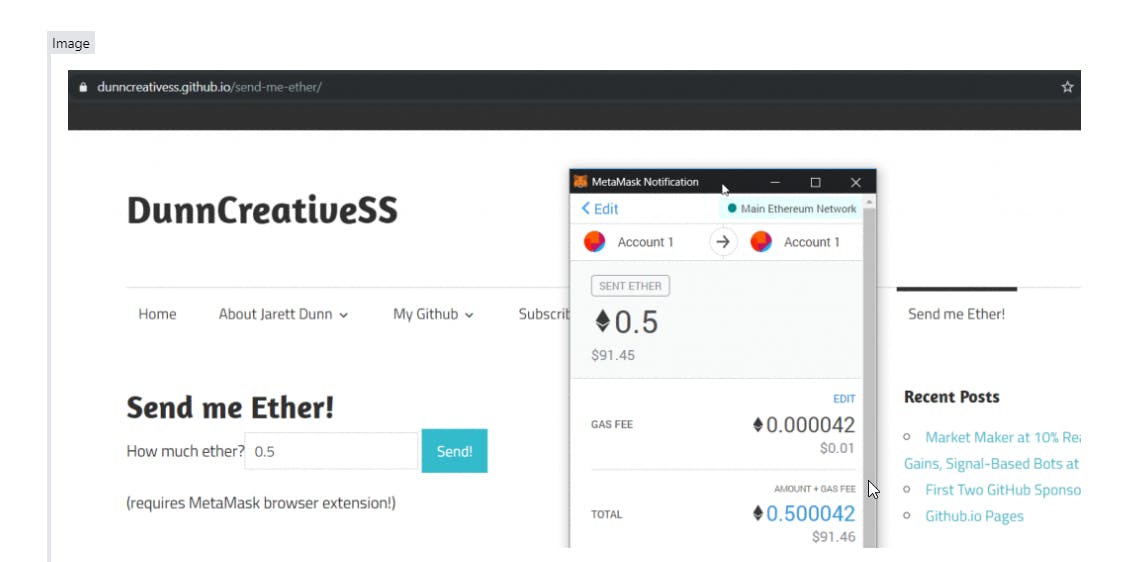
Speech and language processing. At the end of the beginning.
Story's Credibility


Speech and language processing. At the end of the beginning.
Story's Credibility
About Author

Speech and language processing. At the end of the beginning.
KOMMENTAAR

Speech and language processing. At the end of the beginning.
Speech and language processing. At the end of the beginning.
Speech and language processing. At the end of the beginning.