22,322 reads
Optimizing List Manipulation: Two Pointers Technique
by Leonid ZemenkovFebruary 9th, 2023





Too Long; Didn't Read
This article delves into the practical implementation of the two-pointer technique to optimize list manipulation, offering insights on reducing time complexity and memory usage for more efficient solutions.

Introduction
In the world of algorithm design and problem-solving, the two-pointer technique stands out as a powerful and widely utilized strategy. With its application extending to arrays, linked lists, and strings, this approach has proven its efficacy in reducing time complexity and, in certain cases, even eliminating the need for additional memory usage. By skilfully manipulating two pointers, we gain the ability to navigate through data structures with greater efficiency, paving the way for cleaner and more optimized solutions.
While the concept behind the two-pointer method may seem simple at first glance, the successful implementation of this technique requires careful consideration and attention to detail. Common pitfalls, such as logical errors and misconceptions, often arise during its application. Therefore, in this article, we embark on a journey to explore the intricacies of the two-pointer technique. Through a comprehensive examination of various real-world problems, we will delve into its practical implementation and unravel the key insights behind this elegant approach.
Our exploration will not only equip us with a deeper understanding of the two-pointer method but also enhance our problem-solving prowess. By the end of this discussion, we will be empowered to tackle diverse challenges with confidence, armed with the knowledge of how to wield the two-pointer technique effectively. So, let us embark on this enlightening journey and embrace the power of the two-pointer method in our pursuit of elegant and optimized solutions.
Example 1: Removing Duplicates from a Sorted Array
Task description:
Given an integer array nums sorted in non-decreasing order, remove the duplicates in-place such that each unique element appears only once. The relative order of the elements should be kept the same. Then return the number of unique elements in nums.
Example 1:
Input: nums = [1,1,2]
Output: 2, nums = [1,2,_]
Example 2:
Input: nums = [0,0,1,1,1,2,2,3,3,4]
Output: 5, nums = [0,1,2,3,4,_,_,_,_,_]
Constraints:
1 <= nums.length <= 3 * 104-100 <= nums[i] <= 100numsis sorted in non-decreasing order.
Reasoning:
Considering the task's objective is to both determine the count of unique elements and store them in the initial k cells, it is evident that using an additional data structure to track element uniqueness would be advantageous.
public int removeDuplicates(int[] nums) {
Set<Integer> uniqueElements = new HashSet<>();
int index = 0;
for (int num : nums) {
if (!uniqueElements.contains(num)) {
nums[index] = num;
uniqueElements.add(num);
index++;
}
}
return index;
}
This approach has O(N) time complexity and O(N) memory complexity.
While using additional memory to solve the problem is feasible, it can become impractical when dealing with large-sized original arrays, as the memory requirements may become unmanageable. Therefore, the challenge lies in finding a method to eliminate duplicates from the array without utilizing any extra memory, ensuring a more memory-efficient solution.
How to optimize this solution?
It is evident that the given array is sorted, which opens up new opportunities to optimize our original solution. By leveraging the sorted nature of the array, we can implement the two-pointer approach, a technique that utilizes two pointers to streamline the process.
With this approach, we employ the first pointer, labeled as next to traverse the array, while the second pointer, labeled as current serves the crucial role of identifying the position where the next unique element should be placed.
By using this strategy, we can efficiently eliminate duplicates from the sorted array without requiring any additional memory. The condition nums[i] <= nums[i+1], inherent in the sorted nature of the array, facilitates the effectiveness of the two-pointer approach, leading to a more optimized and memory-efficient solution.
public int removeDuplicates(int[] nums) {
if (nums.length == 0) return 0;
int current = 0;
for (int next = 1; next < nums.length; next++) {
if (nums[current] != nums[next]) {
nums[++current] = nums[next];
}
}
return current + 1;
}
Example 2: Remove Nth Node from end of List
Task description:
Given the head of a linked list, remove the nthnode from the end of the list and return its head.
Example 1:
Input: head = [1,2,3,4,5], n = 2
Output: [1,2,3,5]
Example 2:
Input: head = [1], n = 1
Output: []
Example 3:
Input: head = [1,2], n = 1
Output: [1]
Constraints:
- The number of nodes in the list is sz.
- 1 <= sz <= 30
- 0 <= Node.val <= 100
- 1 <= n <= sz
Reasoning:
Let’s try to do something natural. To remove the Nth node from the end, it's essential to first determine the total number of nodes in the list. By counting the number of nodes, it becomes straightforward to identify the index of node that needs to be removed. There are two possible scenarios here. The first and simplest scenario is removing a non-edge node. In this case, all we need to do is change the pointer of the previous node (next) to the node after the one that was removed.
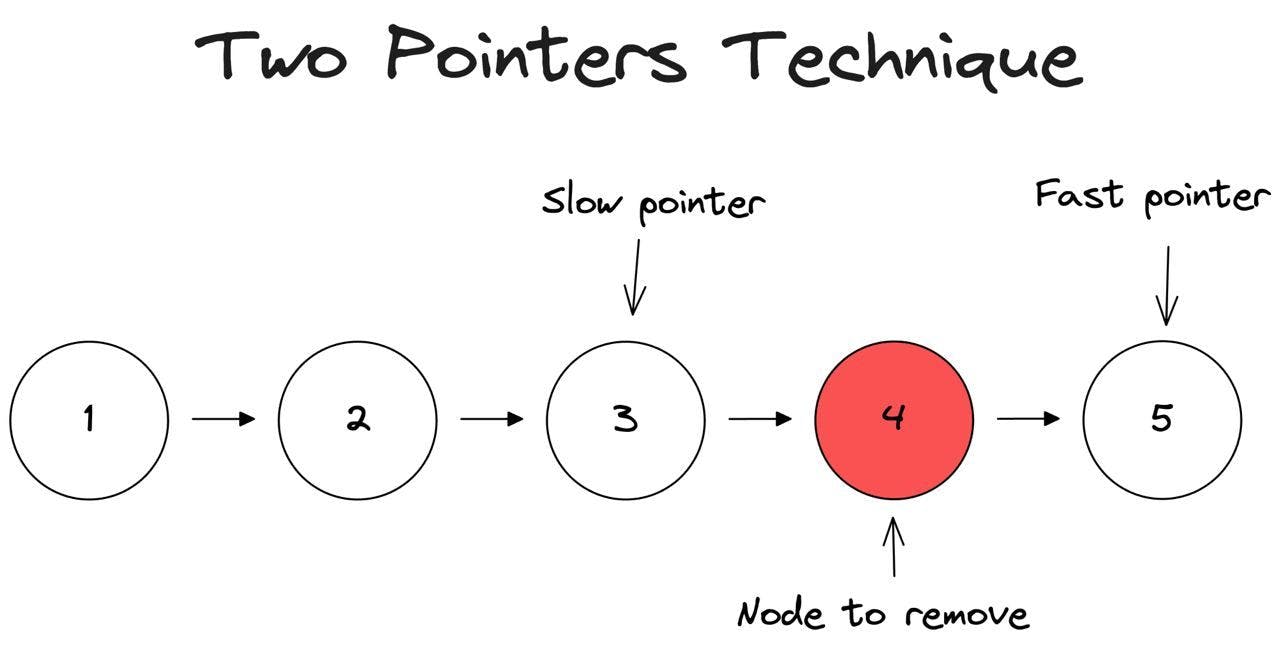
Let's look at an example: List → [1,2,3,4,5] , n=2.


The second scenario is removing the first node, which is a special case as we don't have the previous node. The solution is straightforward, we just need to return the second node as the new head.


Let's evaluate the complexity of this approach. We perform two full traversals of the list, so the time complexity is O(2 * N), and as we only store the size of the list, the space complexity is O(1).
Code:
public ListNode removeNthFromEnd(ListNode head, int n) {
int size = 0;
ListNode tmp = head;
while (tmp != null) {
size++;
tmp = tmp.next;
}
int prevIndex = size - n;
if (prevIndex == 0) return head.next;
tmp = head;
while (prevIndex != 1) {
tmp = tmp.next;
prevIndex--;
}
tmp.next = tmp.next.next;
return head;
}
How to optimize this solution?
By closely examining the conditions, we can see that the number of node to be removed is specified by a value such that 1 <= n <= sz, where sz is the size of the list. The solution involves using two pointers. We create a fast pointer that points to the Nth node and a slow pointer that points to the head of the list.


Next, we iterate until the fast pointer reaches the end of the list. The slow pointer lags behind the fast pointer by n, so it now points to the node preceding the one we want to delete.


And then, we follow the same steps as before and change the pointer of the previous node to the node after the one that was removed.
Code:
public ListNode removeNthFromEnd(ListNode head, int n) {
int delay = n;
ListNode fast = head;
while(delay > 0) {
delay--;
fast = fast.next;
}
if (fast == null) return head.next; // point
ListNode prev = head;
while (tmp.next != null) {
tmp = tmp.next;
prev = prev.next;
}
prev.next = prev.next.next;
return head;
}
I'd like to emphasize a few important points in this code. We must remember the scenario where the first node must be removed. In this scenario, the fast pointer will be null, and we should return the second node as the new head of the list. As we can see, we have successfully found and removed the node in just one pass through the list.
Complexity:
-
Time complexity:
O(N) -
Space complexity:
O(1)


I hope this article was helpful in clarifying how to tackle this kind of problem. I would appreciate your feedback.
See you soon! ✌

L O A D I N G
. . . comments & more!
. . . comments & more!