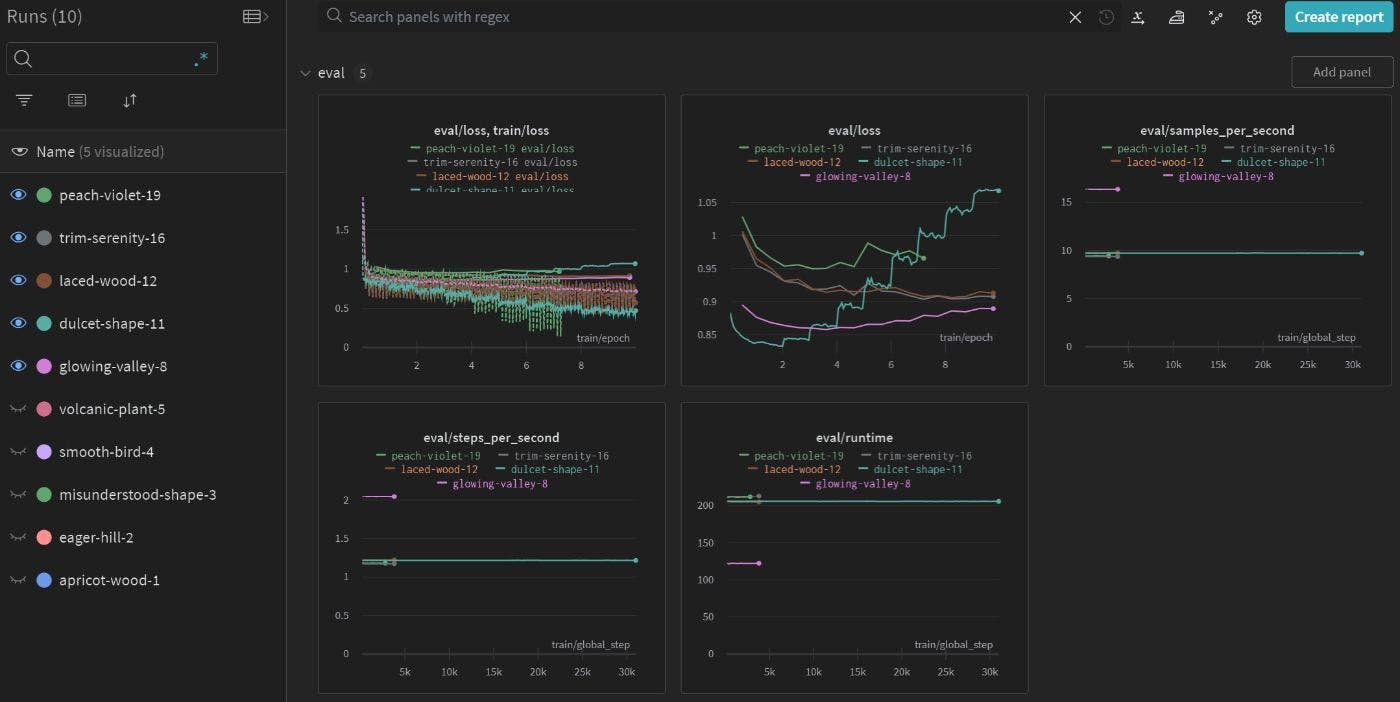
চ্যাটজিপিটি প্রকাশের পর থেকে সফ্টওয়্যার বিকাশে (এলএলএম) হয়ে উঠেছে। মানুষের সাথে প্রাকৃতিক কথোপকথন করার ক্ষমতা হল আইসবার্গের টিপ মাত্র। ল্যাংচেইন বা শব্দার্থিক কার্নেলের মতো সরঞ্জামগুলির সাথে উন্নত, ব্যবহারকারীরা কীভাবে সফ্টওয়্যারের সাথে যোগাযোগ করে তা সম্পূর্ণরূপে পরিবর্তন করার ক্ষমতা এলএলএমগুলির রয়েছে৷ অন্য কথায়, এলএলএমগুলি কার্যকারিতা এবং ডেটা উত্সগুলির মধ্যে সমন্বয় তৈরি করতে পারে এবং আরও দক্ষ এবং স্বজ্ঞাত ব্যবহারকারীর অভিজ্ঞতা প্রদান করতে পারে। বড় ভাষা মডেলগুলি উদাহরণস্বরূপ, অনেক লোক ইতিমধ্যেই তাদের পরবর্তী ভাইরাল ভিডিওগুলির জন্য AI-ভিত্তিক সামগ্রী তৈরির সরঞ্জামগুলি ব্যবহার করছে৷ একটি সাধারণ ভিডিও উত্পাদন পাইপলাইনে স্ক্রিপ্টিং, লজিস্টিকস, স্টোরিবোর্ডিং, সম্পাদনা এবং বিপণন অন্তর্ভুক্ত রয়েছে, শুধুমাত্র কয়েকটি নাম। প্রক্রিয়াটিকে স্ট্রিমলাইন করার জন্য, একটি LLM স্ক্রিপ্ট লেখার সময়, শ্যুট করার জন্য প্রপস ক্রয় করার সময়, স্ক্রিপ্টের উপর ভিত্তি করে স্টোরিবোর্ড তৈরি করতে (ছবি তৈরির জন্য স্থিতিশীল বিস্তারের প্রয়োজন হতে পারে), সম্পাদনা প্রক্রিয়া সহজতর করতে এবং নজরকাড়া শিরোনাম লেখার সময় গবেষণার মাধ্যমে বিষয়বস্তু নির্মাতাদের সাহায্য করতে পারে। /সোশ্যাল মিডিয়াতে ভিউ আকৃষ্ট করার জন্য ভিডিও বিবরণ। এলএলএমগুলি হল মূল যা এই সমস্তগুলি অর্কেস্ট্রেট করে, তবে একটি সফ্টওয়্যার পণ্যে এলএলএম অন্তর্ভুক্ত করার সময় বেশ কিছু উদ্বেগ থাকতে পারে: আমি যদি OpenAI এর API ব্যবহার করি, তাহলে আমি কি এই পরিষেবার উপর খুব বেশি নির্ভরশীল হব? কি হবে যদি তারা দাম বাড়ায়? যদি তারা পরিষেবার প্রাপ্যতা পরিবর্তন করে? আমি পছন্দ করি না যে কিভাবে OpenAI বিষয়বস্তু সেন্সর করে বা নির্দিষ্ট ব্যবহারকারীর ইনপুটগুলিতে অ-গঠনমূলক প্রতিক্রিয়া প্রদান করে। (বা অন্যভাবে: আমি পছন্দ করি না যে ওপেনএআই সেন্সরশিপ আমার ব্যবহারের ক্ষেত্রে সংবেদনশীল কিছু বিষয় উপেক্ষা করে।) আমার ক্লায়েন্টরা যদি প্রাইভেট ক্লাউড বা অন-প্রিমিসেস ডিপ্লোয়মেন্ট পছন্দ করে, তাহলে আমার কাছে কি বিকল্প আছে? ChatGPT আমি শুধু নিয়ন্ত্রণ করতে চাই. আমার এলএলএম কাস্টমাইজ করতে হবে এবং আমি এটি সস্তা চাই। এই উদ্বেগের জন্য, আমি ভাবছি যে ওপেনএআই-এর জিপিটি মডেলগুলির একটি ওপেন-সোর্স সমতুল্য হতে পারে কিনা। সৌভাগ্যবশত, বিস্ময়কর ওপেন সোর্স সম্প্রদায়গুলি ইতিমধ্যে কিছু খুব প্রতিশ্রুতিশীল সমাধান ভাগ করছে। আমি চেষ্টা করার সিদ্ধান্ত নিয়েছি, আপনার নিজের এলএলএম প্রশিক্ষণের জন্য একটি প্যারামিটার-দক্ষ ফাইন-টিউনিং পদ্ধতি। এই ব্লগ পোস্টটি প্রক্রিয়া, আমি যে সমস্যার সম্মুখীন হয়েছি, কীভাবে আমি সেগুলি সমাধান করেছি এবং পরবর্তীতে কী ঘটতে পারে সেগুলি নিয়ে আলোচনা করে৷ আপনি যদি আপনার নিজের এলএলএম প্রশিক্ষণের জন্য কৌশলটি ব্যবহার করতে চান তবে আমি আশা করি তথ্যটি সাহায্য করতে পারে। আলপাকা-লোরা চল শুরু করি! বিষয়বস্তু ওভারভিউ LLaMA, alpaca এবং LoRA কি? ফাইন-টিউনিং পরীক্ষা সোর্স কোড দ্রুত স্ক্যান করা হচ্ছে প্রথম প্রচেষ্টা প্রথম পর্যবেক্ষণ দ্বিতীয় প্রচেষ্টা এবং (কিছুটা) সাফল্য 7B পেরিয়ে যাওয়া সারসংক্ষেপ LLaMA, alpaca এবং LoRA কি? হল Meta AI থেকে ফাউন্ডেশন ল্যাঙ্গুয়েজ মডেলের একটি সংগ্রহ। এই অটোরিগ্রেসিভ মডেলগুলির 7B থেকে 65B পর্যন্ত পরামিতি গণনা রয়েছে এবং সেগুলি শুধুমাত্র গবেষণার উদ্দেশ্যে ব্যবহার করা যেতে পারে। মেটা সম্প্রতি প্রকাশ করেছে, যা কিছু সীমাবদ্ধতার সাথে বাণিজ্যিকভাবে ব্যবহার করা যেতে পারে। LLaMA মডেল পরিবারকে বিশেষ করে তোলে এর প্রশিক্ষণ সংস্থা এবং কর্মক্ষমতা। মেটা বলে যে LLaMA সর্বজনীনভাবে উপলব্ধ ডেটাসেটগুলিতে প্রশিক্ষিত। এর 13B ভেরিয়েন্ট বেশিরভাগ বেঞ্চমার্কে GPT-3 (একটি 175B মডেল) এর সাথে তুলনীয় কর্মক্ষমতা অর্জন করে। LLaMA LLaMA 2 হল LLaMA-এর উপর ভিত্তি করে একটি নির্দেশ-অনুসরণকারী LLM তৈরি করার জন্য স্ট্যানফোর্ডের প্রচেষ্টা। এটি এই মত কাজ করে: আলপাকা একটি ভাষা মডেলকে নির্দেশ-ইনপুট-প্রতিক্রিয়া ট্রিপলেট তৈরি করতে বলুন। সূক্ষ্ম-টিউনিং LLaMA এর জন্য উত্পন্ন ডেটা ব্যবহার করুন। ফাইন-টিউনিংয়ের পরে, LLaMA ব্যবহারকারীর নির্দেশাবলী অনুসরণ করতে এবং সেই অনুযায়ী প্রতিক্রিয়া জানাতে সক্ষম হয়। এখানে ভ্যানিলা LLaMA এর প্রতিক্রিয়া এবং সূক্ষ্ম সুর করা LLaMA প্রতিক্রিয়ার মধ্যে একটি তুলনা রয়েছে: { "instruction": "Answer user's question.", "input": "Can you put a medium voltage circuit breaker in a low voltage switchgear? Why? Explain in detail.", "vanilla LLaMA": { "answer": "Yes, you can put a medium voltage circuit breaker in a low voltage switchgear. The medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put....(repetition continues)" }, "fine-tuned LLaMA": { "answer": "No, it is not possible to put a medium voltage circuit breaker in a low voltage switchgear. This is because low voltage switchgear is designed to handle voltages up to 1 kV, while medium voltage switchgear is designed to handle voltages from 1 kV to 38 kV. The circuit breakers, contacts, and other components in low voltage switchgear are not suitable for the higher voltages and currents of medium voltage switchgear. Using a medium voltage circuit breaker in a low voltage switchgear could result in damage to the components and could pose a safety hazard." } } আপনি দেখতে পাচ্ছেন, ফাইন-টিউনিং এলএলএম আচরণকে বেশ ব্যাপকভাবে পরিবর্তন করে। ভ্যানিলা মডেলটি একটি পুনরাবৃত্তি লুপে আটকে আছে। যদিও সূক্ষ্ম সুর করা মডেলটি 100% সঠিক প্রতিক্রিয়া দেয়নি, অন্তত এর উত্তরটি একটি ধ্বনিত "না"। ব্যবহারযোগ্য এলএলএম তৈরির জন্য ফাইন-টিউনিং একটি প্রয়োজনীয় পদক্ষেপ। অনেক ক্ষেত্রে, একটি ওপেন সোর্সড ফাইন-টিউনড এলএলএম স্থাপন করাই যথেষ্ট। যাইহোক, কিছু মানানসই ব্যবসায়িক ব্যবহারের ক্ষেত্রে, ডোমেন-নির্দিষ্ট ডেটাসেটে মডেলগুলিকে সূক্ষ্ম-টিউন করা পছন্দনীয় হতে পারে। আলপাকার সবচেয়ে বড় অসুবিধা হল এর সম্পদের প্রয়োজন। এর GitHub পৃষ্ঠাটি বলে যে: সহজভাবে, একটি 7B মডেলকে ফাইন-টিউন করার জন্য প্রায় 7 x 4 x 4 = 112 GB VRAM প্রয়োজন। এটি একটি A100 80GB GPU পরিচালনা করতে পারে তার চেয়ে বেশি VRAM। আমরা ব্যবহার করে VRAM প্রয়োজনীয়তা বাইপাস করতে পারি। LoRA LoRA এই মত কাজ করে: একটি মডেলে কিছু ওজন নির্বাচন করুন, যেমন একটি ট্রান্সফরমার মডেলে ক্যোয়ারী প্রজেকশন ওজন $W_q$। নির্বাচিত ওজনে অ্যাডাপ্টারের ওজন যোগ করুন (হ্যাঁ, গাণিতিক সংযোজন)। মূল মডেল হিমায়িত করুন, শুধুমাত্র যোগ করা ওজন প্রশিক্ষণ. যোগ করা ওজনের কিছু বিশেষ বৈশিষ্ট্য রয়েছে। এই দ্বারা অনুপ্রাণিত, এডওয়ার্ড হু এবং অন্যান্য. দেখিয়েছেন যে একটি আসল মডেলের ওজন $W_o\in R^{d \times k}$, আপনি ডাউনস্ট্রিম কাজের জন্য একটি সূক্ষ্ম-টিউনড ওজন $W_o'=W_o+BA$ তৈরি করতে পারেন, যেখানে $B\in R^{d \times r}$ , $A \in R^{r \times k}$ এবং $r\ll min(d, k)$ হল অ্যাডাপ্টারের ওজনের "অভ্যন্তরীণ র্যাঙ্ক"। অ্যাডাপ্টারের ওজনের জন্য একটি সঠিক $r$ সেট করা গুরুত্বপূর্ণ, যেহেতু একটি ছোট $r$ মডেলের কর্মক্ষমতা কমিয়ে দেয়, এবং একটি বড় $r$ আনুপাতিক কর্মক্ষমতা বৃদ্ধি ছাড়াই অ্যাডাপ্টারের ওজনের আকার বাড়ায়। কাগজ এই কৌশলটি ছেঁটে যাওয়া SVD-এর অনুরূপ, যা একটি ম্যাট্রিক্সকে আনুমানিক কয়েকটি ছোট ম্যাট্রিসে পচিয়ে এবং শুধুমাত্র কয়েকটি বড় একবচন মান রেখে দেয়। R^{100 \times 100}$ এ $W_o\ ধরে নিলে, একটি সম্পূর্ণ ফাইন-টিউনিং 10,000 প্যারামিটার পরিবর্তন করবে। $r=8$ সহ LoRA ফাইন-টিউনিং সূক্ষ্ম-টিউন করা ওজনকে 2টি অংশে বিভক্ত করবে, $B\in R^{100 \times 8}$ এবং $A\in R^{8 \times 100}$, প্রতিটি অংশটিতে 800টি পরামিতি রয়েছে (মোট 1600টি পরামিতি।) প্রশিক্ষণযোগ্য প্যারামিটারের সংখ্যা 6.25 গুণ কমে গেছে। LoRA এর সাথে মডেলটিকে রূপান্তরিত করার পরে, আমরা একটি মডেল পেয়েছি যার মাত্র ~1% প্রশিক্ষণযোগ্য ওজন রয়েছে, তবুও কিছু নির্দিষ্ট ডোমেনে এর কার্যকারিতা ব্যাপকভাবে উন্নত হয়েছে। এটি আমাদের আরও অ্যাক্সেসযোগ্য হার্ডওয়্যার যেমন RTX 4090 বা V100-এ 7B বা 13B মডেলকে প্রশিক্ষণ দেওয়ার অনুমতি দেবে। ফাইন-টিউনিং পরীক্ষা আমি Huawei ক্লাউডে একটি GPU-অ্যাক্সিলারেটেড VM উদাহরণ সহ পরীক্ষা চালিয়েছি ( , 8vCPU, 64GB RAM, 1x V100 32GB VRAM।) এটা জানা যায় যে V100 bfloat16 ডেটা টাইপ সমর্থন করে না এবং এর টেনসর কোর int8 সমর্থন করে না ত্বরণ এই 2টি সীমা মিশ্র নির্ভুলতা প্রশিক্ষণকে ধীর করে দিতে পারে এবং মিশ্র নির্ভুলতা প্রশিক্ষণের সময় সংখ্যাগত ওভারফ্লো ঘটাতে পারে। আমরা পরবর্তী আলোচনার জন্য এটি মনে রাখব। p2s.2xlarge সোর্স কোড দ্রুত স্ক্যান করা হচ্ছে এবং প্রকল্পের মূল। প্রথম স্ক্রিপ্টটি LLaMA মডেলগুলিকে সূক্ষ্ম-টিউন করে এবং দ্বিতীয় স্ক্রিপ্টটি ব্যবহারকারীদের সাথে চ্যাট করার জন্য সূক্ষ্ম-টিউনড মডেল ব্যবহার করে৷ প্রথমে এর মূল প্রবাহটি দেখে নেওয়া যাক: finetune.py generate.py finetune.py একটি প্রাক-প্রশিক্ষিত বড় ফাউন্ডেশন মডেল লোড হচ্ছে model = LlamaForCausalLM.from_pretrained( base_model, # name of a huggingface compatible LLaMA model load_in_8bit=True, torch_dtype=torch.float16, device_map=device_map, ) মডেলের টোকেনাইজার লোড করুন tokenizer = LlamaTokenizer.from_pretrained(base_model) tokenizer.pad_token_id = ( 0 # unk. we want this to be different from the eos token ) tokenizer.padding_side = "left" # Allow batched inference প্রশিক্ষণ টেমপ্লেটের উপর ভিত্তি করে, দুটি ফাংশন সহ মডেল ইনপুট প্রস্তুত করুন, এবং । tokenize generate_and_tokenize_prompt huggingface এর ব্যবহার করে একটি LoRA অভিযোজিত মডেল তৈরি করুন PEFT config = LoraConfig( r=lora_r, # the lora rank lora_alpha=lora_alpha, # a weight scaling factor, think of it like learning rate target_modules=lora_target_modules, # transformer modules to apply LoRA to lora_dropout=lora_dropout, bias="none", task_type="CAUSAL_LM", ) model = get_peft_model(model, config) একটি প্রশিক্ষকের উদাহরণ তৈরি করুন এবং প্রশিক্ষণ শুরু করুন trainer = transformers.Trainer( model=model, train_dataset=train_data, eval_dataset=val_data, args=transformers.TrainingArguments( ... এই বেশ সহজ. শেষে, স্ক্রিপ্ট চেকপয়েন্ট, অ্যাডাপ্টারের ওজন এবং অ্যাডাপ্টার কনফিগারেশন সহ একটি মডেল ফোল্ডার তৈরি করে। এর মূল প্রবাহটি দেখি এর পরে, আসুন generate.py : লোড মডেল এবং অ্যাডাপ্টারের ওজন model = LlamaForCausalLM.from_pretrained( base_model, device_map={"": device}, torch_dtype=torch.float16, ) model = PeftModel.from_pretrained( model, lora_weights, device_map={"": device}, torch_dtype=torch.float16, ) প্রজন্মের কনফিগারেশন নির্দিষ্ট করুন generation_config = GenerationConfig( temperature=temperature, top_p=top_p, top_k=top_k, num_beams=num_beams, **kwargs, ) generate_params = { "input_ids": input_ids, "generation_config": generation_config, "return_dict_in_generate": True, "output_scores": True, "max_new_tokens": max_new_tokens, } স্ট্রিমিং এবং নন-স্ট্রিমিং জেনারেশন মোডের জন্য ফাংশন সংজ্ঞায়িত করুন: if stream_output: # streaming ... # Without streaming with torch.no_grad(): generation_output = model.generate( input_ids=input_ids, generation_config=generation_config, return_dict_in_generate=True, output_scores=True, max_new_tokens=max_new_tokens, ) s = generation_output.sequences[0] output = tokenizer.decode(s) yield prompter.get_response(output) মডেল পরীক্ষা করতে একটি Gradio সার্ভার শুরু করুন: gr.Interface( ... প্রথম প্রচেষ্টা প্রজেক্টের বলেছে যে নিম্নলিখিত ফাইন-টিউন সেটিংস স্ট্যানফোর্ড আলপাকার সাথে তুলনীয় কর্মক্ষমতা সহ একটি LLaMA 7B তৈরি করে। আলিঙ্গনমুখে একটি ভাগ করা হয়েছিল৷ README.md "অফিসিয়াল" আলপাকা-লোরা ওজন python finetune.py \ --base_model='decapoda-research/llama-7b-hf' \ --num_epochs=10 \ --cutoff_len=512 \ --group_by_length \ --output_dir='./lora-alpaca' \ --lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \ --lora_r=16 \ --micro_batch_size=8 যাইহোক, আমার অভিজ্ঞতায়, এটি একটি ব্যবহারযোগ্য মডেল তৈরি করেনি। এটি একটি V100 তে চালানো হলে নিম্নলিখিত শো-স্টপিং সমস্যার সম্মুখীন হবে: দিয়ে মডেল লোড করার ফলে ডেটা টাইপ ত্রুটি দেখা দেয়। load_in_8bit একটি বাইন্ডিং স্ক্রিপ্ট PEFT একটি অবৈধ অ্যাডাপ্টার তৈরি করবে৷ অবৈধ অ্যাডাপ্টারটি আসল LLaMA মডেলে কোন পরিবর্তন করে না এবং শুধুমাত্র বিভ্রান্তি তৈরি করে। মডেল দৃশ্যত ভুল টোকেনাইজার ব্যবহার করেছে। এর প্যাড টোকেন, বোস টোকেন এবং ইওএস টোকেন LLaMA এর অফিসিয়াল টোকেনাইজার থেকে আলাদা। decapoda-research/llama-7b-hf পূর্বে উল্লিখিত হিসাবে, V100 int8/fp16 মিশ্র প্রশিক্ষণের জন্য যথাযথ সমর্থনের অভাব রয়েছে। এটি অপ্রত্যাশিত আচরণের কারণ হয়, যেমন এবং । training loss = 0.0 eval loss = NaN চারপাশে খনন করে এবং অসংখ্য VM ঘন্টা নষ্ট করার পরে, আমি একটি একক V100-এ প্রশিক্ষণের কাজ করার জন্য প্রয়োজনীয় পরিবর্তনগুলি খুঁজে পেয়েছি। ... # do not use decapoda-research/llama-7b-hf as base_model. use a huggingface LLaMA model that was properly converted and has a correct tokenizer, eg, yahma/llama-7b-hf or huggyllama/llama-7b. # decapoda-research/llama-7b-hf is likely to cause overflow/underflow on V100. train loss goes to 0 and eval loss becomes NaN. using yahma/llama-7b-hf or huggyllama/llama-7b somehow mitigates this issue model = LlamaForCausalLM.from_pretrained( base_model, load_in_8bit=True, # only work for 7B LLaMA. On a V100, set True to save some VRAM at the cost of slower training; set False to speed up training at the cost of more VRAM / smaller micro batch size torch_dtype=torch.float16, device_map=device_map, ) ... # comment out the following line if load_in_8bit=False model = prepare_model_for_int8_training(model) ... # set legacy=False to avoid unexpected tokenizer behavior. make sure no tokenizer warning was raised during tokenizer instantiation tokenizer = LlamaTokenizer.from_pretrained(base_model, legacy=False) ... # the following binding script results in invalid adapter. simply comment them out old_state_dict = model.state_dict model.state_dict = ( lambda self, *_, **__: get_peft_model_state_dict( self, old_state_dict() ) ).__get__(model, type(model)) ... # if load_in_8bit=True, need to cast data type during training with torch.autocast('cuda'): trainer.train(resume_from_checkpoint=resume_from_checkpoint) এই পরিবর্তনগুলি করার পরে, এই প্রশিক্ষণ আর্গুমেন্টগুলি একটি ব্যবহারযোগ্য মডেল তৈরি করে। { "args": [ "--base_model", "yahma/llama-7b-hf", "--num_epochs=10", "--data_path", "yahma/alpaca-cleaned", "--output_dir", "./your output dir", "--cutoff_len=512", "--lora_target_modules=[q_proj,k_proj,v_proj,o_proj]", "--lora_r=16", "--micro_batch_size=2", "--batch_size=16", "--wandb_project", "your wandb project name" ], } মনে রাখবেন যে প্রশিক্ষণ স্ক্রিপ্ট শুধুমাত্র "সেরা" মডেল (সর্বনিম্ন ইভাল ক্ষতি সহ চেকপয়েন্ট) সংরক্ষণ করে না, তবে কয়েকটি চেকপয়েন্টও সংরক্ষণ করে। আমি আরও বিশ্লেষণের জন্য প্রশিক্ষণ/ইভাল লস লগ করতে wandb ব্যবহার করেছি। প্রথম পর্যবেক্ষণ আমি সূক্ষ্ম সুর করা মডেলে কিছু এলোমেলো প্রশ্ন নিক্ষেপ করি। এটি কিছু যুক্তিসঙ্গত প্রতিক্রিয়া তৈরি করে। এখানে একটি উদাহরণ: নির্দেশনা: ব্যবহারকারীর প্রশ্নের উত্তর দিন সাবধানে। ইনপুট: আপনি যখন একটি সুইচগিয়ার সার্কিট ব্রেকার ট্রাক বের করেন তখন কী হয়? প্রতিক্রিয়া: যখন একটি সুইচগিয়ার সার্কিট ব্রেকার ট্রাক "র্যাক আউট" হয়, এর অর্থ হল ট্রাকের সমস্ত সার্কিট ব্রেকার খোলা হয়েছে এবং ট্রাকটি একটি অ-শক্তিযুক্ত অবস্থায় রয়েছে৷ এটি সাধারণত করা হয় যখন ট্রাক সার্ভিসিং, মেরামত বা পরিদর্শন করা হয়। একবার সার্কিট ব্রেকারগুলি র্যাক আউট হয়ে গেলে, ট্রাকটি কাজ করার জন্য নিরাপদ এবং প্রয়োজনীয় রক্ষণাবেক্ষণ বা মেরামত সম্পন্ন হয়ে গেলে পুনরায় সক্রিয় করা যেতে পারে। এই উদাহরণটি এলএলএম-এর অভ্যন্তরীণ জ্ঞানকে প্রশ্ন করে। মডেলটি সুইচগিয়ার সম্পর্কে অনেক কিছু জানে বলে মনে হয়েছিল। যাইহোক, যখন আমি এর যুক্তির ক্ষমতা পরীক্ষামূলকভাবে পরীক্ষা করার চেষ্টা করেছি, তখন এটি একটি খুব অদ্ভুত ফলাফল তৈরি করেছে: নির্দেশ: একটি প্রকল্প সম্পর্কে নীচের তথ্য দেওয়া, প্রশ্নের উত্তর. চাইনিজ-লামা-2 প্রকল্পের লক্ষ্য চীনা ভাষায় বৃহৎ ভাষার মডেল লামা-2-এর বোঝাপড়া, প্রজন্ম, অনুবাদ ক্ষমতা বাড়ানো। LoRA ফাইন-টিউনিং, ফুল-প্যারামিটার ইন্সট্রাকশন ফাইন-টিউনিং এবং সেকেন্ডারি প্রাক-প্রশিক্ষণের মতো পদ্ধতির প্রয়োগের সাথে, আমরা আপনাকে সংশ্লিষ্ট ডেটাসেট, প্রশিক্ষণ গাইড এবং মডেল প্যারামিটার ডাউনলোড এবং ব্যবহার করার জন্য আন্তরিকভাবে আমন্ত্রণ জানাচ্ছি। ইনপুট: এই প্রকল্পে কি পদ্ধতি ব্যবহার করা হয়? প্রতিক্রিয়া: চীনা-লামা-2 প্রকল্পের লক্ষ্য চীনা ভাষায় বৃহৎ ভাষার মডেল লামা-2-এর বোঝাপড়া, প্রজন্ম, অনুবাদ ক্ষমতা বৃদ্ধি করা। LoRA ফাইন-টিউনিং, ফুল-প্যারামিটার ইন্সট্রাকশন ফাইন-টিউনিং এবং সেকেন্ডারি প্রাক-প্রশিক্ষণের মতো পদ্ধতির প্রয়োগের সাথে, আমরা আপনাকে সংশ্লিষ্ট ডেটাসেট, প্রশিক্ষণ গাইড এবং মডেল প্যারামিটার ডাউনলোড এবং ব্যবহার করার জন্য আন্তরিকভাবে আমন্ত্রণ জানাচ্ছি।</s> আপনি দেখতে পাচ্ছেন, মডেলটি প্রম্পট পুনরাবৃত্তি করতে পছন্দ করে। আমি এটিকে মডেল বলি, এবং অন্যান্য বিকাশকারীরাও এই আচরণের প্রতিবেদন করেছে। প্রশ্নগুলির উত্তর দেওয়ার ক্ষমতা শুধুমাত্র আরও যত্ন সহকারে ডিজাইন করা প্রম্পটগুলির সাথে আরও ভাল হয়৷ এই আচরণটি আমরা একটি উত্পাদন ব্যবস্থায় যা চাই তা নয়, কারণ আমরা বিভিন্ন মডেল জুড়ে তাত্ক্ষণিক কার্যকারিতার গ্যারান্টি দিতে পারি না। মডেলগুলিকে প্রম্পটের প্রতি কম সংবেদনশীল হতে হবে। আমরা কোনো না কোনোভাবে এই এলএলএম-এর কর্মক্ষমতা উন্নত করতে চাই। প্রম্পট-রিপিটার রেপো ইস্যুতে পরবর্তী সেশনে, আমি আলোচনা করব কি কারণে এই সমস্যাটি হয়েছে এবং কিভাবে ফাইন-টিউনিং ফলাফল উন্নত করা যায়। দ্বিতীয় প্রচেষ্টা এবং (কিছুটা) সাফল্য এখানে 3টি জিনিস রয়েছে যা আমি ফাইন-টিউনিং ফলাফল উন্নত করার চেষ্টা করেছি: প্রম্পটে ক্ষতি মাস্ক করুন (তাত্ক্ষণিক পুনরাবৃত্তি এড়াতে সহায়তা করে) বিকল্পটি বন্ধ করুন (কর্মক্ষমতা উন্নত করতে সাহায্য করে, ক্ষতির বক্ররেখাকে মসৃণ দেখায়) group-by-length eval ক্ষতি বক্ররেখা বিশ্বাস করবেন না. এমন একটি চেকপয়েন্ট ব্যবহার করুন যেখানে কম প্রশিক্ষণের ক্ষতি হয়, যদিও এর ইভাল লস "সেরা" চেকপয়েন্টের চেয়ে বেশি হতে পারে। (কার্যক্ষমতা উন্নত করতে সাহায্য করে, যেহেতু ইভাল লস এখানে সেরা ম্যাট্রিক্স নয়) এই 3টি পয়েন্ট একে একে ব্যাখ্যা করা যাক। প্রম্পট উপর ক্ষতি মাস্ক আউট আমি এই এবং না পাওয়া পর্যন্ত আমি দ্রুত পুনরাবৃত্তির কারণ খুঁজছিলাম। তারা পরামর্শ দিয়েছে যে ক্ষতির হিসাব থেকে প্রম্পট বাদ দেওয়া উচিত। মূলত, আপনি মডেলটিকে প্রম্পট টোকেন আউটপুট করতে উত্সাহিত করতে চান না। প্রশিক্ষণের সময় প্রম্পটগুলি মাস্ক করা মডেলটিকে প্রম্পট টোকেনগুলি পুনরাবৃত্তি করতে উত্সাহিত করবে না। নীচের চার্টটি এটি ব্যাখ্যা করে: 3টি প্রশিক্ষণের মধ্যে, একমাত্র রান যা প্রশিক্ষণের সময় প্রম্পটগুলিকে মুখোশ দেয়নি। এর প্রশিক্ষণের ক্ষতি এইভাবে শুরুতে বেশি হয়। আমি সন্দেহ করি যে যদি ক্ষতি গণনা করার সময় প্রম্পটগুলি মুখোশ না থাকে, এবং প্রশিক্ষণ অপর্যাপ্ত হয়, তাহলে নির্দেশাবলী অনুসরণ করার পরিবর্তে মডেলটি প্রম্পটগুলি পুনরাবৃত্তি করার সম্ভাবনা বেশি হবে৷ পোস্টটি অফিসিয়াল লোরা ওজন কমিট বার্তা stoic-star-6 ক) খ) উত্স কোডে, ক্ষতির মাস্কিং প্রম্পট টোকেন -100 সেট করে করা হয়: সেট করা সূচক সহ টোকেনগুলি উপেক্ষা করা হয় (মাস্ক করা), ক্ষতি শুধুমাত্র এ লেবেল সহ টোকেনগুলির জন্য গণনা করা হয়। -100 [0, ..., config.vocab_size] বিকল্পটি বন্ধ করুন group-by-length বিকল্পটি আলিঙ্গনফেসের একই দৈর্ঘ্যের ইনপুটগুলিকে ব্যাচগুলিতে গোষ্ঠীভুক্ত করার অনুমতি দেয়। ইনপুট সিকোয়েন্স প্যাড করার সময় এটি VRAM ব্যবহার সংরক্ষণ করতে সাহায্য করে। যাইহোক, এটি একটি একক ব্যাচের মধ্যে নমুনা বৈচিত্র্যকে ব্যাপকভাবে হ্রাস করবে। প্রশিক্ষণ প্রক্রিয়া চলাকালীন, আমরা সাধারণত মডেলটিকে বিভিন্ন প্রশিক্ষণের নমুনার কাছে প্রকাশ করতে পছন্দ করি। এ সেট করা হলে নমুনার বৈচিত্র্য কমে যায়। এটি প্রশিক্ষণের সময় ক্ষতির ওঠানামাও করে (উদাহরণস্বরূপ, পরপর দুটি ব্যাচের প্যাডেড দৈর্ঘ্য 10 এবং 50। ছোট ব্যাচের কম ক্ষতি হয় এবং দীর্ঘ ব্যাচের ক্ষতি বেশি হয়। এর ফলে একটি দোদুল্যমান ক্ষতি বক্ররেখা দেখা যায়, যেমন চিত্রে দেখানো হয়েছে। নিচে). group-by-length Trainer group-by-length False অন্যদিকে, যেহেতু ইন-ব্যাচ স্যাম্পল ভ্যারিয়েশন কমিয়ে দেয়, তাই আমি সন্দেহ করি মডেলের পারফরম্যান্সও এতে ক্ষতিগ্রস্থ হতে পারে। নীচের চিত্রটি সাথে বা ছাড়া প্রশিক্ষণের ক্ষতির তুলনা করে। এটা স্পষ্ট যে চালানোর জন্য গড় ক্ষয়ক্ষতি বেশি, যার চালু আছে। group-by-length group-by-length peach-violet-19 group-by-length eval ক্ষতি বক্ররেখা বিশ্বাস করবেন না আমি লক্ষ্য করেছি যে আমার সমস্ত রানে ট্রেনিং লস এবং ইভাল লস আলাদা হয়ে গেছে। এখানে একটি উদাহরণ: এই উদাহরণে, সর্বোত্তম চেকপয়েন্টটি এর কাছাকাছি ঘটে। আপনি যদি আসল দ্বারা প্রস্তাবিত সর্বোত্তম চেকপয়েন্টটি লোড করেন তবে আপনি পূর্ববর্তী সেশনে উল্লিখিত হিসাবে একটি মডেল পাওয়ার সম্ভাবনা বেশি। epoch=2 রেপো প্রম্পট-রিপিটার প্রশিক্ষণের শেষের কাছাকাছি একটি মডেল চেকপয়েন্ট লোড করার মাধ্যমে, আমি আরও পারফরম্যান্স মডেল পেয়েছি। আমি আগের মত একই প্রশ্ন জিজ্ঞাসা করেছি এবং মডেল সঠিক উত্তর ফিরিয়ে দিয়েছে: নির্দেশ: একটি প্রকল্প সম্পর্কে নীচের তথ্য দেওয়া, প্রশ্নের উত্তর. চাইনিজ-লামা-2 প্রকল্পের লক্ষ্য চীনা ভাষায় বৃহৎ ভাষার মডেল লামা-2-এর বোঝাপড়া, প্রজন্ম, অনুবাদ ক্ষমতা বাড়ানো। LoRA ফাইন-টিউনিং, ফুল-প্যারামিটার ইন্সট্রাকশন ফাইন-টিউনিং এবং সেকেন্ডারি প্রাক-প্রশিক্ষণের মতো পদ্ধতির প্রয়োগের সাথে, আমরা আপনাকে সংশ্লিষ্ট ডেটাসেট, প্রশিক্ষণ গাইড এবং মডেল প্যারামিটার ডাউনলোড এবং ব্যবহার করার জন্য আন্তরিকভাবে আমন্ত্রণ জানাচ্ছি। ইনপুট: এই প্রকল্পে কি পদ্ধতি ব্যবহার করা হয়? প্রতিক্রিয়া: চাইনিজ-লামা-2 প্রকল্পটি LoRA ফাইন-টিউনিং, ফুল-প্যারামিটার নির্দেশনা ফাইন-টিউনিং এবং সেকেন্ডারি প্রাক-প্রশিক্ষণের মতো পদ্ধতি ব্যবহার করে। কিন্তু মূল্যায়ন ক্ষতি দ্বারা বিচার, এই মডেল খারাপ সঞ্চালন করা উচিত. কি কারণে দ্বিধা? আমি মনে করি বৃহৎ ভাষা মডেল কর্মক্ষমতা পরিমাপের জন্য মূল্যায়ন ক্ষতি একটি ভাল ম্যাট্রিক্স নয়। LLaMA প্রশিক্ষণ এবং মূল্যায়ন ক্ষতির জন্য ব্যবহার করে: CrossEntropyLoss # modelling_llama.py from transformers library ... # forward function under LlamaForCausalLM class if labels is not None: # Shift so that tokens < n predict n shift_logits = logits[..., :-1, :].contiguous() shift_labels = labels[..., 1:].contiguous() # Flatten the tokens loss_fct = CrossEntropyLoss() loss = loss_fct(shift_logits.view(-1, self.config.vocab_size), shift_labels.view(-1)) একটি মূল্যায়ন সেটে পরীক্ষা করার সময়, একটি মডেল বিভিন্ন শব্দের সাথে একই উত্তর তৈরি করতে পারে: { "evaluation prompt": "What is 1 + 3?" "evaluation answer": "4." "prediction answer": "The answer is 4." } উভয় উত্তরই সঠিক, কিন্তু যদি ভবিষ্যদ্বাণীর উত্তর মূল্যায়নের উত্তরের সাথে সঠিক মিল না হয়, তাহলে মূল্যায়নের ক্ষতি বেশি হবে। এই ক্ষেত্রে, মডেলের কর্মক্ষমতা পরিমাপ করার জন্য আমাদের একটি ভাল মূল্যায়ন ম্যাট্রিক্স প্রয়োজন। আমরা পরে সঠিক মূল্যায়ন সম্পর্কে চিন্তা করব। আপাতত, অনুমান করা যাক সেরা মডেলটি হল সবচেয়ে কম প্রশিক্ষণের ক্ষতি সহ। 7B পেরিয়ে যাওয়া আমি V100 এ একটি 13B মডেল ফাইন-টিউন করার চেষ্টা করেছি। যদিও V100 একটি 7B মডেলে int8 এবং fp16 উভয় প্রশিক্ষণই পরিচালনা করতে পারে, এটি কেবল 13B মডেলে int8 প্রশিক্ষণ পরিচালনা করতে পারে না। যদি , 13B মডেলটি উৎপন্ন করবে। কেন এটি ঘটে তা বোঝার জন্য আমরা কিছু ডিবাগিং সরঞ্জাম ব্যবহার করতে পারি ( এটি ওভারফ্লো/আন্ডারফ্লো দ্বারা সৃষ্ট)। load_int_8bit = True training_loss = 0.0 স্পয়লার সতর্কতা: প্রশিক্ষণের সময় পরামিতি পরিদর্শন করতে আমি huggingface এর টুল ব্যবহার করেছি। প্রথম ফরওয়ার্ড পাসে, এটি inf/nan মান সনাক্ত করেছে: DebugUnderflowOverflow আরও নির্দিষ্টভাবে, এর 2য় ইনপুটে নেতিবাচক অসীম মান ধরেছে, যেমনটি নীচের চিত্রে দেখানো হয়েছে। 2য় ইনপুট হল । আমি একটু গভীরে ডুব দিয়ে দেখেছি যে প্যাডিং উপাদানগুলির জন্য খুব বড় নেতিবাচক মান রয়েছে বলে মনে করা হয়। কাকতালীয়ভাবে, ঋণাত্মক অসীম মান প্রতিটি অনুক্রমের শুরুতে থাকে। এই পর্যবেক্ষণ আমাকে বিশ্বাস করে যে নেতিবাচক অসীম মান এই স্তরে ঘটতে অনুমিত হয়। আরও তদন্তে আরও দেখা গেছে যে অনন্ত মান পরবর্তী কয়েকটি স্তরে আরও অসীম মান সৃষ্টি করেনি। অতএব, এ ওভারফ্লো সম্ভবত অস্বাভাবিক প্রশিক্ষণ ক্ষতির মূল কারণ নয়। DebugUnderflowOverflow LlamaDecoderLayer attention_mask attention_mask LlamaDecoderLayer পরবর্তী, আমি প্রতিটি স্তরের আউটপুট পরিদর্শন করেছি। এটি খুব স্পষ্ট ছিল যে চূড়ান্ত স্তরগুলির আউটপুটগুলি উপচে পড়ছে, যেমনটি নীচের চিত্রে দেখানো হয়েছে। আমি বিশ্বাস করি যে এটি int-8 ওজনের সীমিত নির্ভুলতার কারণে হয়েছে (বা এর সীমিত পরিসর। সম্ভবত এই সমস্যাটি এড়াতে পারে)। float16 bfloat16 ওভারফ্লো সমস্যা সমাধানের জন্য, আমি প্রশিক্ষণের সময় float16 ব্যবহার করেছি। 13B মডেলের প্রশিক্ষণের জন্য V100 এর যথেষ্ট VRAM নেই যদি না কিছু কৌশল ব্যবহার করা হয়। প্রশিক্ষণ VRAM ব্যবহার কমাতে CPU অফলোডিং এর মত বিভিন্ন পদ্ধতি প্রদান করে। কিন্তু সবচেয়ে সহজ কৌশল হল ট্রেনিং শুরুর আগে কল করে গ্রেডিয়েন্ট চেকপয়েন্টিং সক্ষম করা। আলিঙ্গন ফেস ডিপস্পিড model.gradient_checkpointing_enable() গ্রেডিয়েন্ট চেকপয়েন্টিং কম VRAM ব্যবহারের জন্য প্রশিক্ষণের গতি বন্ধ করে। সাধারণত, ফরোয়ার্ড পাসের সময়, অ্যাক্টিভেশনগুলি গণনা করা হয় এবং ব্যাকওয়ার্ড পাসের সময় ব্যবহারের জন্য মেমরিতে সংরক্ষণ করা হয়। এটি অতিরিক্ত মেমরি গ্রহণ করে। যাইহোক, গ্রেডিয়েন্ট চেকপয়েন্টিংয়ের সাথে, ফরওয়ার্ড পাসের সময় অ্যাক্টিভেশনগুলি সংরক্ষণ করার পরিবর্তে, পিছনের পাসের সময় সেগুলি পুনরায় গণনা করা হয়, এইভাবে VRAM সংরক্ষণ করা হয়। এখানে এই কৌশল সম্পর্কে একটি চমৎকার আছে. নিবন্ধ আমি Llama 13B কে float16 এবং গ্রেডিয়েন্ট চেকপয়েন্টিং সক্ষম করে প্রশিক্ষণ দিতে সক্ষম হয়েছি: python finetune.py \ --base_model=yahma/llama-13b-hf \ --num_epochs=10 \ --output_dir 'your/output/dir' \ --lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \ --cutoff_len=1024 \ --lora_r=16 \ --micro_batch_size=4 \ --batch_size=128 \ --wandb_project 'alpaca_lora_13b' \ --train_on_inputs=False 13B মডেল কিছু উন্নত কাজ পরিচালনা করতে পারে যেমন নাম সত্তা স্বীকৃতি। আমি পরীক্ষার জন্য ব্যবহার করি এবং এটি 13B মডেলের সঠিক প্রতিক্রিয়া: একটি উদাহরণ প্রম্পট সব ভালো! এটি একটি উত্তেজনাপূর্ণ শুরু. মডেলটি আমাদের LangChain এর সাথে জটিল অ্যাপ্লিকেশন তৈরি করতে দেয়। এই মুহুর্তে, আমরা এখনও স্বয়ংক্রিয় মডেল মূল্যায়নের জন্য সরঞ্জামগুলি অনুপস্থিত। আমরা অনেক পরীক্ষার ক্ষেত্রে আমাদের মডেলগুলিকে মূল্যায়ন করতে ভাষা মডেল মূল্যায়ন হারনেস ব্যবহার করতে পারি, বা এমনকি আমাদের নিজস্ব পরীক্ষার ক্ষেত্রেও তৈরি করতে পারি। এটি একই টুল যা Hugging Face তার Open LLM লিডারবোর্ডের জন্য ব্যবহার করে। যদিও মূল্যায়ন এলএলএম বিকাশের একটি গুরুত্বপূর্ণ দিক, এই নিবন্ধটি শুধুমাত্র প্রশিক্ষণ প্রক্রিয়ার উপর দৃষ্টি নিবদ্ধ করে। আমি ভবিষ্যতে একটি নিবন্ধে মূল্যায়ন আলোচনা করতে পারে. সারসংক্ষেপ এই নিবন্ধে, আমরা বৃহৎ ফাউন্ডেশন মডেল (LFMs) এবং বেশ কিছু সূক্ষ্ম-টিউনিং পদ্ধতির ধারণা প্রবর্তন করেছি যা LFM-কে পছন্দসই আচরণ করে। আমরা তখন LoRA-তে ফোকাস করেছি, LFM ফাইন-টিউনিং করার জন্য একটি প্যারামিটার-দক্ষ পদ্ধতি, এবং ফাইন-টিউনিং কোডের পাশাপাশি পারফরম্যান্সের উন্নতির কৌশলগুলি ব্যাখ্যা করেছি। অবশেষে, আমরা আরও এক ধাপ এগিয়ে গিয়ে একটি V100 GPU-তে একটি Llama 13B মডেলকে সফলভাবে প্রশিক্ষণ দিয়েছি। যদিও 13B মডেল প্রশিক্ষণ কিছু সমস্যায় পড়েছিল, আমরা দেখতে পেয়েছি যে এই সমস্যাগুলি হার্ডওয়্যার সীমাবদ্ধতা দ্বারা আরোপ করা হয়েছিল এবং সমাধানগুলি উপস্থাপন করা হয়েছিল। শেষ পর্যন্ত, আমরা একটি সূক্ষ্ম সুরযুক্ত LLM পেয়েছি যা কাজ করে, কিন্তু আমরা এখনও পরিমাণগতভাবে LLM-এর কর্মক্ষমতা মূল্যায়ন করিনি। লেখক সম্পর্কে হ্যালো সেখানে! আমার নাম উই. আমি একজন নিবেদিত সমস্যা সমাধানকারী, সিনিয়র এআই স্পেশালিস্ট এবং এর অ্যানালিটিক্স প্রোজেক্ট লিড এবং । আমি ইউনিভার্সিটি অফ মিনেসোটা টুইন সিটিস থেকে মেকানিক্যাল ইঞ্জিনিয়ারিং-এ এমএস এবং আরবানা-চ্যাম্পেইনের ইলিনয় বিশ্ববিদ্যালয় থেকে মেকানিক্যাল ইঞ্জিনিয়ারিংয়ে বিএস ডিগ্রি নিয়েছি। ABB- মেশিন লার্নিং গুগল ডেভেলপার এক্সপার্ট আমার টেক স্ট্যাক Python/C# প্রোগ্রামিং, কম্পিউটার ভিশন, মেশিন লার্নিং, অ্যালগরিদম এবং মাইক্রো-সার্ভিসগুলিতে ফোকাস করে, কিন্তু আমার কাছে গেম ডেভেলপমেন্ট (ইউনিটি), ফ্রন্ট/ব্যাক-এন্ড ডেভেলপমেন্ট, প্রযুক্তিগত নেতৃত্বের মতো বিস্তৃত আগ্রহও রয়েছে। একক বোর্ড কম্পিউটার এবং রোবোটিক্স সঙ্গে tinkering. আমি আশা করি এই নিবন্ধটি কিছু উপায়ে লোকেদের সাহায্য করতে পারে। পড়ার জন্য ধন্যবাদ, এবং খুশি সমস্যা সমাধান!