139 reads
AWS S3 .NET Client High Memory Usage





Too Long; Didn't Read
Reducing AWS S3 .NET client LOH allocations by 98%Companies Mentioned
Coin Mentioned




Indy Singh
@indy_singh

L O A D I N G
. . . comments & more!
. . . comments & more!
About Author

TOPICS
THIS ARTICLE WAS FEATURED IN...



RELATED STORIES


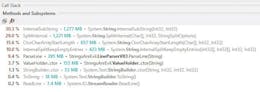
Strings Are Evil #software-development
Jun 05, 2018