














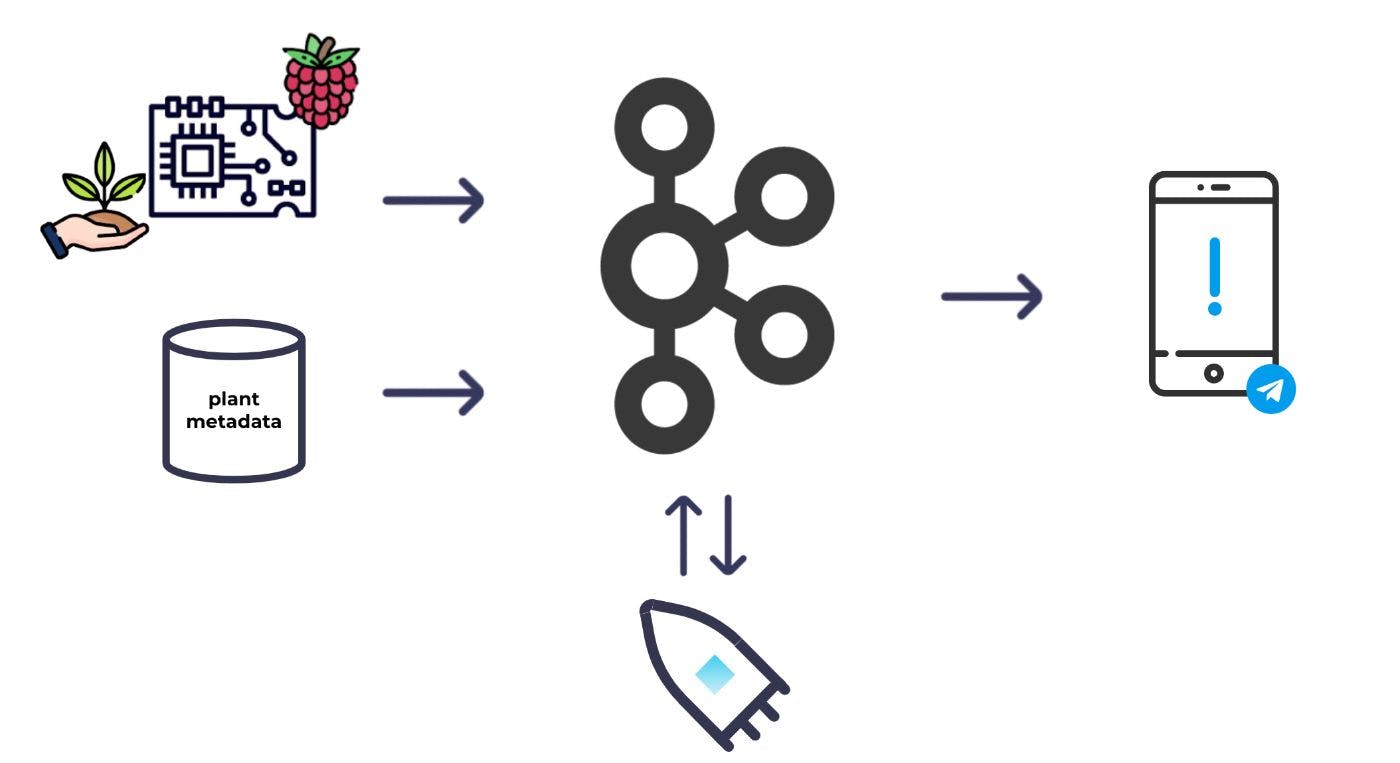

Come along to explore Apache Kafka and see how to get the most out of your event-driven pipelines!


Come along to explore Apache Kafka and see how to get the most out of your event-driven pipelines!
About Author

Come along to explore Apache Kafka and see how to get the most out of your event-driven pipelines!
Comments

















