereignisse, UI-Controller reagieren auf Mausereignisse und andere. In diesem Sinne ist die Nichtblockierung reaktiv, denn anstatt blockiert zu werden, reagieren wir jetzt auf Benachrichtigungen, wenn Vorgänge abgeschlossen sind oder Daten verfügbar werden. Threading-Modell Eines der Kernmerkmale der reaktiven Programmierung ist ihr Threading-Modell, das sich vom herkömmlichen Thread-pro-Anfrage-Modell unterscheidet, das in vielen synchronen Web-Frameworks verwendet wird. Im traditionellen Modell wird ein neuer Thread erstellt, um jede eingehende Anfrage zu bearbeiten, und dieser Thread wird blockiert, bis die Anfrage verarbeitet wurde. Dies kann bei der Verarbeitung großer Anfragemengen zu Skalierbarkeitsproblemen führen, da die Anzahl der für die Bearbeitung der Anfragen erforderlichen Threads sehr groß werden kann und der Thread-Kontextwechsel zu einem Engpass werden kann. Im Gegensatz dazu verwendet WebFlux ein nicht blockierendes, ereignisgesteuertes Modell, bei dem eine kleine Anzahl von Threads eine große Anzahl von Anfragen bearbeiten kann. Wenn eine Anfrage eingeht, wird sie von einem der verfügbaren Threads bearbeitet, der dann die eigentliche Verarbeitung an eine Reihe asynchroner Aufgaben delegiert. Diese Aufgaben werden nicht blockierend ausgeführt, sodass der Thread andere Anforderungen bearbeiten kann, während die Aufgaben im Hintergrund ausgeführt werden. In Spring WebFlux (und nicht blockierenden Servern im Allgemeinen) wird davon ausgegangen, dass Anwendungen nicht blockieren. Daher verwenden nicht blockierende Server einen kleinen Thread-Pool mit fester Größe (Event-Loop-Worker), um Anfragen zu verarbeiten. Das vereinfachte Threading-Modell eines klassischen Servlet-Containers sieht folgendermaßen aus: Während die Verarbeitung von WebFlux-Anfragen etwas anders ist: Unter der Haube Lassen Sie uns weitermachen und sehen, was hinter der glänzenden Theorie steckt. Wir brauchen eine ziemlich minimalistische App, die von generiert wird. Der Code ist im verfügbar. Spring Initializr GitHub-Repo Alle Thread-bezogenen Themen sind sehr CPU-abhängig. Normalerweise hängt die Anzahl der Verarbeitungsthreads, die Anforderungen bearbeiten, von der Anzahl der ab Zu Bildungszwecken können Sie die Anzahl der Threads in einem Pool einfach manipulieren, indem Sie die CPUs begrenzen, wenn der Docker-Container ausgeführt wird: CPU-Kerne . docker run --cpus=1 -d --rm --name webflux-threading -p 8081:8080 local/webflux-threading Wenn Sie immer noch mehr als einen Thread in einem Pool sehen, ist das kein Problem. Möglicherweise werden von WebFlux festgelegt. Standardeinstellungen Unsere App ist eine einfache Wahrsagerin. Durch den Aufruf von endpoint erhalten Sie 5 Datensätze mit . Jede Anpassung ist eine ganze Zahl, die ein Ihnen gegebenes Karma darstellt. Ja, wir sind sehr großzügig, da die App nur positive Zahlen generiert. Kein Pech mehr! /karma balanceAdjustment Standardverarbeitung Beginnen wir mit einem sehr einfachen Beispiel. Die nächste Controller-Methode gibt einen Flux zurück, der 5 Karma-Elemente enthält. @GetMapping("/karma") public Flux<Karma> karma() { return prepareKarma() .map(Karma::new) .log(); } private Flux<Integer> prepareKarma() { Random random = new Random(); return Flux.fromStream( Stream.generate(() -> random.nextInt(10)) .limit(5)); } Methode ist hier von entscheidender Bedeutung. Es beobachtet alle Reactive Streams-Signale und verfolgt sie in Protokollen auf der INFO-Ebene. log Die Protokollausgabe auf „curl lautet wie folgt: localhost:8081/karma Wie wir sehen können, findet die Verarbeitung im IO-Thread-Pool statt. Threadname steht für . Aufgaben wurden sofort in einem Thread ausgeführt, der sie übermittelt hat. Reactor hat keine Anweisungen gesehen, sie in einem anderen Pool einzuplanen. ctor-http-nio-2 reactor-http-nio-2 Verzögerung und Parallelverarbeitung Der nächste Vorgang wird die Ausgabe jedes Elements um 100 ms verzögern (auch bekannt als Datenbankemulation). @GetMapping("/delayedKarma") public Flux<Karma> delayedKarma() { return karma() .delayElements(Duration.ofMillis(100)); } Wir müssen hier nicht hinzufügen, da sie bereits im ursprünglichen Aufruf deklariert wurde. log karma() In den Protokollen können wir das nächste Bild sehen: Diesmal wurde nur das allererste Element im IO-Thread empfangen. Die Verarbeitung der restlichen 4 war einem Thread-Pool gewidmet. reactor-http-nio-4 parallel Javadoc von bestätigt dies: delayElements Signale werden verzögert und im parallelen Standard-Scheduler fortgesetzt Sie können den gleichen Effekt ohne Verzögerung erzielen, indem Sie an einer beliebigen Stelle in der Aufrufkette angeben. .subscribeOn(Schedulers.parallel()) Die Verwendung Schedulers kann die Leistung und Skalierbarkeit verbessern, indem er die gleichzeitige Ausführung mehrerer Aufgaben in verschiedenen Threads ermöglicht, wodurch CPU-Ressourcen besser genutzt und eine große Anzahl gleichzeitiger Anforderungen verarbeitet werden können. parallel Es kann jedoch auch die Komplexität des Codes und die Speichernutzung erhöhen und möglicherweise zur Erschöpfung des Thread-Pools führen, wenn die maximale Anzahl von Arbeitsthreads überschritten wird. Daher sollte die Entscheidung für die Verwendung Thread-Pools auf den spezifischen Anforderungen und Kompromissen der Anwendung basieren. parallel Unterkette Schauen wir uns nun ein komplexeres Beispiel an. Der Code ist immer noch ziemlich einfach und unkompliziert, aber die Ausgabe ist viel interessanter. Wir werden eine verwenden und eine Wahrsagerin machen. Für jede Karma-Instanz wird die ursprüngliche Anpassung mit 10 multipliziert und die entgegengesetzten Anpassungen generiert, wodurch effektiv eine ausgeglichene Transaktion entsteht, die die ursprüngliche Anpassung ausgleicht. flatMap fairer @GetMapping("/fairKarma") public Flux<Karma> fairKarma() { return delayedKarma() .flatMap(this::makeFair); } private Flux<Karma> makeFair(Karma original) { return Flux.just(new Karma(original.balanceAdjustment() * 10), new Karma(original.balanceAdjustment() * -10)) .subscribeOn(Schedulers.boundedElastic()) .log(); } Wie Sie sehen, sollte Flux in einem Thread-Pool abonniert werden. Schauen wir uns an, was wir in den Protokollen der ersten beiden Karmas haben: makeFair's boundedElastic Der Reaktor abonniert das erste Element mit im E/A-Thread balanceAdjustment=9 Dann arbeitet der Pool an der Karma-Fairness, indem er und Anpassungen im Thread ausgibt boundedElastic 90 -90 boundedElastic-1 Elemente nach dem ersten werden im parallelen Thread-Pool abonniert (da wir immer noch in der Kette haben) delayedElements Was ist ein boundedElastic -Scheduler? Es handelt sich um einen Thread-Pool, der die Anzahl der Worker-Threads basierend auf der Arbeitslast dynamisch anpasst. Es ist für I/O-gebundene Aufgaben wie Datenbankabfragen und Netzwerkanforderungen optimiert und darauf ausgelegt, eine große Anzahl kurzlebiger Aufgaben zu bewältigen, ohne zu viele Threads zu erstellen oder Ressourcen zu verschwenden. Standardmäßig der Thread-Pool eine maximale Größe, die der Anzahl der verfügbaren Prozessoren multipliziert mit 10 entspricht. Sie können ihn jedoch bei Bedarf so konfigurieren, dass eine andere maximale Größe verwendet wird hat boundedElastic Durch die Verwendung eines asynchronen Thread-Pools wie können Sie Aufgaben auf separate Threads auslagern und den Haupt-Thread für die Bearbeitung anderer Anforderungen freigeben. Die begrenzte Beschaffenheit des Thread-Pools kann Thread-Hunger und übermäßige Ressourcennutzung verhindern, während die Elastizität des Pools es ihm ermöglicht, die Anzahl der Arbeitsthreads dynamisch an die Arbeitslast anzupassen. boundedElastic Andere Arten von Thread-Pools Es gibt zwei weitere Arten von Pools, die von der sofort einsatzbereiten Klasse bereitgestellt werden, z. B.: Scheduler- : Dies ist ein Single-Threaded-serialisierter Ausführungskontext, der für die synchrone Ausführung konzipiert ist. Dies ist nützlich, wenn Sie sicherstellen müssen, dass eine Aufgabe in der richtigen Reihenfolge ausgeführt wird und dass nicht zwei Aufgaben gleichzeitig ausgeführt werden. single : Dies ist eine triviale No-Op-Implementierung eines Schedulers, der Aufgaben im aufrufenden Thread sofort ausführt, ohne dass der Thread gewechselt werden muss. immediate Abschluss Das Threading-Modell in Spring WebFlux ist so konzipiert, dass es nicht blockierend und asynchron ist und eine effiziente Bearbeitung einer großen Anzahl von Anfragen bei minimalem Ressourcenverbrauch ermöglicht. Anstatt sich auf dedizierte Threads pro Verbindung zu verlassen, verwendet WebFlux eine kleine Anzahl von Ereignisschleifen-Threads, um eingehende Anforderungen zu verarbeiten und die Arbeit an Arbeitsthreads aus verschiedenen Thread-Pools zu verteilen. Es ist jedoch wichtig, den richtigen Thread-Pool für Ihren Anwendungsfall auszuwählen, um Thread-Aushungerung zu vermeiden und eine effiziente Nutzung der Systemressourcen sicherzustellen.