
838 reads
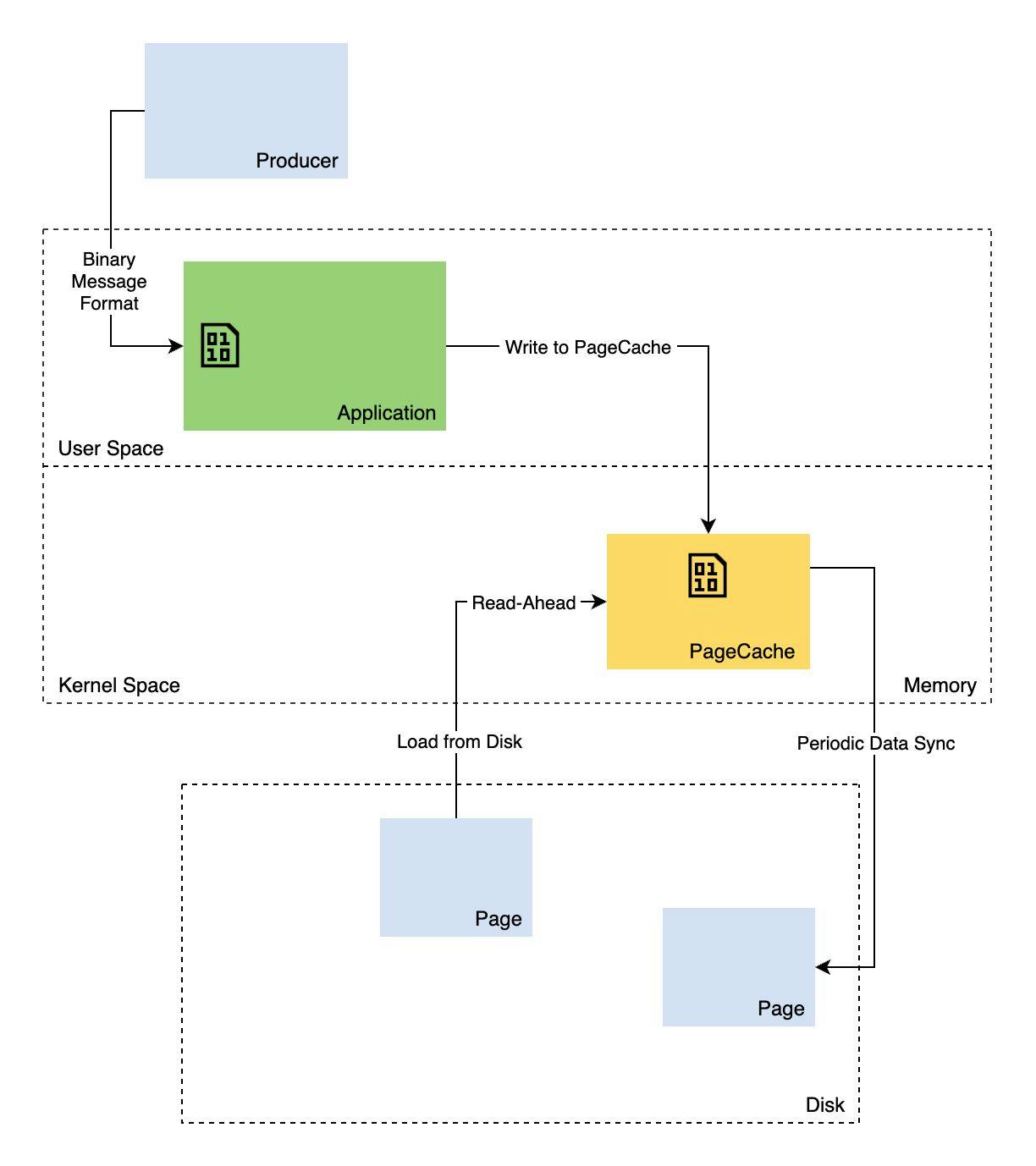
Kafka Storage Design - Making File Systems Cool Again!
by
September 27th, 2022






Story's Credibility


Story's Credibility
About Author

Building ML & Data Platforms at MongoDB 🍃
Comments

TOPICS
THIS ARTICLE WAS FEATURED IN





Related Stories










9 Data Trends You’ll See in 2023

Jan 10, 2023


9 Data Trends You’ll See in 2023
Jan 10, 2023