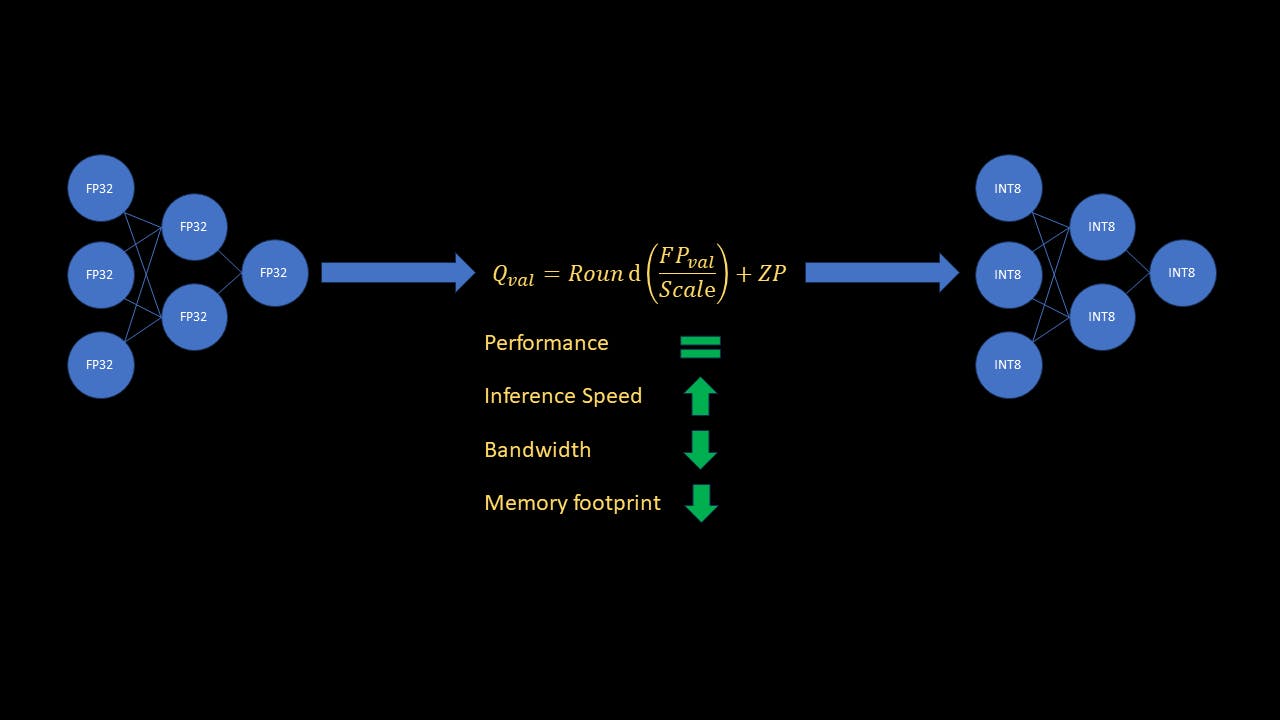
আপনি কি জানেন যে মেশিন লার্নিং এর জগতে, ডিপ লার্নিং (DL) মডেলগুলির কার্যকারিতা কোয়ান্টাইজেশন নামক একটি কৌশল দ্বারা উল্লেখযোগ্যভাবে বৃদ্ধি করা যেতে পারে? আপনার নিউরাল নেটওয়ার্কের কর্মক্ষমতা ত্যাগ না করে কম্পিউটেশনাল ভার কমানোর কল্পনা করুন। একটি বড় ফাইলের সারমর্ম না হারিয়ে যেমন কম্প্রেস করার মতো, মডেল কোয়ান্টাইজেশন আপনাকে আপনার মডেলগুলিকে আরও ছোট এবং দ্রুত করতে দেয়৷ আসুন কোয়ান্টাইজেশনের চটুল ধারণার মধ্যে ডুব দেওয়া যাক এবং বাস্তব-বিশ্ব স্থাপনার জন্য আপনার নিউরাল নেটওয়ার্কগুলিকে অপ্টিমাইজ করার রহস্য উন্মোচন করি। আমরা খনন করার আগে, পাঠকদের নিউরাল নেটওয়ার্ক এবং পরিমাপকরণের মৌলিক ধারণার সাথে পরিচিত হওয়া উচিত, যার মধ্যে স্কেল (S) এবং জিরো পয়েন্ট (ZP) অন্তর্ভুক্ত রয়েছে। পাঠকদের জন্য যারা একটি রিফ্রেশার চান, এবং বিস্তৃত ধারণা এবং পরিমাণ নির্ধারণের প্রকারগুলি ব্যাখ্যা করে৷ এই নিবন্ধটি এই নিবন্ধটি এই নির্দেশিকায় আমি সংক্ষেপে ব্যাখ্যা করব কেন কোয়ান্টাইজেশন গুরুত্বপূর্ণ, এবং কিভাবে Pytorch ব্যবহার করে এটি বাস্তবায়ন করা যায়। আমি মূলত "পোস্ট ট্রেনিং স্ট্যাটিক কোয়ান্টাইজেশন" নামক কোয়ান্টাইজেশনের ধরণে ফোকাস করব, যার ফলে এমএল মডেলের মেমরির 4x কম মেমরি ফুটপ্রিন্ট হয় এবং অনুমানকে 4x পর্যন্ত দ্রুততর করে। ধারণা কেন কোয়ান্টাইজেশন গুরুত্বপূর্ণ? নিউরাল নেটওয়ার্ক গণনাগুলি সাধারণত 32 বিট ফ্লোটিং পয়েন্ট সংখ্যার সাথে সঞ্চালিত হয়। একটি একক 32 বিট ফ্লোটিং পয়েন্ট নম্বর (FP32) এর জন্য 4 বাইট মেমরি প্রয়োজন। তুলনায়, একটি একক 8 বিট পূর্ণসংখ্যা সংখ্যা (INT8) এর জন্য শুধুমাত্র 1 বাইট মেমরি প্রয়োজন। আরও, কম্পিউটারগুলি ফ্লোট অপারেশনের তুলনায় পূর্ণসংখ্যার গাণিতিক অনেক দ্রুত প্রক্রিয়া করে। এখনই, আপনি দেখতে পাচ্ছেন যে FP32 থেকে INT8 পর্যন্ত একটি ML মডেলের পরিমাণ 4x কম মেমরি হবে। আরও, এটি অনুমানকে 4x পর্যন্ত গতি বাড়িয়ে দেবে! বৃহৎ মডেলগুলি এই মুহূর্তে সমস্ত রাগ হওয়ার সাথে সাথে, অনুশীলনকারীদের জন্য বাস্তব সময়ের অনুমানের জন্য মেমরি এবং গতির জন্য প্রশিক্ষিত মডেলগুলি অপ্টিমাইজ করতে সক্ষম হওয়া গুরুত্বপূর্ণ৷ মূল শর্তাবলী প্রশিক্ষিত নিউরাল নেটওয়ার্কের ওজন। ওজন- কোয়ান্টাইজেশনের পরিপ্রেক্ষিতে, অ্যাক্টিভেশনগুলি সিগময়েড বা রিএলইউ-এর মতো অ্যাক্টিভেশন ফাংশন নয়। অ্যাক্টিভেশন দ্বারা, আমি মধ্যবর্তী স্তরগুলির বৈশিষ্ট্য মানচিত্র আউটপুট বলতে চাচ্ছি, যা পরবর্তী স্তরগুলিতে ইনপুট। অ্যাক্টিভেশন- পোস্ট ট্রেনিং স্ট্যাটিক কোয়ান্টাইজেশন পোস্ট ট্রেনিং স্ট্যাটিক কোয়ান্টাইজেশন মানে মূল মডেলের প্রশিক্ষণের পর কোয়ান্টাইজেশনের জন্য আমাদেরকে প্রশিক্ষিত বা সূক্ষ্মভাবে মডেল করার দরকার নেই। এছাড়াও আমাদের মধ্যবর্তী স্তরের ইনপুটগুলির পরিমাপ করার প্রয়োজন নেই, যাকে ফ্লাইতে সক্রিয়করণ বলা হয়। পরিমাপকরণের এই পদ্ধতিতে, প্রতিটি স্তরের জন্য স্কেল এবং শূন্য বিন্দু গণনা করে ওজনগুলি সরাসরি পরিমাপ করা হয়। যদিও অ্যাক্টিভেশনের জন্য, মডেলের ইনপুট পরিবর্তন হওয়ার সাথে সাথে অ্যাক্টিভেশনগুলিও পরিবর্তিত হবে। অনুমান করার সময় মডেলটি যে প্রতিটি ইনপুটের সম্মুখীন হবে তার পরিধি আমরা জানি না। তাহলে কিভাবে আমরা নেটওয়ার্কের সমস্ত সক্রিয়তার জন্য স্কেল এবং শূন্য বিন্দু গণনা করতে পারি? আমরা একটি ভাল প্রতিনিধি ডেটাসেট ব্যবহার করে মডেলটি ক্যালিব্রেট করে এটি করতে পারি। তারপরে আমরা ক্রমাঙ্কন সেটের জন্য অ্যাক্টিভেশনের মানের পরিসীমা পর্যবেক্ষণ করি এবং তারপর স্কেল এবং শূন্য বিন্দু গণনা করতে সেই পরিসংখ্যানগুলি ব্যবহার করি। এটি মডেলটিতে পর্যবেক্ষকদের সন্নিবেশ করে করা হয়, যা ক্রমাঙ্কনের সময় ডেটা পরিসংখ্যান সংগ্রহ করে। মডেল প্রস্তুত করার পরে (পর্যবেক্ষক সন্নিবেশ করান), আমরা ক্রমাঙ্কন ডেটাসেটে মডেলটির ফরোয়ার্ড পাস চালাই। পর্যবেক্ষকরা সক্রিয়করণের জন্য স্কেল এবং শূন্য পয়েন্ট গণনা করতে এই ক্রমাঙ্কন ডেটা ব্যবহার করে। এখন অনুমান কেবলমাত্র সমস্ত স্তরে তাদের নিজ নিজ স্কেল এবং শূন্য বিন্দু সহ রৈখিক রূপান্তর প্রয়োগ করার বিষয়। যদিও সম্পূর্ণ অনুমানটি INT8 তে করা হয়, চূড়ান্ত মডেল আউটপুট ডিকোয়ান্টাইজ করা হয় (INT8 থেকে FP32 পর্যন্ত)। যদি ইনপুট এবং নেটওয়ার্ক ওজনগুলি ইতিমধ্যেই পরিমাপ করা হয় তবে কেন সক্রিয়করণগুলি পরিমাপ করা দরকার? এটি একটি চমৎকার প্রশ্ন। যদিও নেটওয়ার্ক ইনপুট এবং ওজনগুলি প্রকৃতপক্ষে ইতিমধ্যেই INT8 মান, ওভারফ্লো এড়াতে স্তরটির আউটপুট INT32 হিসাবে সংরক্ষণ করা হয়। পরবর্তী স্তর প্রক্রিয়াকরণে জটিলতা কমাতে সক্রিয়করণগুলি INT32 থেকে INT8 পর্যন্ত পরিমাপ করা হয়। ধারণাগুলি পরিষ্কার করে, আসুন কোডের মধ্যে ডুব দিয়ে দেখি এবং এটি কীভাবে কাজ করে! এই উদাহরণের জন্য, আমি Pytorch-এ সরাসরি উপলব্ধ Flowers102 ডেটাসেটে ফাইন-টিউন করা resnet18 মডেল ব্যবহার করব। যাইহোক, কোডটি উপযুক্ত ক্রমাঙ্কন ডেটাসেট সহ যেকোন প্রশিক্ষিত CNN-এর জন্য কাজ করবে। যেহেতু এই টিউটোরিয়ালটি কোয়ান্টাইজেশনের উপর দৃষ্টি নিবদ্ধ করা হয়েছে, তাই আমি প্রশিক্ষণ এবং ফাইন-টিউনিং অংশটি কভার করব না। যাইহোক, সব কোড পাওয়া যাবে. ঝাঁপ দাও! এখানে কোয়ান্টাইজেশন কোড কোয়ান্টাইজেশনের জন্য এবং ফাইন-টিউনড মডেল লোড করার জন্য প্রয়োজনীয় লাইব্রেরিগুলি আমদানি করা যাক। import torch import torchvision import torchvision.transforms as transforms from torchvision.models import resnet18 import torch.nn as nn from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping import warnings warnings.filterwarnings('ignore') এর পরে, আসুন কিছু প্যারামিটার সংজ্ঞায়িত করি, ডেটা ট্রান্সফর্ম এবং ডেটা লোডার সংজ্ঞায়িত করি এবং সূক্ষ্ম-টিউনড মডেলটি লোড করি model_path = 'flowers_model.pth' quantized_model_save_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) # Define train data loader, for using as calibration set trainset = torchvision.datasets.Flowers102(root='./data', split="train", download=True, transform=transform) trainLoader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2) # Load the finetuned resnet model model_to_quantize = resnet18(weights=None) num_features = model_to_quantize.fc.in_features model_to_quantize.fc = nn.Linear(num_features, num_classes) model_to_quantize.load_state_dict(torch.load(model_path)) model_to_quantize.eval() print('Loaded fine-tuned model') এই উদাহরণের জন্য, আমি ক্রমাঙ্কন সেট হিসাবে কিছু প্রশিক্ষণ নমুনা ব্যবহার করব। এখন, মডেলের পরিমাণ নির্ধারণের জন্য ব্যবহৃত কনফিগারেশনটি সংজ্ঞায়িত করা যাক। # Define quantization parameters config for the correct platform, # "x86" for x86 devices or "qnnpack" for arm devices qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) উপরের স্নিপেটে, আমি ডিফল্ট কনফিগারেশন ব্যবহার করেছি, কিন্তু Pytorch-এর শ্রেণীটি বর্ণনা করতে ব্যবহৃত হয় কিভাবে মডেল বা মডেলের একটি অংশ পরিমাপ করা উচিত। আমরা ওজন এবং সক্রিয়করণের জন্য ব্যবহার করা পর্যবেক্ষক শ্রেণীর ধরন নির্দিষ্ট করে এটি করতে পারি। QConfig আমরা এখন কোয়ান্টাইজেশনের জন্য মডেল প্রস্তুত করতে প্রস্তুত # Fuse conv-> relu, conv -> bn -> relu layer blocks and insert observers model_prep = prepare_fx(model=model_to_quantize, qconfig_mapping=qconfig_mapping, example_inputs=torch.randn((1,3,224,224))) ফাংশন মডেলের মধ্যে পর্যবেক্ষকদের সন্নিবেশ করায়, এবং conv→relu এবং conv→bn→relu মডিউলগুলিকে ফিউজ করে। এই মডিউলগুলির মধ্যবর্তী ফলাফলগুলি সঞ্চয় করার প্রয়োজন না হওয়ার কারণে এর ফলে কম অপারেশন এবং কম মেমরি ব্যান্ডউইথ হয়। prepare_fx ক্রমাঙ্কন ডেটাতে ফরওয়ার্ড পাস চালিয়ে মডেলটি ক্যালিব্রেট করুন # Run calibration for 10 batches (100 random samples in total) print('Running calibration') with torch.no_grad(): for i, data in enumerate(trainLoader): samples, labels = data _ = model_prep(samples) if i == 10: break আমাদের পুরো প্রশিক্ষণ সেটে ক্রমাঙ্কন চালানোর দরকার নেই! এই উদাহরণে, আমি 100টি এলোমেলো নমুনা ব্যবহার করছি, কিন্তু বাস্তবে, আপনার একটি ডেটাসেট নির্বাচন করা উচিত যা মডেলটি স্থাপনের সময় কী দেখতে পাবে তার প্রতিনিধি। মডেল কোয়ান্টাইজ করুন এবং কোয়ান্টাইজড ওজন সংরক্ষণ করুন! # Quantize calibrated model quantized_model = convert_fx(model_prep) print('Quantized model!') # Save quantized torch.save(quantized_model.state_dict(), quantized_model_save_path) print('Saved quantized model weights to disk') এবং এটাই! এখন আসুন দেখি কিভাবে একটি কোয়ান্টাইজড মডেল লোড করা যায় এবং তারপরে আসল এবং কোয়ান্টাইজড মডেলের নির্ভুলতা, গতি এবং মেমরি পদচিহ্নের তুলনা করি। একটি কোয়ান্টাইজড মডেল লোড করুন একটি কোয়ান্টাইজড মডেল গ্রাফ মূল মডেলের মতো একেবারে একই নয়, এমনকি উভয়ের একই স্তর থাকলেও। উভয় মডেলের প্রথম স্তর ( ) মুদ্রণ পার্থক্য দেখায়। conv1 print('\nPrinting conv1 layer of fp32 and quantized model') print(f'fp32 model: {model_to_quantize.conv1}') print(f'quantized model: {quantized_model.conv1}') আপনি লক্ষ্য করবেন যে বিভিন্ন শ্রেণীর সাথে, কোয়ান্টাইজড মডেলের কনভ1 স্তরটিতে স্কেল এবং জিরো পয়েন্ট প্যারামিটারও রয়েছে। সুতরাং, আমাদের যা করতে হবে তা মডেল গ্রাফ তৈরি করার জন্য কোয়ান্টাইজেশন প্রক্রিয়া (ক্রমাঙ্কন ছাড়া) অনুসরণ করুন এবং তারপর পরিমাপকৃত ওজন লোড করুন। অবশ্যই, যদি আমরা quantized মডেলটিকে onnx ফরম্যাটে সংরক্ষণ করি, আমরা প্রতিবার কোয়ান্টাইজেশন ফাংশনগুলি না চালিয়ে অন্য যেকোনো onnx মডেলের মতো এটি লোড করতে পারি। এরই মধ্যে, আসুন কোয়ান্টাইজড মডেল লোড করার জন্য একটি ফাংশন সংজ্ঞায়িত করি এবং এটি এ সংরক্ষণ করি। inference_utils.py import torch from torch.ao.quantization import get_default_qconfig from torch.ao.quantization.quantize_fx import prepare_fx, convert_fx from torch.ao.quantization import QConfigMapping def load_quantized_model(model_to_quantize, weights_path): ''' Model only needs to be calibrated for the first time. Next time onwards, to load the quantized model, you still need to prepare and convert the model without calibrating it. After that, load the state dict as usual. ''' model_to_quantize.eval() qconfig = get_default_qconfig("x86") qconfig_mapping = QConfigMapping().set_global(qconfig) model_prep = prepare_fx(model_to_quantize, qconfig_mapping, torch.randn((1,3,224,224))) quantized_model = convert_fx(model_prep) quantized_model.load_state_dict(torch.load(weights_path)) return quantized_model নির্ভুলতা এবং গতি পরিমাপের জন্য ফাংশন সংজ্ঞায়িত করুন নির্ভুলতা পরিমাপ import torch def test_accuracy(model, testLoader): model.eval() running_acc = 0 num_samples = 0 with torch.no_grad(): for i, data in enumerate(testLoader): samples, labels = data outputs = model(samples) preds = torch.argmax(outputs, 1) running_acc += torch.sum(preds == labels) num_samples += samples.size(0) return running_acc / num_samples এটি একটি সুন্দর সহজবোধ্য Pytorch কোড। অনুমানের গতি মিলিসেকেন্ডে পরিমাপ করুন (মিসে) import torch from time import time def test_speed(model): dummy_sample = torch.randn((1,3,224,224)) # Average out inference speed over multiple iterations # to get a true estimate num_iterations = 100 start = time() for _ in range(num_iterations): _ = model(dummy_sample) end = time() return (end-start)/num_iterations * 1000 এ এই দুটি ফাংশন যোগ করুন। আমরা এখন মডেল তুলনা করতে প্রস্তুত. আমাদের কোড মাধ্যমে যেতে দিন. inference_utils.py নির্ভুলতা, গতি এবং আকারের জন্য মডেলের তুলনা করুন আসুন প্রথমে প্রয়োজনীয় লাইব্রেরি আমদানি করি, প্যারামিটার সংজ্ঞায়িত করি, ডেটা ট্রান্সফর্ম এবং টেস্ট ডেটালোডার। import os import torch import torch.nn as nn import torchvision from torchvision.models import resnet18 import torchvision.transforms as transforms from inference_utils import test_accuracy, test_speed, load_quantized_model import copy import warnings warnings.filterwarnings('ignore') model_weights_path = 'flowers_model.pth' quantized_model_weights_path = 'quantized_flowers_model.pth' batch_size = 10 num_classes = 102 # Define data transforms transform = transforms.Compose( [transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( (0.485, 0.465, 0.406), (0.229, 0.224, 0.225))] ) testset = torchvision.datasets.Flowers102(root='./data', split="test", download=True, transform=transform) testLoader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2) দুটি মডেল লোড করুন # Load the finetuned resnet model and the quantized model model = resnet18(weights=None) num_features = model.fc.in_features model.fc = nn.Linear(num_features, num_classes) model.load_state_dict(torch.load(model_weights_path)) model.eval() model_to_quantize = copy.deepcopy(model) quantized_model = load_quantized_model(model_to_quantize, quantized_model_weights_path) মডেল তুলনা করুন # Compare accuracy fp32_accuracy = test_accuracy(model, testLoader) accuracy = test_accuracy(quantized_model, testLoader) print(f'Original model accuracy: {fp32_accuracy:.3f}') print(f'Quantized model accuracy: {accuracy:.3f}\n') # Compare speed fp32_speed = test_speed(model) quantized_speed = test_speed(quantized_model) print(f'Inference time for original model: {fp32_speed:.3f} ms') print(f'Inference time for quantized model: {quantized_speed:.3f} ms\n') # Compare file size fp32_size = os.path.getsize(model_weights_path)/10**6 quantized_size = os.path.getsize(quantized_model_weights_path)/10**6 print(f'Original model file size: {fp32_size:.3f} MB') print(f'Quantized model file size: {quantized_size:.3f} MB') ফলাফল আপনি দেখতে পাচ্ছেন, পরীক্ষার ডেটাতে কোয়ান্টাইজড মডেলের নির্ভুলতা প্রায় মূল মডেলের নির্ভুলতার মতো! কোয়ান্টাইজড মডেলের সাথে অনুমান ~3.6x দ্রুত (!) এবং কোয়ান্টাইজড মডেলের জন্য মূল মডেলের চেয়ে ~4x কম মেমরি প্রয়োজন! উপসংহার এই নিবন্ধে, আমরা এমএল মডেল কোয়ান্টাইজেশনের বিস্তৃত ধারণা এবং পোস্ট ট্রেনিং স্ট্যাটিক কোয়ান্টাইজেশন নামে এক ধরনের কোয়ান্টাইজেশন বুঝতে পেরেছি। বড় মডেলের সময়ে কোয়ান্টাইজেশন কেন গুরুত্বপূর্ণ এবং একটি শক্তিশালী হাতিয়ার তাও আমরা দেখেছি। অবশেষে, আমরা পাইটর্চ ব্যবহার করে একটি প্রশিক্ষিত মডেলের পরিমাপ করার জন্য উদাহরণ কোডের মাধ্যমে গিয়েছিলাম এবং ফলাফলগুলি পর্যালোচনা করেছি। ফলাফল যেমন দেখায়, মূল মডেলের পরিমাপ করা কর্মক্ষমতাকে প্রভাবিত করেনি, এবং একই সময়ে অনুমানের গতি ~3.6x কমেছে এবং মেমরি পদচিহ্ন ~4x কমিয়েছে! উল্লেখ্য কয়েকটি পয়েন্ট- স্ট্যাটিক কোয়ান্টাইজেশন সিএনএন-এর জন্য ভাল কাজ করে, কিন্তু সিকোয়েন্স মডেলের জন্য ডায়নামিক কোয়ান্টাইজেশন পছন্দের পদ্ধতি। অতিরিক্তভাবে, যদি কোয়ান্টাইজেশন মডেলের কার্যকারিতাকে মারাত্মকভাবে প্রভাবিত করে, তবে কোয়ান্টাইজেশন অ্যাওয়ার ট্রেনিং (QAT) নামক একটি কৌশল দ্বারা সঠিকতা পুনরুদ্ধার করা যেতে পারে। কিভাবে ডাইনামিক কোয়ান্টাইজেশন এবং QAT কাজ করে? সেগুলি অন্য সময়ের জন্য পোস্ট। আমি আশা করি এই নির্দেশিকাটির সাহায্যে, আপনাকে আপনার নিজস্ব Pytorch মডেলগুলিতে স্ট্যাটিক কোয়ান্টাইজেশন করার জন্য জ্ঞান প্রদান করা হয়েছে। তথ্যসূত্র মডেল কোয়ান্টাইজেশনের বুনিয়াদি টেনসর কোয়ান্টাইজেশন ফুল 102 ডেটাসেট পাইটর্চ ডক্স