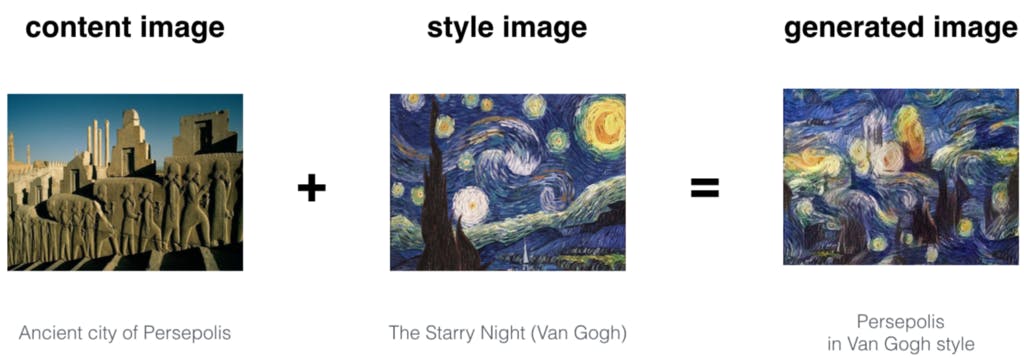
Deep Learning made it possible to capture the content of one image and combine it with the style of another image. This technique is called Neural Style Transfer. But, how Neural Style Transfer works? In this blog post, we are going to look into the underlying mechanism of Neural Style Transfer (NST). High-Level Intuition As we can see, the generated image is having the content of the Content image and style of the style image. It can be seen that the above result cannot be obtained simply by overlapping the images. Now, the million-dollar question remains, how we make sure that the generated image has the content of content image and style of style image? How we capture the content and style of respective images?In order to answer the above questions, let’s look at what Convolutional Neural Networks(CNN) are actually learning. What Convolutional Neural Network Captures ? Look at the following image. Different Layers of Convolutional Neural Network Now, at Layer 1 using 32 filters the network may capture simple patterns, say a straight line or a horizontal line which may not make sense to us but is of immense importance to the network, and slowly as we move down to Layer 2 which has 64 filters, the network starts to capture more and more complex features it might be a face of a dog or wheel of a car. This capturing of different simple and complex features is called feature representation.Important thing to not here is that CNNs does not know what the image is, but they learn to encode what a particular image represents. This encoding nature of Convolutional Neural Networks can help us in Neural Style Transfer. Let’s dive a bit more deeper. How Convolutional Neural Networks are used to capture Content and Style of images? VGG19 network is used for Neural Style transfer. VGG-19 is a convolutional neural network that is trained on more than a million images from the ImageNet database. The network is 19 layers deep and trained on millions of images. Because of which it is able to detect high-level features in an image.Now, this ‘encoding nature’ of CNN’s is the key in Neural Style Transfer. Firstly, we initialize a noisy image, which is going to be our output image(G). We then calculate how similar is this image to the content and style image at a particular layer in the network(VGG network). Since we want that our output image(G) should have the content of the content image(C) and style of style image(S) we calculate the loss of generated image(G) w.r.t to the respective content(C) and style(S) image.Having the above intuition, let’s define our Content Loss and Style loss to randomly generated noisy image. Working of NST model Content Loss Calculating content loss means how similar is the randomly generated noisy image(G) to the content image(C).In order to calculate content loss : Assume that we choose a hidden layer (L) in a pre-trained network(VGG network) to compute the loss.Therefore, let P and F be the original image and the image that is generated.And, F[l] and P[l] be feature representation of the respective images in layer L.Now,the content loss is defined as follows: Content Cost Function This concludes the Content loss function. Style Loss Before calculating style loss, let’s see what is the meaning of “ ” or how we capture style of an image. style of a image How we capture style of an image ? Different channels or Feature maps in layer l This image shows different channels or feature maps or filters at a particular chosen layer l.Now, in order to capture the style of an image we would calculate how “correlated” these filters are to each other meaning how similar are these feature maps. But what is meant by correlation ? Let’s understand it with the help of an example: Let the first two channel in the above image be Red and Yellow.Suppose, the red channel captures some simple feature (say, vertical lines) and if these two channels were correlated then whenever in the image there is a vertical lines that is detected by Red channel then there will be a Yellow-ish effect of the second channel. Now,let’s look at how to calculate these correlations (mathematically). In-order to calculate a correlation between different filters or channels we calculate the dot-product between the vectors of the activations of the two filters.The matrix thus obtained is called . Gram Matrix But how do we know whether they are correlated or not ? If the dot-product across the activation of two filters is large then two channels are said to be correlated and if it is small then the images are un-correlated. Putting it mathematically : Gram Matrix of Style Image(S): Here k and k’ represents different filters or channels of the layer L. Let’s call this Gkk’[l][S]. Gram Matrix for style Image Gram Matrix for Generated Image(G): Here k and k’ represents different filters or channels of the layer L.Let’s call this Gkk’[l][G]. Gram Matrix for generated Image Now,we are in the position to define Style loss: Cost function between Style and Generated Image is the square of difference between the Gram Matrix of the style Image with the Gram Matrix of generated Image. Style cost Function Now,Let’s define the total loss for Neural Style Transfer. Total Loss Function : The total loss function is the sum of the cost of the content and the style image.Mathematically,it can be expressed as : Total Loss Function for Neural Style Transfer You may have noticed Alpha and beta in the above equation.They are used for weighing Content and Style cost respectively.In general,they define the weightage of each cost in the Generated output image. Once the loss is calculated,then this loss can be minimized using which in turn will optimize our into a . backpropagation randomly generated image meaningful piece of art This sums up the working of Neural Style Transfer. Implementation of Neural Style Transfer using tensorflow : Implementation is on my github account : . https://github.com/ayu34/Neural-Style-Transfer Conculsion In this blog, we went deep to see how Neural Style Transfer works.We also went through the mathematics behind NST. I would love to have a conversation in the comment section .Hit “Clap” if this contributes to your understanding of Neural Style Transfer I would love to connect with you on #i . nstagram