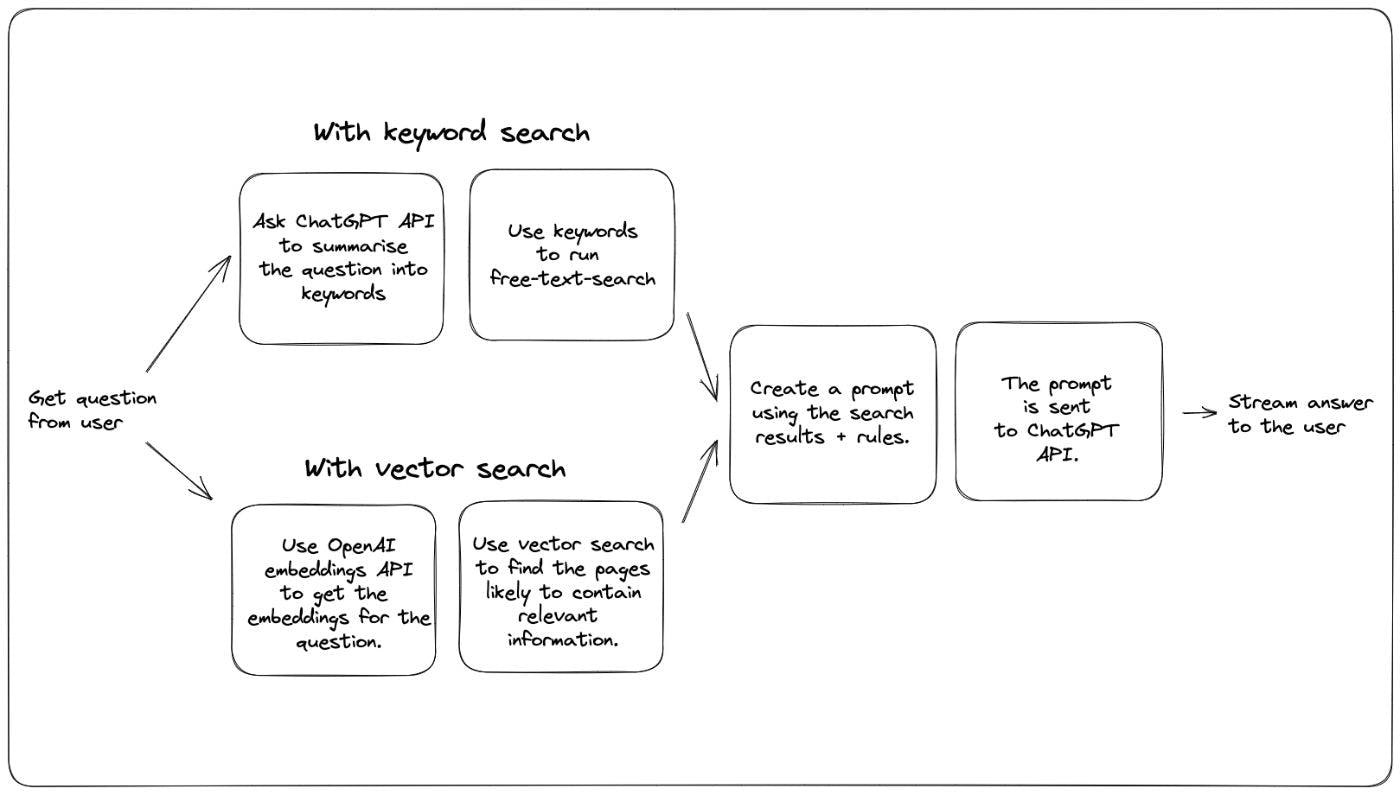
La semaine dernière, nous avons ajouté un bot de questions-réponses qui répond aux questions de . Cela tire parti de la technologie ChatGPT pour répondre aux questions de la documentation Xata, même si le modèle OpenAI GPT n'a jamais été formé sur les documents Xata. notre documentation Pour ce faire, nous utilisons une approche suggérée par Simon Willison dans cet . La même approche peut également être trouvée dans un . L'idée est la suivante : article de blog livre de recettes OpenAI Effectuez une recherche textuelle dans la documentation pour trouver le contenu le plus pertinent par rapport à la question posée par l'utilisateur. Produisez une invite avec cette forme générale : With these rules: {rules} And this text: {context} Given the above text, answer the question: {question} Answer: Envoyez l'invite à l'API ChatGPT et laissez le modèle compléter la réponse. Nous avons découvert que cela fonctionne assez bien et, combiné à une température de modèle relativement basse (le concept de température est expliqué dans cet ), cela a tendance à produire des résultats et des extraits de code corrects, tant que la réponse peut être trouvée dans le Documentation. article de blog Une limitation clé de cette approche est que l'invite que vous créez à la deuxième étape ci-dessus doit avoir un maximum de 4 000 jetons (~ 3 000 mots). Cela signifie que la première étape, la recherche de texte pour sélectionner les documents les plus pertinents, devient vraiment importante. Si l'étape de recherche fait du bon travail et fournit le bon contexte, ChatGPT a également tendance à faire du bon travail en produisant un résultat correct et précis. Quel est donc le meilleur moyen de trouver les éléments de contenu les plus pertinents dans la documentation ? Le livre de recettes OpenAI, ainsi que le blog de Simon, utilisent ce qu'on appelle la recherche sémantique. La recherche sémantique exploite le modèle de langage pour générer des intégrations à la fois pour la question et le contenu. Les plongements sont des tableaux de nombres qui représentent le texte sur un certain nombre de dimensions. Les morceaux de texte qui ont des imbrications similaires ont une signification similaire. Cela signifie qu'une bonne stratégie consiste à trouver les éléments de contenu qui présentent les intégrations les plus similaires aux intégrations de questions. Une autre stratégie possible, basée sur la recherche par mot-clé plus classique, ressemble à ceci : Demandez à ChatGPT d'extraire les mots clés de la question, avec une invite comme celle-ci : Extract keywords for a search query from the text provided. Add synonyms for words where a more common one exists. Utilisez les mots-clés fournis pour lancer une recherche en texte libre et sélectionner les meilleurs résultats En les mettant dans un seul diagramme, les deux méthodes ressemblent à ceci : Nous avons essayé les deux sur notre documentation et avons remarqué des avantages et des inconvénients. Commençons par comparer quelques résultats. Les deux sont exécutés sur la même base de données et utilisent tous les deux le modèle ChatGPT . Comme il y a du hasard, j'ai exécuté chaque question 2 à 3 fois et j'ai choisi ce qui me semblait être le meilleur résultat. gpt-3.5-turbo Question : Comment installer la CLI Xata ? Réponse avec recherche vectorielle : Réponse par recherche par mot-clé : : Les deux versions ont fourni la bonne réponse, cependant celle de la recherche vectorielle est un peu plus complète. Ils ont tous les deux trouvé la bonne page de documentation, mais je pense que notre heuristique basée sur les faits saillants a sélectionné un morceau de texte plus court en cas de stratégie de mots clés. Verdict Gagnant : recherche vectorielle. Score : 1-0 Question : Comment utilisez-vous Xata avec Deno ? Réponse avec recherche vectorielle : Réponse par recherche par mot-clé : résultat décevant pour la recherche de vecteurs, qui a en quelque sorte manqué la page dédiée à Deno dans nos documents. Il a trouvé d'autres contenus pertinents pour Deno, mais pas la page contenant l'exemple très utile. Verdict : Gagnant : recherche par mot-clé. Score : 1-1 Question : Comment puis-je importer un fichier CSV avec des types de colonnes personnalisés ? Avec recherche vectorielle : Avec recherche par mot-clé : Les deux ont trouvé la bonne page (« Importer un fichier CSV »), mais la version de recherche par mot-clé a réussi à obtenir une réponse plus complète. Je l'ai fait plusieurs fois pour m'assurer que ce n'est pas un coup de chance. Je pense que la différence vient de la façon dont le fragment de texte est sélectionné (voisin des mots-clés en cas de recherche par mots-clés, depuis le début de la page en cas de recherche vectorielle). Verdict : Gagnant : recherche par mot-clé. Pointage : 1-2 Question : Comment puis-je filtrer une table nommée Utilisateurs par la colonne d'e-mail ? Avec recherche vectorielle : Avec recherche par mot-clé : la recherche vectorielle a mieux fonctionné sur celui-ci, car elle a trouvé la page "Filtrage" sur laquelle il y avait plus d'exemples que ChatGPT pourrait utiliser pour composer la réponse. La réponse de la recherche par mot-clé est subtilement cassée, car elle utilise "query" au lieu de "filter" pour le nom de la méthode. Verdict : Gagnant : recherche vectorielle. Score : 2-2 Question : Qu'est-ce que Xata ? Avec recherche vectorielle : Avec recherche par mot-clé : Celui-ci est un match nul, car les deux réponses sont assez bonnes. Les deux ont choisi des pages différentes pour résumer dans une réponse, mais les deux ont fait du bon travail et je ne peux pas choisir de gagnant. Verdict : Score : 3-3 Configuration et réglage Voici un exemple de requête Xata utilisée pour la recherche par mot-clé : // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "What is Xata?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "If you answer with Markdown snippets, prefer the GitHub flavour.", "Your name is DanGPT" ], "searchType": "keyword", "search": { "fuzziness": 1, "target": [ "slug", { "column": "title", "weight": 4 }, "content", "section", { "column": "keywords", "weight": 4 } ], "boosters": [ { "valueBooster": { "column": "section", "value": "guide", "factor": 18 } } ] } } Et voici ce que nous utilisons pour la recherche vectorielle : // POST https://workspace-id.eu-west-1.xata.sh/db/docs:main/tables/search/ask { "question": "How do I get a record by id?", "rules": [ "Do not answer questions about pricing or the free tier. Respond that Xata has several options available, please check https://xata.io/pricing for more information.", "If the user asks a how-to question, provide a code snippet in the language they asked for with TypeScript as the default.", "Only answer questions that are relating to the defined context or are general technical questions. If asked about a question outside of the context, you can respond with \"It doesn't look like I have enough information to answer that. Check the documentation or contact support.\"", "Results should be relevant to the context provided and match what is expected for a cloud database.", "If the question doesn't appear to be answerable from the context provided, but seems to be a question about TypeScript, Javascript, or REST APIs, you may answer from outside of the provided context.", "Your name is DanGPT" ], "searchType": "vector", "vectorSearch": { "column": "embeddings", "contentColumn": "content", "filter": { "section": "guide" } } } Comme vous pouvez le voir, la version de recherche par mot-clé a plus de paramètres, configurant le flou, les boosters et les poids des colonnes. La recherche vectorielle utilise uniquement un filtre. J'appellerais cela un plus pour la recherche par mot-clé : vous avez plus de cadrans pour affiner la recherche et donc obtenir de meilleures réponses. Mais c'est aussi plus de travail, et les résultats de la recherche vectorielle sont assez bons sans ce réglage. Dans notre cas, nous avons déjà réglé la recherche par mot-clé pour notre fonctionnalité de recherche de documents. Ce n'était donc pas nécessairement un travail supplémentaire, et en jouant avec ChatGPT, nous avons également découvert des améliorations dans nos documents et notre recherche. De plus, il se trouve que Xata a une très belle interface utilisateur pour ajuster votre recherche par mot-clé, donc le travail n'a pas été difficile au début (planification d'un article de blog séparé à ce sujet). Il n'y a aucune raison pour laquelle la recherche de vecteurs ne pourrait pas également avoir des boosters et des poids de colonne, etc., mais nous ne l'avons pas encore dans Xata et je ne connais aucune autre solution qui rend cela aussi simple que nous rendons le mot-clé réglage de la recherche. Et, en général, il y a plus d'art antérieur à la recherche par mot-clé, mais il est tout à fait possible que la recherche vectorielle rattrape son retard. Pour l'instant, je vais appeler la recherche par mot-clé le gagnant Pointage : 3-4 Commodité Notre documentation avait déjà une fonction de recherche, dog-fooding Xata, donc c'était assez simple à étendre à un chat bot. Xata prend désormais également en charge la recherche vectorielle de manière native, mais son utilisation nécessitait d'ajouter des intégrations pour toutes les pages de documentation et de trouver une bonne stratégie de segmentation. Nous avons utilisé l'API OpenAI embeddings pour produire les incorporations de texte, qui avaient un coût minime. Gagnant : Recherche par mot-clé Score 3-5 Latence L'approche de recherche par mot-clé nécessite un aller-retour supplémentaire vers l'API ChatGPT. Cela ajoute en termes de latence au résultat commencé à être diffusé dans l'interface utilisateur. Selon mes mesures, cela ajoute environ 1,8 seconde de temps supplémentaire. Avec recherche vectorielle : Avec recherche par mot-clé : les temps de téléchargement total et de contenu ici ne sont pas pertinents, car ils dépendent principalement de la durée de la réponse générée. Regardez la barre "Attente de la réponse du serveur" (la verte) pour comparer. Remarque : Gagnant : Recherche vectorielle Pointage : 4-5 Coût La version de recherche par mot-clé doit effectuer un appel API supplémentaire à l'API ChatGPT, d'autre part, la version de recherche vectorielle doit produire des incorporations pour tous les documents de la base de données plus la question. À moins que nous ne parlions de beaucoup de documents, je vais appeler cela une égalité. Pointage : 5-6 Conclusion Le score est serré ! Dans notre cas, nous avons utilisé la recherche par mot-clé pour le moment, principalement parce que nous avons plus de façons de l'ajuster et, par conséquent, cela génère des réponses légèrement meilleures pour notre ensemble de questions de test. De plus, toutes les améliorations que nous apportons à la recherche profitent automatiquement à la fois aux cas d'utilisation de la recherche et du chat. Alors que nous améliorons nos capacités de recherche vectorielle avec plus d'options de réglage, nous pourrions passer à la recherche vectorielle ou à une approche hybride à l'avenir. Si vous souhaitez configurer un bot de discussion similaire pour votre propre documentation ou tout type de base de connaissances, vous pouvez facilement implémenter ce qui précède à l'aide du point de terminaison Xata ask. gratuitement et rejoignez-nous sur . Je serais heureux de vous aider personnellement à le mettre en place et à le faire fonctionner ! Créez un compte Discord