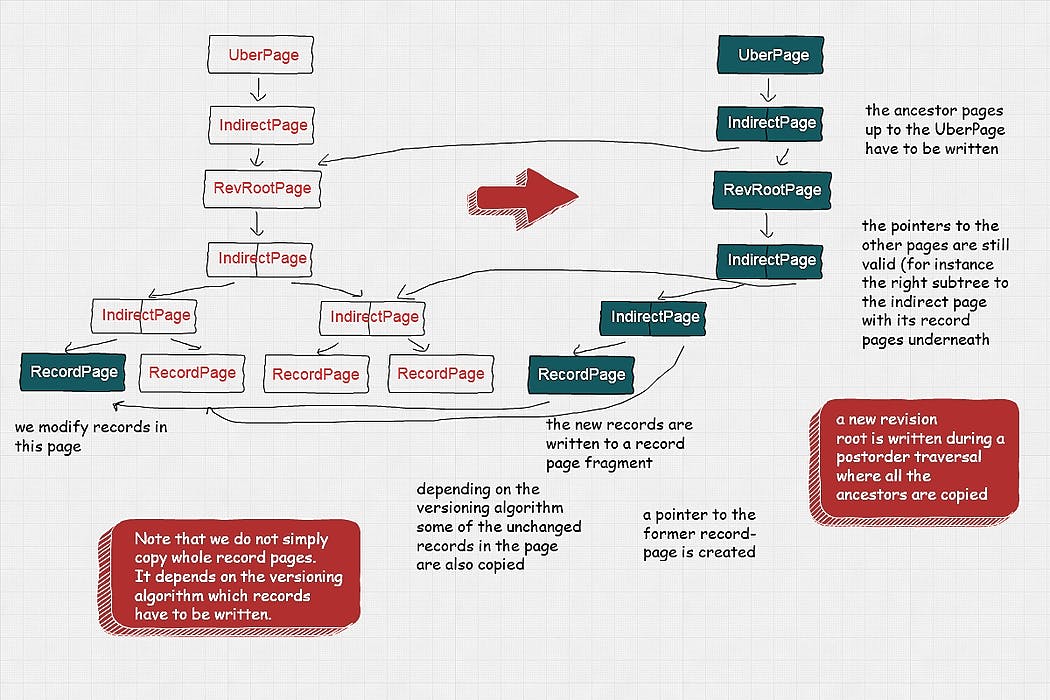
Feel free to contribute on GitHub 💚 Introduction Database Systems usually either are disk-oriented systems or memory-centric targeting a two-level storage hierarchy. The advent of Byte-Addressable Non-Volatile Memory as Intel Optane (3D XPoint), however, is orders of magnitudes faster than traditional spinning disks or even traditional NAND based SSDs. Furthermore, fast random access on a byte-addressable level drops the requirement for excessive clustering. Disk oriented systems Disk-oriented systems use a buffer pool to cache frequently used pages in fast, volatile memory. If the page is not in the buffer pool, the storage layer has to fetch it from slow, non-volatile memory. The assumption usually is that random reads are slow (spinning disks), and writes have to be sequential. Thus, and to provide consistency, they have to introduce a write-ahead-log. First, these systems flush modified pages to the log doing sequential writes. Then, a background thread is checkpointing the changes into the storage files periodically. In-memory centric systems In-memory centric systems, on the contrary, are designed for systems, which have a lot of volatile memory. The system reads the data entirely into memory. They can overcome the need for a heavyweight buffer-pool manager component and concurrency control component. However, they still have to perform recovery management in the case of a power outage. Persistent, durable index-tree (tree of keyed tries) is a temporal document store. It retains the full history of each revision stored in database resources. Data is never modified in-place and only ever appended. Thus, SirixDB stores an ever-increasing state as a result of fine granular modifications. The following figure illustrates this: SirixDB Evolution of state through fine grained modifications. SirixDB indexes a document by using a tree of keyed trie structures. The index is similar to hash-array based tries, known from functional programming languages. It maps the persistence characteristics to durable storage. The following figure shows the page-structure of one revision: The always form a trie-structure. The trie itself might consist of several levels, whereas a level is added on demand if the current level can’t address the stored data anymore. The tries either index revisions or user-defined, AVL tree indexes (underneath a PathPage, a CASPage or a NamePage — depending on the kind of index). IndirectPages The whole tree-structure is a huge persistent tree. A persistent data structure is defined on Wikipedia as follows: In computing, a persistent data structure is a data structure that always preserves the previous version of itself when it is modified. Such data structures are effectively immutable, as their operations do not (visibly) update the structure in-place, but instead, always yield a new updated structure. The term was introduced in Driscoll, Sarnak, Sleator, and Tarjans’ 1986 article.” SirixDB shares unchanged structures between revisions. The following picture shows the page structure of two revisions after a transaction commit of the second revision: SirixDB stores an in-memory transaction intent log, which is only serialized on memory-pressure. On transaction-commit, SirixDB applies this log during a postorder-traversal. The , which is the main entry point into the resource-storage, is written last. UberPage Versioning for Record Pages The database pages in SirixDB, in general, are of variable length and don’t have to be padded to fit into a predefined block-storage size. RecordPages store the application data. Currently, a native layer for XML, as well as JSON documents, exists. Fine-granular, fast random reads due to byte-addressable non-volatile memory allows the versioning of these RecordPages as well. SirixDB implements several versioning strategies best known from backup systems for copy-on-write operations of record-pages. Namely, it either copies the full record-page that is any record in the page ( ) full only the changed records in a record-page regarding the former version ( ) incremental only the changed records in a record-page since a full-page dump ( ) differential Full Dump Versioning Storing the whole database page, although only a few records might have changed, on the one hand, requires way too much storage space. On the other hand, reading this page to fully reconstruct it in-memory instead of having to read scattered deltas is the most efficient way. Incremental Versioning Incremental-versioning is one extreme. Write performance is best, as it stores the optimum (only changed records). On the other hand, reconstructing a page needs intermittent full snapshots of pages. Otherwise, performance deteriorates with each new revision of the page as the number of increments increases with each new version. Differential Versioning Differential-versioning tries to balance reads and writes a bit better, but is still not optimal. A system implementing a differential versioning strategy has to write all changed records since a past full dump of the page. Thus, only ever two revisions of the page-fragment have to be read to reconstruct a record-page. However, write-performance also deteriorates with each new revision of the page. Drawbacks of the three state-of-the-art approaches Write peaks occur both during incremental versioning, due to the requirement of intermittent full dumps of the page. Differential versioning also suffers from a similar problem. Without an intermittent full dump, a system using differential versioning has to duplicate vast amounts of data during each new write. Marc Kramis came up with the idea of a novel sliding snapshot algorithm, which balances read/write-performance to circumvent any write-peaks. Sliding Snapshot Versioning The algorithm, as suggested by its name, makes use of a sliding window. First, the system has to write any changed record during a commit. Second, any record, which is older than a predefined length N of the window and which has not been changed during these N-revisions must be written, too. Only these N-revisions at max have to be read. The system might fetch the page-fragments in parallel or strictly linear. In the latter case, the page fragments are read, starting with the most recent revision. The algorithm stops once the full-page is reconstructed. You can find the best high-level overview of the algorithm in Marc’s Thesis . Evolutionary Tree-Structured Storage: Concepts, Interfaces, and Applications No write-ahead log needed for consistency SirixDB does not need a write-ahead log. During a transaction-commit the is swapped in an atomic operation. Thus, the data is always consistent without the need of a WAL, which is basically a second durable storage and completely unnecessary due to SirixDBs design. UberPage Lightweight buffer management SirixDB bridges the gap between in-memory and disk-oriented database systems. Instead of a heavyweight buffer and concurrency manager, it uses a lightweight buffer manager and stores direct pointers to in-memory data structures, during a fetch of a page from persistent storage. If the buffer manager has to evict a page, it sets the in-memory pointer of the parent page to . null Next, we’ll describe some of the most important design goals, while engineering SirixDB. Design Goals Some of the most important core principles are: Minimize Storage Overhead SirixDB shares unchanged data pages as well as records between revisions, depending on a chosen versioning algorithm during the initial bootstrapping of a resources. SirixDB aims to balance read and writer performance in its default configuration. It uses a huge persistent (in the functional programming language sense), durable index structure for the main document storage as well as versioned secondary indexes Concurrent SirixDB contains very few locks and aims to be as suitable for multithreaded systems as possible Asynchronous Operations can happen independently; each transaction is bound to a specific revision and only one read/write-transaction on a resource is permitted concurrently to N read-only-transactions Versioning/Revision history SirixDB stores a revision history of every resource in the database without imposing extra overhead. It uses a huge persistent, durable page-tree for indexing revisions and data Data integrity SirixDB, like ZFS, stores full checksums of the pages in the parent pages. That means that almost all data corruption can be detected upon reading in the future, we aim to partition and replicate databases in the future Copy-on-write semantics Similarly to the file systems Btrfs and ZFS, SirixDB uses CoW semantics, meaning that SirixDB never overwrites data. Instead, database-page fragments are copied/written to a new location Per revision and per page versioning SirixDB does not only version on a per revision, but also on a per page-base. Thus, whenever we change a potentially small fraction of records in a data-page, it does not have to copy the whole page and write it to a new location on a disk or flash drive. Instead, we can specify one of several versioning strategies known from backup systems or a novel sliding snapshot algorithm during the creation of a database resource. The versioning-type we specify is used by SirixDB to version data-pages Guaranteed atomicity and consistency (without a WAL) The system will never enter an inconsistent state (unless there is hardware failure), meaning that unexpected power-off won’t ever damage the system. This is accomplished without the overhead of a write-ahead-log (WAL) Log-structured and making the most out of byte-addressable NVM friendly SirixDB batches writes and syncs everything sequentially to persistent storage during commits. It never overwrites committed data and only clusters revisions. Database page fragments are of variable size and may be scattered. Thus, SirixDB benefits from fast random access and byte-addressable NVM devicesConclusion The advent of fast non-volatile, byte-addressable memory renders most of the assumptions of today’s database systems invalid. Random reads (and even writes) are fast, thus clustering index structures densely on non-volatile storage is not required anymore. Furthermore, byte-addressable storage upends the key design for block storage devices. Fixed-size blocks are not needed anymore. Instead, reads and writes can be done on a much more fine-granular level. I/O can mostly be done in parallel without a slow head moving around as it’s the case for spinning disks. As writes are slower than reads on NVM and to save storage space for its evolutionary store, are versioned. NVM eliminates the need to store all unchanged records of a page, even if a user only modifies a small number of records or even a single record. Thus, are stored in fragments and scattered on persistent storage. Their size is variable, and they might be scattered on persistent storage. RecordPages RecordPages The storage device underlying SirixDB should support fine granular byte-addressability or small block-sizes and fast random reads with possibly slower writes. Pages are never modified in-place. Thus “traditional” SSDs are a good fit as well. SirixDB batches writes and syncs these to persistent storage during a commit. It doesn’t need a WAL due to the atomic swapping of an , which is the main entry point into the storage of a resource. A resource is the equivalent to a table in relational database systems (currently either XML or JSON, but graphs or tables might be added in a future release). UberPage Help If you like the ideas presented in this article visit the and the . Give it a try and spread the word :-) Website Github Page My highest goal is to stabilize the storage engine, add some stuff needed for the front-end (for instance a ) as well as some JSON layer transactional primitives to copy subtrees into another resource. JSON diff-format I’m also working on a web together with another enthusiastic software engineer . We currently use , (some JavaScript) and I probably want to use in the future. However, I’m no front-end engineer and I’m just learning, Nuxt.js (Vue.js), TypeScript and struggle a lot of times. front-end Moshe Uminer Nuxt.js TypeScript D3.js Any help would be awesome. I’m envisioning a front-end with which we’re able to analyze the differences between revisions, for interacting with the storage and for executing time-travel queries to analyze for instance products or do audits. I have plenty of ideas to move forward, as for instance storing the log in Apache Kafka for horizontal scaling / sharding, adding cost-based query optimizations, building special non-blocking HTTP-Clients, adding Web-Sockets, a proper Kotlin DSL… Contributions are more than welcome 👩💻👨💻 Have fun and happy holidays Johannes