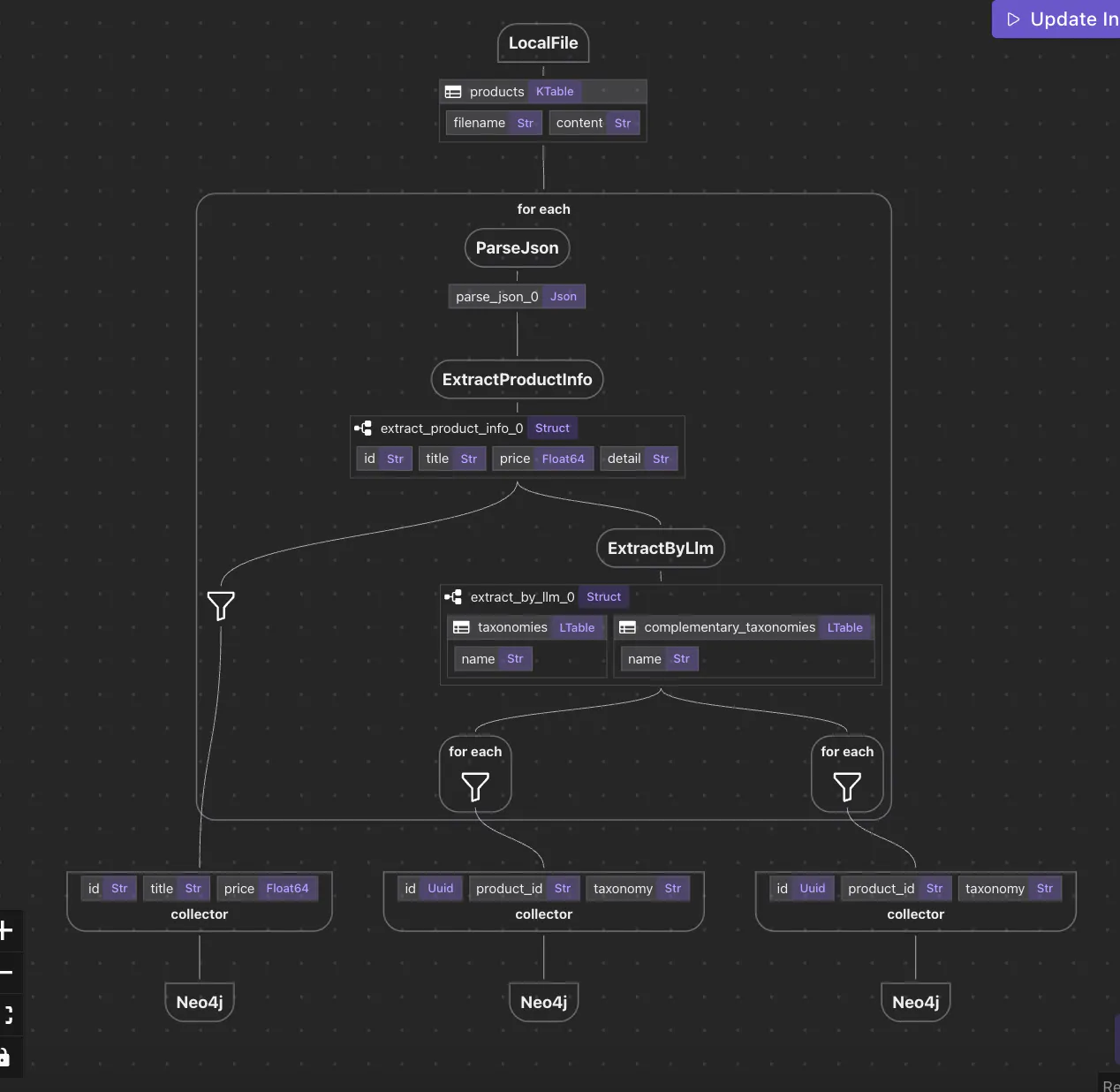
في معظم إطارات التخطيط البيانات ، فإن طريقة معالجة البيانات هي تفكيرًا آخر. يمكنك بناء تدفقات العمل ، وتجميع المكونات معًا ، ونأمل أن تتصرف البيانات كما تتوقع. تحت القفص ، يتم تغيير القيم ، وتغييرًا ملموسًا ، أو مخفية في المكونات المستقيمة. إذا كنت تحب هذه المقالة ، يرجى إخفاء لنا ستار ⭐ في القفص لمساعدتنا على النمو. GitHub Repo ولكن CocoIndex يترك هذا النهج على رأسه. بعد أن عملنا في هذا المجال لعدة سنوات، وجدنا أن الآثار الجانبية في الأنظمة التقليدية غالبا ما تؤدي إلى زيادة المعقدة، والتحديات في التحكم، وممارسات غير متوقعة. بدلاً من معالجة البيانات كمحطة سوداء تنتقل بين المهام، أين هي البيانات وتغييرها هذا التغيير يجعل عالمًا من الفرق عندما تعمل مع أنابيب معقدة - وخاصة في استخراج المعرفة، وبناء الخرائط، والبحث السلمي. CocoIndex embraces the Data Flow Programming paradigm observable, traceable, and immutable ما هو برنامج تدفق البيانات؟ هو نموذج البرمجة الإعلانية حيث: برنامج Data Flow البيانات "تنقل" من خلال جدول تحويلات. كل تحول بسيط - لا تأثيرات جانبية مخفية، ولا تفاعلات حالة. إن هيكل رمزك يعكس هيكل منطق بياناتك. هذا يختلف بشكل أساسي من محركات عمل، حيث يتم تركيب المهام في الوقت، والبيانات غالبا ما تكون غير متواضعة. في CocoIndex ، لا المهمات data is the primary unit of composition إرسال بيانات بسيطة في CocoIndex دعونا نلقي نظرة على حركة البيانات المعقدة: Parse files → Data Mapping → Data Extraction → Knowledge Graph وتشكل كل ذراع تحولًا: وظيفة تستخدم البيانات وتنتج البيانات الجديدة، ويجعل النتيجة سلسلة من الخطوات قابلة للتعقب حيث يمكنك التحقق من كل من الملفات والمفاتيح - في أي نقطة. وتشكل كل ذراع تحولًا: وظيفة تستخدم البيانات وتنتج البيانات الجديدة، ويجعل النتيجة سلسلة من الخطوات قابلة للتعقب حيث يمكنك التحقق من كل من الملفات والمفاتيح - في أي نقطة. كل غرفة في هذه الشاشة تعكس لا تأثيرات جانبية، لا منطق مخفي. declarative transformation نموذج الكود: الإعلانية والتفصيلية إليكم كيف يمكن أن تبدو هذه الدورة في CocoIndex: # ingest data['content'] = flow_builder.add_source(...) # transform data['out'] = data['content'] .transform(...) .transform(...) # collect data collector.collect(...) # export to db, vector db, graph db ... collector.export(...) الجمال هنا هو هذا: كل .transform() هو تحديد وتتبع. أنت لا تكتب منطق CRUD - أرقام CocoIndex التي. يمكنك مشاهدة جميع البيانات قبل وبعد أي مرحلة. لا مبررات ملموسة - فقط المنطق في الأنظمة التقليدية ، يمكنك كتابة: if entity_exists(id): update_entity(id, data) else: create_entity(id, data) ولكن في CocoIndex ، تقول: data['entities'] = data['mapped'].transform(extract_entities) ويعرف النظام ما إذا كان هذا يعني إنشاء، التحديث، أو إزالة. تتيح لك التركيز على ما يهمك حقا: كيف يجب أن تكون البيانات الخاصة بك. وليس كيفية تخزينها. abstracts away lifecycle logic derived لماذا هذا يهم: فوائد تدفق البيانات في CocoIndex إطار البيانات الكامل مع نموذج تدفق البيانات CocoIndex ، يمكنك العثور عليه من خلال كل تحويل إلى الملف أو المجال الأصلي. التفكير في كل خطوة CocoIndex يتيح لك مشاهدة البيانات في أي مرحلة. بدلاً من الأنابيب الضوئية. significantly easier النشاط تغيير مصدر؟ يتم تقييم كل تحول في النهاية تلقائيًا. CocoIndex يسمح للطائرات المضادة دون تعقيدات إضافية. ♀️ الكلمات الدلالية أنت لا تتعامل مع الاختلاط، أو أخطاء في تنزيل الوضع، أو التنسيق اليدوي. أنت تحدد المنطق مرة واحدة - وتسمح للنقل البيانات. تغيّر الخيال في تطبيقات بيانات البناء نموذج برمجة تدفق البيانات لـ CocoIndex ليس مجرد ميزة، بل هو ميزة تغير طريقة تفكيرك حول معالجة البيانات: philosophical shift من التحكم في المهام إلى تحويل البيانات من الطائرات المتغيرة إلى المراقبة غير المتغيرة من الكود الحقيقي إلى النماذج الإعلانية هذا يجعل خطوطك . easier to test, easier to reason about, and easier to extend الأفكار النهائية إذا كنت تخطط لإنشاء خطوط للخروج من المؤسسة، أو البحث، أو الخرائط المعرفة، لا تحتاج إلى تجميد عمليات تخزين أو مراقبة تغييرات المستوى - أنت فقط تحدد كيفية تحويل البيانات. CocoIndex’s data flow programming model offers a new kind of clarity وهذا هو المستقبل الذي يستحق بناءه. نحن نغير دائمًا، وأكثر الميزات والمثالات ستأتي قريبًا.إذا كنت تحب هذا المقال، يرجى تثبيتنا نجمة ⭐ في لمساعدتنا على النمو. GitHub Repo