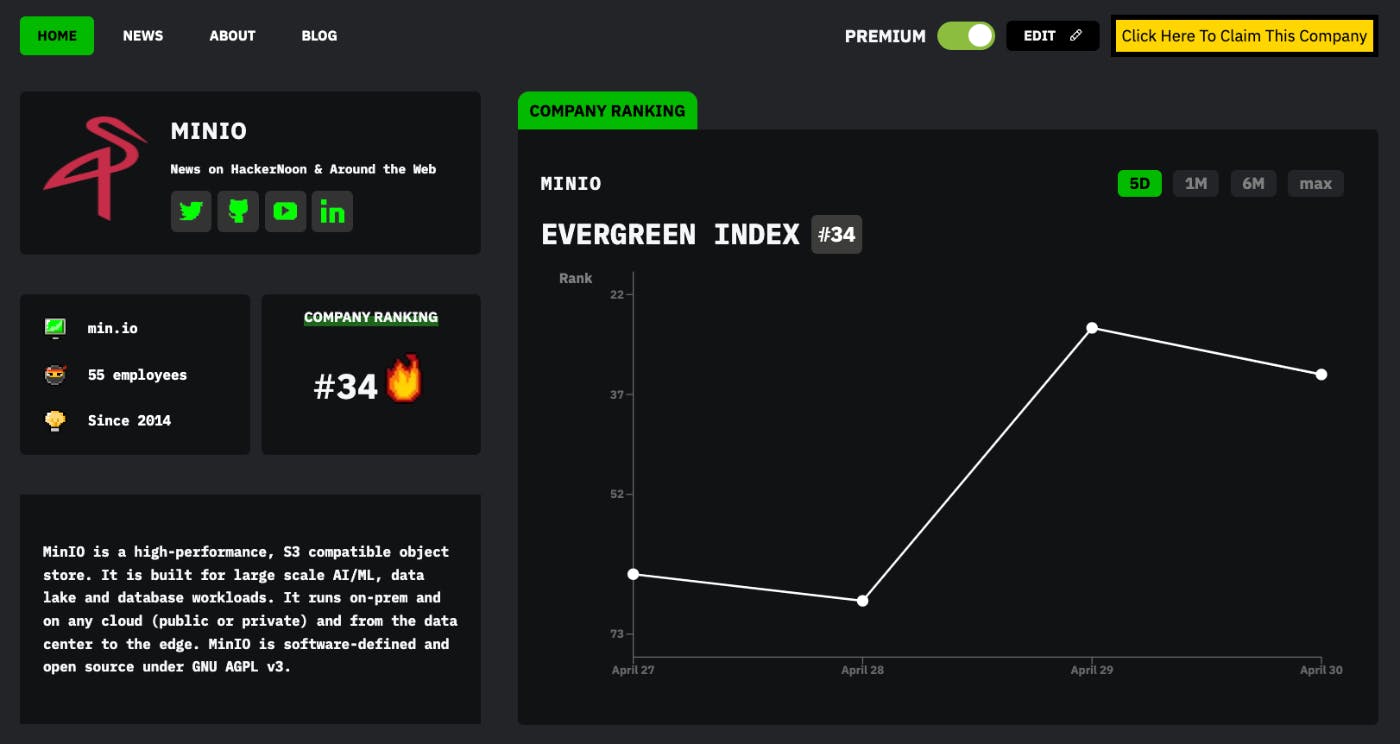
Forfattere: Almudena Carrera Vazquez Caroline Tornow Diego Ristè Stefan Woerner Maika Takita Daniel J. Egger Abstrakt Kvantekomputere behandler information med kvantemekanikkens love. Nuværende kvantehardware er støjende, kan kun lagre information i kort tid og er begrænset til et par kvantebits, det vil sige qubits, typisk arrangeret i en plan konnektivitet . Mange anvendelser af kvantecomputing kræver dog mere konnektivitet end det plane gitter, som hardwaren tilbyder på flere qubits, end der er tilgængeligt på en enkelt kvanteprocessor (QPU). Fællesskabet håber at tackle disse begrænsninger ved at forbinde QPUs ved hjælp af klassisk kommunikation, hvilket endnu ikke er bevist eksperimentelt. Her realiserer vi eksperimentelt fejlmindimerede dynamiske kredsløb og kredsløbsklipning for at skabe kvantetilstande, der kræver periodisk konnektivitet ved hjælp af op til 142 qubits, der spænder over to QPUs med 127 qubits hver, forbundet i realtid med et klassisk link. I et dynamisk kredsløb kan kvantegates klassisk styres af resultaterne af midterkredsløbsmålinger inden for kørselstid, det vil sige inden for en brøkdel af qubits' kohærenstid. Vores klassiske link i realtid giver os mulighed for at anvende en kvantegate på én QPU betinget af resultatet af en måling på en anden QPU. Desuden forbedrer den fejlmindimerede kontrolstrøm qubit-konnektiviteten og instruktionssættet for hardwaren, hvilket øger alsidigheden af vores kvantekomputere. Vores arbejde demonstrerer, at vi kan bruge flere kvanteprocessorer som én med fejlmindimerede dynamiske kredsløb muliggjort af et klassisk link i realtid. 1 Hoveddel Kvantekomputere behandler information kodet i kvantebits med unitære operationer. Kvantekomputere er dog støjende, og de fleste storskala-arkitekturer arrangerer de fysiske qubits i et plant gitter. Ikke desto mindre kan nuværende processorer med fejlmindimering allerede simulere hardware-native Ising-modeller med 127 qubits og måle observerbare i en skala, hvor brute-force-tilgange med klassiske computere begynder at kæmpe . Kvantekomputeres anvendelighed afhænger af yderligere skalering og overvindelse af deres begrænsede qubit-konnektivitet. En modulær tilgang er vigtig for skalering af nuværende støjende kvanteprocessorer og for at opnå de store antal fysiske qubits, der er nødvendige for fejltolerance . Fast-ion og neutrale atom-arkitekturer kan opnå modularitet ved fysisk at transportere qubits , . På kort sigt opnås modularitet i superledende qubits ved kortrækkende interconnects, der forbinder tilstødende chips , . 1 2 3 4 5 6 7 8 På mellemlang sigt kan langtrækkende gates, der opererer i mikrobølgeområdet, udføres over lange konventionelle kabler , , . Dette ville muliggøre ikke-plan konnektivitet af qubits, der er egnet til effektiv fejlkontrol . Et langsigtet alternativ er at sammenfiltre fjerne QPUs med et optisk link, der udnytter en mikrobølge-til-optisk transaktion , som efter vores viden endnu ikke er demonstreret. Desuden udvider dynamiske kredsløb operationssættet for en kvantecomputer ved at udføre midterkredsløbsmålinger (MCMs) og klassisk styre en gate inden for qubits' kohærenstid. De forbedrer algoritmiske kvaliteter og qubit-konnektivitet . Som vi vil vise, muliggør dynamiske kredsløb også modularitet ved at forbinde QPUs i realtid via et klassisk link. 9 10 11 3 12 13 14 Vi tager en komplementær tilgang baseret på virtuelle gates til at implementere langtrækkende interaktioner i en modulær arkitektur. Vi forbinder qubits på vilkårlige placeringer og skaber sammenfiltringsstatistikkerne gennem en quasi-sandsynlighedsdekomponering (QPD) , , . Vi sammenligner et rent lokalt operations (LO) skema med et, der er udvidet med klassisk kommunikation (LOCC) . LO-skemaet, demonstreret i en to-qubit-indstilling , kræver udførelse af flere kvantekredsløb med kun lokale operationer. Derimod bruger vi til at implementere LOCC virtuelle Bell-par i et teleportationskredsløb til at skabe to-qubit-gates , . På kvantehardware med sparsom og plan konnektivitet kræver oprettelse af et Bell-par mellem vilkårlige qubits en langtrækkende controlled-NOT (CNOT) gate. For at undgå disse gates bruger vi en QPD over lokale operationer, hvilket resulterer i klippede Bell-par, som teleportationen forbruger. LO kræver ikke det klassiske link og er således enklere at implementere end LOCC. Da LOCC kun kræver et enkelt parametriseret skabelonkredsløb, er det dog mere effektivt at kompilere end LO, og omkostningen ved dets QPD er lavere end omkostningen ved LO-skemaet. 15 16 17 16 17 18 19 20 Vores arbejde giver fire centrale bidrag. For det første præsenterer vi kvantekredsløbene og QPD'en til at skabe flere klippede Bell-par for at realisere de virtuelle gates i ref. . For det andet undertrykker og afbøder vi de fejl, der opstår fra latenstiden for den klassiske kontrolhardware i dynamiske kredsløb med en kombination af dynamisk afkobling og zero-noise ekstrapolation . For det tredje udnytter vi disse metoder til at konstruere periodiske grænsebetingelser på en 103-knudes graf-tilstand. For det fjerde demonstrerer vi en realtids klassisk forbindelse mellem to separate QPUs, hvilket demonstrerer, at et system af distribuerede QPUs kan opereres som én via et klassisk link . Kombineret med dynamiske kredsløb giver dette os mulighed for at operere begge chips som én kvantecomputer, hvilket vi eksemplificerer ved at konstruere en periodisk graf-tilstand, der spænder over begge enheder på 142 qubits. Vi diskuterer en vej frem for at skabe langtrækkende gates og giver vores konklusion. 17 21 22 23 Kredsløbsklipning Vi kører store kvantekredsløb, der muligvis ikke kan udføres direkte på vores hardware på grund af begrænsninger i qubit-antal eller konnektivitet ved at klippe gates. Kredsløbsklipning dekomponerer et komplekst kredsløb i underkredsløb, der kan udføres individuelt , , , , , . Vi skal dog køre et øget antal kredsløb, som vi kalder sampling-overhead. Resultaterne fra disse underkredsløb kombineres derefter klassisk for at give resultatet af det oprindelige kredsløb ( ). 15 16 17 24 25 26 Metoder Da et af hovedbidragene i vores arbejde er implementering af virtuelle gates med LOCC, viser vi, hvordan man skaber de nødvendige klippede Bell-par med lokale operationer. Her konstrueres flere klippede Bell-par ved hjælp af parametriserede kvantekredsløb, som vi kalder en klippet Bell-parfabrik (Fig. ). Klargøring af flere par samtidigt kræver lavere sampling-overhead . Da den klippede Bell-parfabrik danner to disjunkte kvantekredsløb, placerer vi hvert underkredsløb tæt på qubits, der har langtrækkende gates. Den resulterende ressource forbruges derefter i et teleportationskredsløb. For eksempel, i Fig. , forbruges de klippede Bell-par til at skabe CNOT-gates på qubit-parrene (0, 1) og (2, 3) (se afsnittet ‘ ’). 1b,c 17 1b Klippede Bell-parfabrikker , Afbildning af en IBM Quantum System Two-arkitektur. Her er to 127-qubit Eagle QPUs forbundet med et klassisk link i realtid. Hver QPU styres af sin elektronik i sit rack. Vi synkroniserer begge racks tæt for at operere begge QPUs som én. , Skabelon kvantekredsløb til at implementere virtuelle CNOT-gates på qubit-parrene ( 0, 1) og ( 2, 3) med LOCC ved at forbruge klippede Bell-par i et teleportationskredsløb. De lilla dobbeltlinjer svarer til det klassiske link i realtid. , Klippede Bell-parfabrikker 2( ) for to samtidigt klippede Bell-par. QPD'en har et samlet antal på 27 forskellige parametrisæt . Her er. a b q q q q c C θ i θ i Periodiske grænsebetingelser Vi konstruerer en graf-tilstand | ⟩ med periodiske grænsebetingelser på ibm_kyiv, en Eagle-processor , der går ud over grænserne, der er pålagt af dens fysiske konnektivitet (se afsnittet ‘ ’). Her har nbsp;∣ ∣ = 103 knuder og kræver fire langtrækkende kanter lr = {(1, 95), (2, 98), (6, 102), (7, 97)} mellem de øverste og nederste qubits i Eagle-processoren (Fig. ). Vi måler knude-stabilisatorerne ved hver knude ∈ og kant-stabilisatorerne dannet af produktet over hver kant ( , ) ∈ . Fra disse stabilisatorer opbygger vi et sammenfiltrings-vidne , som er negativt, hvis der er bipartit sammenfiltring på tværs af kanten ( , ) ∈ (ref. ) (se afsnittet ‘ ’). Vi fokuserer på bipartit sammenfiltring, fordi dette er den ressource, vi ønsker at genskabe med virtuelle gates. Måling af vidner om sammenfiltring mellem mere end to parter vil kun måle kvaliteten af de ikke-virtuelle gates og målinger, hvilket gør indvirkningen af de virtuelle gates mindre klar. G 1 Graf-tilstande G V E 2a Si i V SiSj i j E i j E 27 Sammenfiltrings-vidne , Den tunge-sekskantede graf foldes på sig selv til en rørformet form ved kanterne (1, 95), (2, 98), (6, 102) og (7, 97) fremhævet i blåt. Vi klipper disse kanter. , Knude-stabilisatorerne (top) og vidner , (bund), med 1 standardafvigelse for knuderne og kanterne tæt på langtrækkende kanter. Lodrette stiplede linjer grupperer stabilisatorer og vidner efter deres afstand til klippede kanter. , Kumulativ fordelingsfunktion af stabilisatorfejl. Stjernerne angiver knude-stabilisatorer , der har en kant implementeret af en langtrækkende gate. I benchmark for den faldne kant (stiplet rød linje) implementeres langtrækkende gates ikke, og de stjerne-angivne stabilisatorer har derfor enhedsfejl. Det grå område er sandsynlighedsmassen svarende til knude-stabilisatorer påvirket af klipningerne. – , I de todimensionelle layouts duplikerer de grønne knuder knuderne 95, 98, 102 og 97 for at vise de klippede kanter. De blå knuder i er qubit-ressourcer til at skabe klippede Bell-par. Farven på knude er den absolutte fejl ∣ − 1∣ af den målte stabilisator, som angivet af farvebjælken. En kant er sort, hvis sammenfiltringsstatistikker detekteres med 99% konfidensniveau, og violet, hvis ikke. I implementeres de langtrækkende gates med SWAP-gates. I implementeres de samme gates med LOCC. I implementeres de slet ikke. a b Sj c Sj d f e i Si d e f Vi forbereder | ⟩ ved hjælp af tre forskellige metoder. Hardware-native kanter implementeres altid med CNOT-gates, men de periodiske grænsebetingelser implementeres med (1) SWAP-gates, (2) LOCC og (3) LO til at forbinde qubits på tværs af hele gitteret. Den primære forskel mellem LOCC og LO er en feed-forward operation bestående af en-qubit gates betinget af 2 målingsresultater, hvor er antallet af klip. Hver af de 22 tilfælde udløser en unik kombination af og/eller gates på de relevante qubits. Indhentning af målingsresultaterne, bestemmelse af den tilsvarende sag og handling baseret på den udføres i realtid af kontrolhardwaren, til omkostningen af en fast tilføjet latenstid. Vi afbøder og undertrykker fejlene som følge af denne latenstid med zero-noise ekstrapolation og forskudt dynamisk afkobling , (se afsnittet ‘ ’). G n n n X Z 22 21 28 Fejlmindimerede kvantekredsløbs-switch-instruktioner Vi benchmarker SWAP-, LOCC- og LO-implementeringerne af | ⟩ med en hardware-native graf-tilstand på ′ = ( , ′) opnået ved at fjerne langtrækkende gates, det vil sige ′ = lr. Kredsløbet, der forbereder | ′⟩, kræver således kun 112 CNOT-gates arrangeret i tre lag efter den tunge-sekskantede topologi af Eagle-processoren. Dette kredsløb vil rapportere store fejl, når knude- og kant-stabilisatorerne af | ⟩ måles for knuder på en klippet gate, da det er designet til at implementere | ′⟩. Vi refererer til dette hardware-native benchmark som benchmark for den faldne kant. Det swap-baserede kredsløb kræver yderligere 262 CNOT-gates til at skabe langtrækkende kanter lr, hvilket drastisk reducerer værdien af de målte stabilisatorer (Fig. ). I modsætning hertil kræver LOCC- og LO-implementeringen af kanterne i lr ikke SWAP-gates. Fejlene på deres knude- og kant-stabilisatorer for knuder, der ikke er involveret i en klippet gate, følger tæt benchmark for den faldne kant (Fig. ). Omvendt har stabilisatorerne, der involverer en virtuel gate, en lavere fejl end benchmark for den faldne kant og swap-implementeringen (Fig. , stjernemarkører). Som en samlet kvalitetsmetrik rapporterer vi først summen af absolutte fejl på knude-stabilisatorerne, det vil sige ∑ ∈ ∣ − 1∣ (Udvidet datatabel ). Den store SWAP-overhead er ansvarlig for den absolutte fejlsum på 44,3. Fejlen på 13,1 på benchmark for den faldne kant domineres af de otte knuder på de fire klip (Fig. , stjernemarkører). I modsætning hertil påvirkes LO- og LOCC-fejl af MCMs. Vi tilskriver den 1,9 yderligere fejl af LOCC over LO til forsinkelserne og CNOT-gates i teleportationskredsløbet og klippede Bell-par. I de swap-baserede resultater, detekterer ikke sammenfiltring på tværs af 35 af de 116 kanter med 99% konfidensniveau (Fig. ). For LO- og LOCC-implementeringen vidner om statistikkerne for bipartit sammenfiltring på tværs af alle kanter i med 99% konfidensniveau (Fig. ). Disse metrikker viser, at virtuelle langtrækkende gates producerer stabilisatorer med mindre fejl end deres dekomponering i SWAPs. Desuden holder de variansen lav nok til at verificere sammenfiltringsstatistikkerne. G G V E E EE G G G E 2b–d E 2b,c 2c i V Si 1 2c 2b,d G 2e Betjening af to QPU'er som én Vi kombinerer nu to Eagle QPUs med 127 qubits hver til en enkelt QPU via en klassisk forbindelse i realtid. Betjening af enhederne som en enkelt, større processor består i at udføre kvantekredsløb, der spænder over det større qubit-register. Bortset fra unitære gates og målinger, der kører samtidigt på den sammensmeltede QPU, bruger vi dynamiske kredsløb til at udføre gates, der virker på qubits på begge enheder. Dette muliggøres af tæt synkronisering og hurtig klassisk kommunikation mellem fysisk adskilte instrumenter, der er nødvendige for at indsamle målingsresultater og bestemme kontrolstrømmen på tværs af hele systemet . 29 Vi tester denne klassiske forbindelse i realtid ved at konstruere en graf-tilstand på 134 qubits bygget af tunge-sekskantede ringe, der snor sig gennem begge QPUs (Fig. ). Disse ringe blev valgt ved at udelukke qubits, der var plaget af to-niveausystemer og aflæsningsproblemer, for at sikre en graf-tilstand af høj kvalitet. Denne graf danner en ring i tre dimensioner og kræver fire langtrækkende gates, som vi implementerer med LO og LOCC. Som før kræver LOCC-protokollen yderligere to qubits per klippet gate for de klippede Bell-par. Som i det foregående afsnit benchmarkede vi vores resultater til en graf, der ikke implementerer de kanter, der spænder over begge QPUs. Da der ikke er noget kvanteforbindelse mellem de to enheder, er et benchmark med SWAP-gates umuligt. Alle kanter udviser statistikkerne for bipartit sammenfiltring, når vi implementerer grafen med LO og LOCC med 99% konfidensniveau. Desuden har LO- og LOCC-stabilisatorerne samme kvalitet som benchmark for den faldne kant for knuder, der ikke er påvirket af en langtrækkende gate (Fig. ). Stabilisatorer, der er påvirket af langtrækkende gates, har en stor reduktion i fejl sammenlignet med benchmark for den faldne kant. Summen af absolutte fejl på knude-stabilisatorerne ∑ ∈ ∣ − 1∣, er 21,0, 19,2 og 12,6 for henholdsvis benchmark for den faldne kant, LOCC og LO. Som før tilskriver vi de 6,6 yderligere fejl af LOCC over LO til forsinkelserne og CNOT-gates i teleportationskredsløbet og klippede Bell-par. LOCC-resultaterne demonstrerer, hvordan et dynamisk kvantekredsløb, hvor to underkredsløb er forbundet af et klassisk link i realtid, kan udføres på to ellers disjunkte QPUs. LO-resultaterne kunne opnås på en enkelt enhed med 127 qubits til omkostningen af en yderligere faktor 2 i kørselstid, da underkredsløbene kan køres successivt. 3 3c i V Si , Graf-tilstand med periodiske grænser vist i tre dimensioner. De blå kanter er de klippede kanter. , Koblingskort over to Eagle QPUs opereret som en enkelt enhed med 254 qubits. De lilla knuder er de qubits, der danner graf-tilstanden i , og de blå knuder bruges til klippede Bell-par. , , Absolut fejl på stabilisatorerne ( ) og kant-vidner ( ) implementeret med LOCC (solid grøn) og LO (solid orange) og på et benchmark graf for den faldne kant (prikket-streget rød) for graf-tilstanden i . I og viser stjernerne stabil a b a c d c d a c d