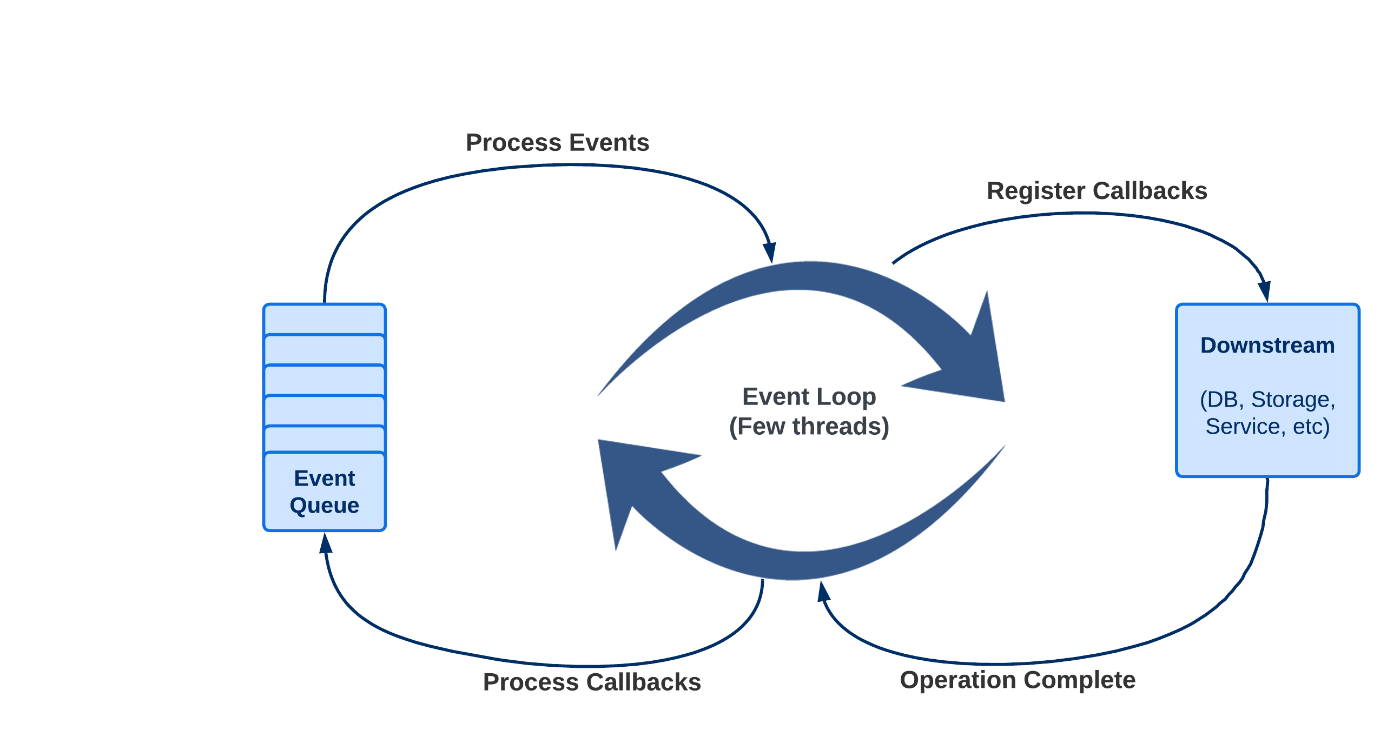
Spring 는 Java로 현대적이고 확장 가능한 웹 애플리케이션을 구축하기 위한 반응형 비차단 웹 프레임워크입니다. 이는 Spring Framework의 일부이며 Java에서 반응형 프로그래밍을 구현하기 위해 Reactor 라이브러리를 사용합니다. WebFlux WebFlux를 사용하면 수많은 동시 요청과 데이터 스트림을 처리할 수 있는 확장 가능한 고성능 웹 애플리케이션을 구축할 수 있습니다. 간단한 REST API부터 실시간 데이터 스트리밍 및 서버 전송 이벤트까지 광범위한 사용 사례를 지원합니다. Spring WebFlux는 반응형 스트림을 기반으로 한 프로그래밍 모델을 제공하므로 이를 통해 비동기 및 비차단 작업을 데이터 처리 단계의 파이프라인으로 구성할 수 있습니다. 또한 반응형 데이터 액세스, 반응형 보안 및 반응형 테스트 지원을 포함하여 반응형 웹 애플리케이션을 구축하기 위한 풍부한 기능과 도구 세트를 제공합니다. 에서 : 공식 Spring 문서 "반응형"이라는 용어는 I/O 이벤트에 반응하는 네트워크 구성 요소, 마우스 이벤트에 반응하는 UI 컨트롤러 등 변경에 대한 반응을 중심으로 구축된 프로그래밍 모델을 의미합니다. 그런 의미에서 비차단은 반응적입니다. 왜냐하면 차단되는 대신 이제 작업이 완료되거나 데이터를 사용할 수 있게 되면 알림에 반응하는 모드에 있기 때문입니다. 스레딩 모델 반응형 프로그래밍의 핵심 기능 중 하나는 스레딩 모델입니다. 이는 많은 동기식 웹 프레임워크에서 사용되는 전통적인 요청별 스레드 모델과 다릅니다. 기존 모델에서는 들어오는 각 요청을 처리하기 위해 새 스레드가 생성되고 해당 스레드는 요청이 처리될 때까지 차단됩니다. 요청을 처리하는 데 필요한 스레드 수가 매우 커지고 스레드 컨텍스트 전환이 병목 현상을 일으킬 수 있으므로 대량의 요청을 처리할 때 확장성 문제가 발생할 수 있습니다. 이와 대조적으로 WebFlux는 적은 수의 스레드가 많은 수의 요청을 처리할 수 있는 비차단 이벤트 중심 모델을 사용합니다. 요청이 들어오면 사용 가능한 스레드 중 하나에 의해 처리된 다음 실제 처리를 일련의 비동기 작업에 위임합니다. 이러한 작업은 비차단 방식으로 실행되므로 작업이 백그라운드에서 실행되는 동안 스레드가 다른 요청을 처리하기 위해 이동할 수 있습니다. Spring WebFlux(및 일반적으로 비차단 서버)에서는 애플리케이션이 차단되지 않는 것으로 가정합니다. 따라서 비차단 서버는 작은 고정 크기 스레드 풀(이벤트 루프 작업자)을 사용하여 요청을 처리합니다. 클래식 서블릿 컨테이너의 단순화된 스레딩 모델은 다음과 같습니다. WebFlux 요청 처리는 약간 다릅니다. 후드 빛나는 이론 뒤에 무엇이 있는지 살펴보겠습니다. 에 의해 생성된 아주 최소한의 앱이 필요합니다. 코드는 에서 사용할 수 있습니다. Spring Initializr GitHub 저장소 모든 스레드 관련 주제는 CPU에 크게 의존합니다. 일반적으로 요청을 처리하는 처리 스레드 수는 수와 관련이 있습니다 교육 목적으로 Docker 컨테이너를 실행할 때 CPU를 제한하여 풀의 스레드 수를 쉽게 조작할 수 있습니다. CPU 코어 . docker run --cpus=1 -d --rm --name webflux-threading -p 8081:8080 local/webflux-threading 풀에 여전히 둘 이상의 스레드가 표시된다면 괜찮습니다. WebFlux에 의해 설정된 있을 수 있습니다. 기본값이 우리 앱은 간단한 점쟁이입니다. 엔드포인트를 호출하면 사용하여 5개의 레코드를 얻을 수 있습니다. 각 조정은 당신에게 주어진 카르마를 나타내는 정수입니다. 예, 앱이 양수만 생성하기 때문에 우리는 매우 관대합니다. 더 이상 불운은 없습니다! /karma balanceAdjustment 기본 처리 아주 기본적인 예부터 시작해 보겠습니다. 다음 컨트롤러 메서드는 5개의 카르마 요소가 포함된 Flux를 반환합니다. @GetMapping("/karma") public Flux<Karma> karma() { return prepareKarma() .map(Karma::new) .log(); } private Flux<Integer> prepareKarma() { Random random = new Random(); return Flux.fromStream( Stream.generate(() -> random.nextInt(10)) .limit(5)); } 여기서는 방법이 매우 중요합니다. 모든 Reactive Streams 신호를 관찰하고 INFO 수준의 로그로 추적합니다. log 컬 의 로그 출력은 다음과 같습니다. localhost:8081/karma 보시다시피 IO 스레드 풀에서 처리가 진행되고 있습니다. 스레드 이름 를 나타냅니다. 작업을 제출한 스레드에서 작업이 즉시 실행되었습니다. Reactor는 다른 풀에서 예약하라는 지침을 보지 못했습니다. ctor-http-nio-2 reactor-http-nio-2 지연 및 병렬 처리 다음 작업은 각 요소 방출을 100ms 지연합니다(데이터베이스 에뮬레이션이라고도 함). @GetMapping("/delayedKarma") public Flux<Karma> delayedKarma() { return karma() .delayElements(Duration.ofMillis(100)); } 원래 호출에서 이미 선언되었으므로 여기에 메소드를 추가할 필요가 없습니다. karma() log 로그에서 다음 그림을 볼 수 있습니다. 이번에는 IO 스레드 에서 맨 첫 번째 요소만 수신되었습니다. 나머지 4개의 처리는 스레드 풀에 전용으로 사용되었습니다. reactor-http-nio-4 parallel 의 Javadoc은 다음을 확인합니다. delayElements 신호가 지연되고 병렬 기본 스케줄러에서 계속됩니다. 호출 체인의 어느 곳에나 지정하면 지연 없이 동일한 효과를 얻을 수 있습니다. .subscribeOn(Schedulers.parallel()) 스케줄러를 사용하면 여러 작업을 서로 다른 스레드에서 동시에 실행할 수 있어 성능과 확장성이 향상될 수 있으며, 이를 통해 CPU 리소스를 더 잘 활용하고 많은 수의 동시 요청을 처리할 수 있습니다. parallel 그러나 코드 복잡성과 메모리 사용량이 증가할 수 있으며, 최대 작업자 스레드 수를 초과하면 잠재적으로 스레드 풀이 고갈될 수 있습니다. 따라서 스레드 풀을 사용하기로 결정하려면 애플리케이션의 특정 요구 사항과 장단점을 기반으로 해야 합니다. parallel 서브체인 이제 좀 더 복잡한 예를 살펴보겠습니다. 코드는 여전히 매우 간단하고 간단하지만 출력은 훨씬 더 흥미롭습니다. 우리는 사용하여 점쟁이를 더욱 만들 것입니다. 각 Karma 인스턴스에 대해 원래 조정에 10을 곱하고 반대 조정을 생성하여 원래 조정을 보상하는 균형 잡힌 거래를 효과적으로 생성합니다. flatMap 공평하게 @GetMapping("/fairKarma") public Flux<Karma> fairKarma() { return delayedKarma() .flatMap(this::makeFair); } private Flux<Karma> makeFair(Karma original) { return Flux.just(new Karma(original.balanceAdjustment() * 10), new Karma(original.balanceAdjustment() * -10)) .subscribeOn(Schedulers.boundedElastic()) .log(); } 보시다시피, Flux는 스레드 풀을 구독해야 합니다. 처음 두 카르마에 대한 로그 내용을 확인해 보겠습니다. makeFair's boundedElastic Reactor는 IO 스레드에서 를 사용하여 첫 번째 요소를 구독합니다. balanceAdjustment=9 그런 다음 풀은 스레드에서 및 조정을 내보내 Karma 공정성에 대해 작동합니다. boundedElastic boundedElastic-1 90 -90 첫 번째 요소 이후의 요소는 병렬 스레드 풀에서 구독됩니다(체인에 여전히 있기 때문입니다). delayedElements 스케줄러 boundedElastic 란 무엇입니까 ? 작업 부하에 따라 작업자 스레드 수를 동적으로 조정하는 스레드 풀입니다. 데이터베이스 쿼리 및 네트워크 요청과 같은 I/O 바인딩 작업에 최적화되어 있으며, 너무 많은 스레드를 생성하거나 리소스를 낭비하지 않고 다수의 단기 작업을 처리하도록 설계되었습니다. 기본적으로 스레드 풀 최대 크기는 사용 가능한 프로세서 수에 10을 곱한 값이지만 필요한 경우 다른 최대 크기를 사용하도록 구성할 수 있습니다. boundedElastic 의 과 같은 비동기 스레드 풀을 사용하면 작업을 별도의 스레드로 오프로드하고 기본 스레드를 확보하여 다른 요청을 처리할 수 있습니다. 스레드 풀의 제한된 특성은 스레드 부족과 과도한 리소스 사용을 방지할 수 있는 반면, 풀의 탄력성은 작업 부하에 따라 작업자 스레드 수를 동적으로 조정할 수 있도록 해줍니다. boundedElastic 다른 유형의 스레드 풀 기본 클래스에서 제공하는 다음과 같은 두 가지 유형의 풀이 더 있습니다. Scheduler : 동기 실행을 위해 설계된 단일 스레드 직렬 실행 컨텍스트입니다. 작업이 순서대로 실행되고 두 작업이 동시에 실행되지 않도록 해야 할 때 유용합니다. single : 스레드 전환 없이 호출 스레드에서 작업을 즉시 실행하는 간단하고 작동하지 않는 스케줄러 구현입니다. immediate 결론 Spring WebFlux의 스레딩 모델은 비차단 및 비동기식으로 설계되어 최소한의 리소스 사용으로 많은 수의 요청을 효율적으로 처리할 수 있습니다. 연결당 전용 스레드에 의존하는 대신 WebFlux는 소수의 이벤트 루프 스레드를 사용하여 들어오는 요청을 처리하고 다양한 스레드 풀의 작업자 스레드에 작업을 배포합니다. 그러나 스레드 부족을 방지하고 시스템 리소스를 효율적으로 사용하려면 사용 사례에 적합한 스레드 풀을 선택하는 것이 중요합니다.