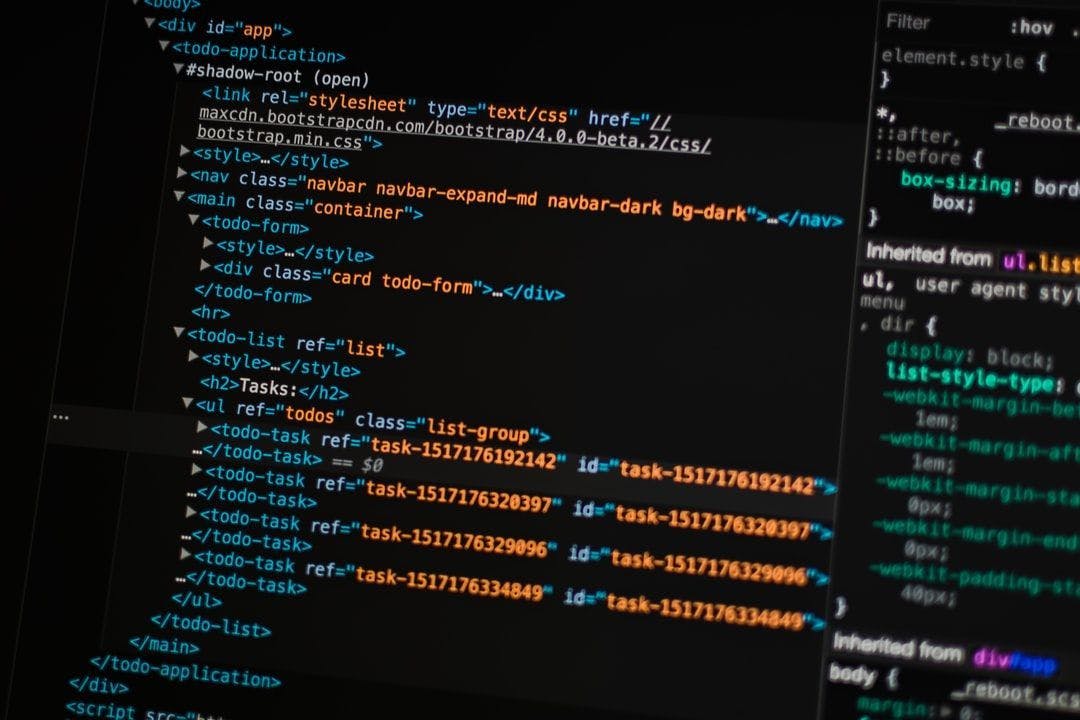
A while ago I was trying to perform an analysis of a Medium publication for a personal project. But getting the data was a problem – scraping only the publication’s home page does not guarantee that you get all the data you want. That’s when I found out that each publication has its own archive. You just have to type “/archive” after the publication URL. You can even specify a year, month, and day and find all the stories published on that date. Something like this: https://publicationURL/archive/year/month/day And suddenly the problem was solved. A very simple scraper did the job. In this tutorial, we’ll see how to code a simple but powerful web scraper that can be used to scrape any Medium publication. You can also use this scraper to scrape data from lots of different websites for whatever reason you want. Just make sure they allow scraping before you start. Since we’re learning how to scrape a Medium publication, we'll use The Startup as an example. According to the publication, The Startup is the largest active Medium publication with over 700k followers. So it should be a great source of data. In this article, you’ll see how to scrape all the articles published by The Startup in 2019. We'll also look at how this data can be useful. Intro to Web Scraping Web scraping is the process of collecting data from websites using automatized scripts. It consists of three main steps: fetching the page, parsing the HTML, and extracting the information you need. The third step is the one that can be a little tricky at first. It consists basically of finding the parts of the HTML that contain the information you want. You can find this info by opening the page you want to scrape and pressing the F12 key on your keyboard. Then you can select an element of the page to inspect. You can see this in the image below. Then all you need to do is to use the tags and classes in the HTML to inform the scraper where to find the information. You need to do this for every part of the page you want to scrape. You can see it better in the code, so let's go there next. The Code As this is a simple scraper, we’ll only use , , and . requests BeautifulSoup Pandas Requests will be used to get the pages we need, while BeautifulSoup parses the HTML. We'll use Pandas to store the data in a DataFrame and then export it as a file. .csv So we’ll begin by importing these libraries and initializing an empty list to store the data. This list will be filled with other lists. pandas pd bs4 BeautifulSoup requests stories_data = [] import as from import import As I mentioned earlier, the Medium archive stores the stories by the date of publication. As we want to scrape every story published in The Startup in 2019, we need to iterate over every day of every month of that year. We’ll use nested loops to iterate over the months of the year and then over the days of each month. for To do this, it is important to differentiate the number of days in each month. It’s also important to make sure all days and months are represented by two-digit numbers. month range( , ): month [ , , , , , , ]: n_days = month [ , , , ]: n_days = : n_days = day range( , n_days + ): month, day = str(month), str(day) len(month) == : month = len(day) == : day = for in 1 13 if in 1 3 5 7 8 10 12 31 elif in 4 6 9 11 30 else 28 for in 1 1 if 1 f'0 ' {month} if 1 f'0 ' {day} And now the scraping begins. We can use the month and day to set up the date that will also be stored along with the scraped data and, of course, that creates the URL for that specific day. When this is done, we can just use to get the page and parse the HTML with . requests BeautifulSoup date = url = page = requests.get(url) soup = BeautifulSoup(page.text, ) f' / /2019' {month} {day} f'https://medium.com/swlh/archive/2019/ / ' {month} {day} 'html.parser' So this is The Startup’s archive page for January 1st, 2019. We can see that each story is stored in a container. What we need to do is to grab all these containers. To do this, we’ll use the method. find_all stories = soup.find_all( , class_= ) 'div' 'streamItem streamItem--postPreview js-streamItem' The above code generates a list containing all the story containers on the page. Something like this: All we need to do now is to iterate over it and grab the information we want from each story. We’ll scrape: The author’s URL, from which we can later extract the author’s username if we want to The reading time The story title and subtitle The number of claps and responses The story URL from the button. Read more… We’ll first select a box inside the container that I call the . From this box, we’ll extract the author's URL and the reading time. author’s box And here is our only condition in this scraper: if the container does not show a reading time, we’ll not scrape this story and instead move to the next one. This is because such stories contain only images and one or two lines of text. We’re not interested in those as we can think of them as outliers. We’ll use the and blocks to handle those cases. try except Other than that, we must be prepared if a story doesn't have a title or a subtitle (yes, that happens) and if it doesn't have claps or responses. The clause will do the job of preventing an error from being raised in such situations. if All this scraped information will later be appended to the list that is initialized in the loop. This is the code for all this: each_story story stories: each_story = [] author_box = story.find( , class_= ) author_url = author_box.find( )[ ] : reading_time = author_box.find( , class_= )[ ] : title = story.find( ).text story.find( ) subtitle = story.find( ).text story.find( ) story.find( , class_= ): claps = story.find( , class_= ).text : claps = story.find( , class_= ): responses = story.find( , class_= ).text : responses = story_url = story.find( , class_= )[ ] for in 'div' 'postMetaInline u-floatLeft u-sm-maxWidthFullWidth' 'a' 'href' try 'span' 'readingTime' 'title' except continue 'h3' if 'h3' else '-' 'h4' if 'h4' else '-' if 'button' 'button button--chromeless u-baseColor--buttonNormal js-multirecommendCountButton u-disablePointerEvents' 'button' 'button button--chromeless u-baseColor--buttonNormal js-multirecommendCountButton u-disablePointerEvents' else 0 if 'a' 'button button--chromeless u-baseColor--buttonNormal' 'a' 'button button--chromeless u-baseColor--buttonNormal' else '0 responses' 'a' 'button button--smaller button--chromeless u-baseColor--buttonNormal' 'href' Cleaning some data Before we move to scrape the text of the stories, let’s first do a little cleaning in the and data. reading_time responses Instead of storing these variables as “5 min read” and “5 responses”, we’ll keep only the numbers. These two lines of code will get this done: reading_time = reading_time.split()[ ] responses = responses.split()[ ] 0 0 Back to scraping… We'll now scrape the article page. We’ll use once more to get the page, and to parse the HTML. requests story_url BeautifulSoup From the article page, we need to find all the tags, which are where the text of the article is located. We’ll also initialize two new lists, one to store the article’s paragraphs and the other to store the title of each section in the article. section story_page = requests.get(story_url) story_soup = BeautifulSoup(story_page.text, ) sections = story_soup.find_all( ) story_paragraphs = [] section_titles = [] 'html.parser' 'section' And now we only need to loop through the sections. For each section, we will: Find all paragraphs and append them to the paragraphs list Find all section titles and append them to the section titles list Use these two lists to calculate the number of paragraphs and the number of sections in the article, as this could be some useful data to have. section sections: paragraphs = section.find_all( ) paragraph paragraphs: story_paragraphs.append(paragraph.text) subs = section.find_all( ) sub subs: section_titles.append(sub.text) number_sections = len(section_titles) number_paragraphs = len(story_paragraphs) for in 'p' for in 'h1' for in This will significantly increase the time it takes to scrape everything, but it will also make the final dataset much more valuable. Storing and exporting the data The scraping is now finished. Everything will now be appended to the list, which will be appended to the list. each_story stories_data each_story.append(date) each_story.append(title) each_story.append(subtitle) each_story.append(claps) each_story.append(responses) each_story.append(author_url) each_story.append(story_url) each_story.append(reading_time) each_story.append(number_sections) each_story.append(section_titles) each_story.append(number_paragraphs) each_story.append(story_paragraphs) stories_data.append(each_story) As is now a list of lists, we can easily transform it into a DataFrame and then export the DataFrame to a file. For this last step, as we have a lot of text data, I recommended that you set the separator as . stories_data .csv \t columns = [ , , , , , , , , , , , ] df = pd.DataFrame(stories_data, columns=columns) df.to_csv( , sep= , index= ) 'date' 'title' 'subtitle' 'claps' 'responses' 'author_url' 'story_url' 'reading_time (mins)' 'number_sections' 'section_titles' 'number_paragraphs' 'paragraphs' '1.csv' '\t' False The Data This is how the data looks: As you can see, we have scraped data from 21,616 Medium articles. That’s a lot! That actually means our scraper accessed almost 22 thousand Medium pages. In fact, considering one archive page for each day of the year, we just accessed (21,616 + 365 =) 21,981 pages. This huge amount of requests we made can be a problem, though. The website we’re scraping can realize the interactions are not being made by a human and this can easily get our IP blocked. There are some workarounds we can do to fix this. One solution is to insert small pauses in your code, to make the interactions with the server more human. We can use the function from and the function to achieve this: randint NumPy sleep numpy np time sleep sleep(np.random.randint( , )) # Import this import as from import # Put several of this line in different places around the code 1 15 This code will randomly choose a number of seconds from 1 to 15 for the scraper to pause. But if you’re scraping too much data, even these pauses may not be enough. In this case, you could develop your own infrastructure of IP addresses. If you want to keep it simple, however, you could also get in touch with a proxy provider (such as or others) and they will deal with this problem for you by constantly changing your IP address so you do not get blocked. Infatica But what can you do with this data? That’s something you might be asking yourself. Well, there’s always a lot to learn from data. We can perform some analysis to answer some simple questions, such as: Is the number of articles in The Startup increasing over time? What’s the average size of a story in The Startup? The charts below can help with those questions. Notice how the number of stories published per month skyrocketed in the second half of 2019. Also, the stories became around five paragraphs shorter, on average, throughout the year. And I’m talking paragraphs, but you could look for the average number of words or even characters per story. And of course, there’s Natural Language Processing — NLP. Yes, we have a lot of text data that we can use for NLP. It is possible to analyze the kind of stories that are usually published in The Startup, to investigate what makes a story receive more or fewer claps, or even to predict the number of claps and responses a new article may receive. Wrapping Up Yes, there is a lot you can do with the data, but don’t miss the point here. This article is about the scraper, not the scraped data. The main goal here is to share how powerful of a tool it can be. Also, this same concept of web scraping can be used to perform a lot of different activities. For example, you can scrape Amazon a keep track of prices, or you can build a dataset of job opportunities by scraping a job search website if you are looking for a job. The possibilities are endless, so it's up to you! If you liked this in think it may be useful to you, you can find the complete code . If you have any questions or suggestions, feel free to get in touch. here Also published on: https://datascienceplus.com/scraping-medium-publications-a-tutorial-for-beginners-with-python/