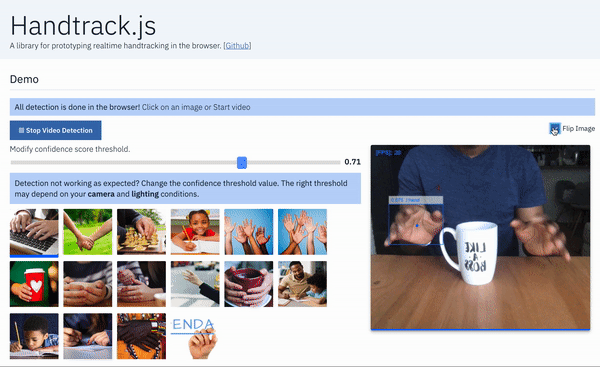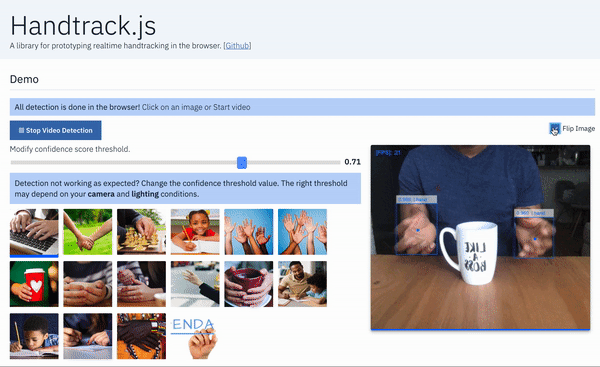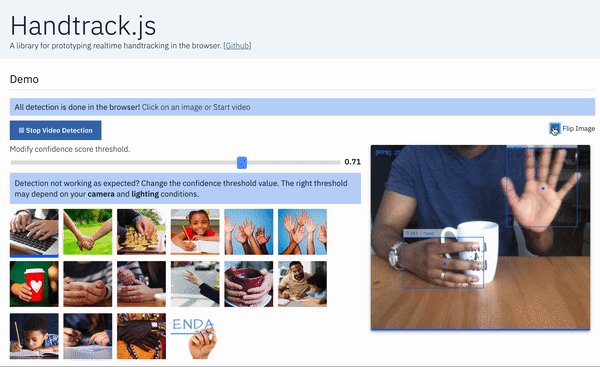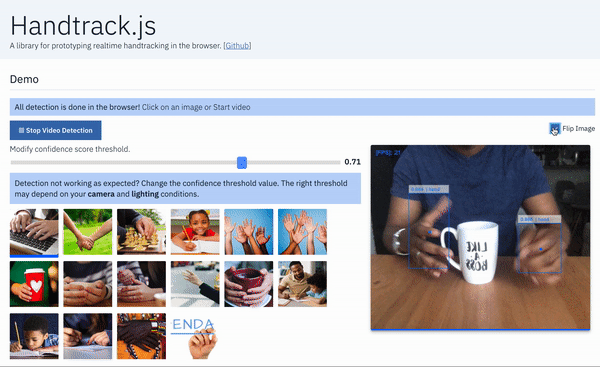
Handtrack.js library allows you track a user’s hand (bounding box) from an image in any orientation, in 3 lines of code. Here’s an example interface built using Handtrack.js to track hands from webcam feed. Try the demo here. A while ago, I was really blown away by results from an experiment using object detection api to in an image. I made the , and since then it has been used to prototype some rather interesting usecases ( , extensions to , , etc). However, while many individuals wanted to experiment with the trained model, a large number still had setting up Tensorflow (installation, TF version issues, exporting graphs, etc). Luckily, Tensorflow.js addresses several of these installations/distribution issues, as it is optimized to run in the standardized environment of browsers. To this end, I created Handtrack.js as a library to allow developers prototype hand/gesture interactions powered by a trained hand detection model. TensorFlow track hands trained model and source code available a tool to help kids spell predict sign language hand ping pong issues quickly Runtime: . On a Macbook Pro 2018, 2.2 Ghz, Chrome browser. on a Macbook Pro 2014 2.2GHz. 22 FPS 13 FPS The goal of the library is to abstract away steps associated with loading the model files, provide helpful functions and allow a user detect hands in an image without any ML experience. You do not need to train a model ( ). You do not need to export any frozen graphs or saved models. You can just get started by including handtrack.js in your web application (details below) and calling the library methods. you can if you want Interactive , and the source . Love tinkering in Codepen? Here’s a you can modify. demo built using Handtrack.js here code on GitHub is here handtrack.js example pen _A library for prototyping realtime hand detection (bounding box), directly in the browser. - victordibia/handtrack.js_github.com victordibia/handtrack.js How Do I Use It in a Web App? You can use simply by including the library URL in a script tag or by importing it from using build tools. handtrack.js npm Using Script Tag The Handtrack.js minified js file is currently hosted using , a free open source cdn that lets you include any npm package in your web application. jsdelivr <script src="https://cdn.jsdelivr.net/npm/handtrackjs/dist/handtrack.min.js"> </script> Once the above script tag has been added to your html page, you can reference handtrack.js using the variable as follows. handTrack const img = document.getElementById('img');handTrack.load().then(model => {model.detect(img).then(predictions => {console.log('Predictions: ', predictions) // bbox predictions});}); The snippet above prints out bounding box predictions for an image passed in via the img tag. By submitting frames from a video or camera feed, you can then “ ” hands in each frame (you will need to keep state of each hand as frames progress). track Demo interface using handtrack.js to track hands in an image. You can use the `renderPredictions()` method to draw detected bounding boxes and source image in a canvas object. Using NPM You can install as an npm package using the following handtrack.js npm install --save handtrackjs An example of how you can import and use it in a React app is given below. import * as handTrack from 'handtrackjs'; const img = document.getElementById('img'); // Load the model.handTrack.load().then(model => {// detect objects in the image.console.log("model loaded")model.detect(img).then(predictions => {console.log('Predictions: ', predictions);});}); You can vary the confidence threshold (predictions below this value are discarded). Note: The model tends to work best with well lighted image conditions. The reader is encouraged to experiment with confidence threshold to accommodate various lighting conditions. E.g. a low lit scene will work better with a lower confidence threshold. When Should I Use Handtrack.js If you are interested in prototyping gesture based (body as input) interactive experiences, Handtrack.js can be useful. The user does not need to attach any additional sensors or hardware but can immediately take advantage of engagement benefits that result from gesture based/body-as-input interactions. A simple body-as-input interaction prototyped using Handtrack.js where the user paints on a canvas using the tracked location of their hand. In this interaction the maxNumber of detections modelParameter value is set to 1 to ensure only one hand is tracked. Some (not all) relevant scenarios are listed below: When mouse motion can be mapped to hand motion for control purposes. When an overlap of hand and other objects can represent meaningful interaction signals (e.g a touch or selection event for an object). Scenarios where the human hand motion can be a proxy for activity recognition (e.g. automatically tracking movement activity from a video or images of individuals playing chess, or tracking a persons golf swing). Or simply counting how many humans are present in an image or video frame. Interactive art installations. Could be a fun set of controls for interactive art installations. Teaching others about ML/AI. The handtrack.js libary provides a valuable interface to demonstrate how changes in the model parameters (confidence threshold, IoU threshold, image size etc) can affect detection results. You want an accessible demonstration that anyone can easily run or tryout with minimal setup. Body as input in the browser. Results from Handtrack.js (applied to webcam feed) controls of a pong game. . Modify it . Try it here here on Codepen Body as input on a large display. Results from Handtrack.js (applied to webcam feed) can be mapped to the controls of a game. Handtrack.js API Several methods are provided. The two main methods including the which loads a hand detection model and method for getting predictions. load() detect() accepts optional model parameters that allow you control the performance of the model. This method loads a pretrained hand detection model in the web model format (also hosted via jsdelivr). load() accepts an input source parameter (a html img, video or canvas object) and returns bounding box predictions on the location of hands in the image. detect() const modelParams = {flipHorizontal: true, // flip e.g for videoimageScaleFactor: 0.7, // reduce input image size .maxNumBoxes: 20, // maximum number of boxes to detectiouThreshold: 0.5, // ioU threshold for non-max suppressionscoreThreshold: 0.79, // confidence threshold for predictions.} const img = document.getElementById('img'); handTrack. (modelParams).then(model => {model. (img).then(predictions => {console.log('Predictions: ', predictions);});}); load detect prediction results are of the form [{bbox: [x, y, width, height],class: "hand",score: 0.8380282521247864}, {bbox: [x, y, width, height],class: "hand",score: 0.74644153267145157}] Other helper methods are also provided : get FPS calculated as number of detections per second. model.getFPS() : draw bounding box (and the input mediasource image) on the specified canvas. model.renderPredictions(predictions, canvas, context, mediasource) : returns model parameters. model.getModelParameters() : updates model parameters. model.setModelParameters(modelParams) : delete model instance dispose() : start camera video stream on given video element. Returns a promise that can be used to validate if user provided video permission. startVideo(video) : stop video stream. stopVideo(video) Library Size and Model Size library size — 810kb. Mainly because it is bundled with the tensorflow.js library (theres some open issues with recent versions that break the library.) Models — 18.5mb. This is what causes the initial wait when the page is loaded. TF.js webmodels are typically sharded into multiple files (in this case four 4.2mb files and one 1.7 mb file.) How it Works Underneath, Handtrack.js uses the — a flexible and intuitive APIs for building and training models from scratch in the browser. It provides a low-level JavaScript linear algebra library and a high-level layers API. Tensorflow.js library Steps in creating a Tensorflow.js -based JavaScript Library. Data Assembly The data used in this project is primarily from the . This consists of 4800 images of the human hand with bounding box annotations in various settings (indoor, outdoor), captured using a Google glass device. Egohands dataset Model Training A model is trained to detect hands using the . For this project, a (SSD) was used with the . Results from the trained model were then exported as a . Additional details on how the model was trained can be and on the Tensorflow Object Detection API github repo. Tensorflow Object Detection API Single Shot MultiBox Detector MobileNetV2 Architecture savedmodel found here Model Conversion Tensorflow.js provides a model conversion tool that allows you convert a trained in Tensorflow python to the Tensorflow.js format that can be loaded in the browser. This process is mainly around mapping in Tensorflow python to their . It makes sense to understand what is being exported. Finally, I followed the suggestion by [2] in removing the post processing part of the object detection model graph during conversion. This optimization effectively doubled the runtime for the detection/prediction operation in the browser. savedmodel webmodel operations equivalent implementation in Tensorflow.js to inspect the saved model graph authors of the Tensorflow coco-ssd example Library Wrapper and Hosting The library was modeled after the tensorflowjs coco-ssd example (but not written in typescript). It consists of a main class with methods to load the model, detect hands in an image, and a set of other e.g. startVideo, stopVideo, getFPS(), renderPredictions(), getModelParameters(), setModelParameters()etc. A full description of . helpful functions methods are on Github The source file is then bundled using , and (with the webmodel files) . This is particularly valuable as jsdelivr automatically provides a cdn for npm packages. (It might be the case that hosting the file on other CDNs might be . At the moment handtrackjs is bundled with tensorflowjs (v0.13.5) mainly because as at the time of writing this library, there were version issues where tfjs (v0.15) had datatype errors loading . As new versions fix this issue, it will be updated. rollup.js published on npm faster and the reader is encouraged to try out other methods) image/video tags as tensors Limitations : What this means is that care must be taken to ensure prediction operations do . Each prediction can take between 50 and 150ms which becomes noticeable to a user. For example when integrating Handtrack.js in an application where the entire screen is rendered (e.g. in a game) many times per second, I found it useful to reduce the number of predictions requested per second. In this scenario, , an emergent standard which allow running scripts in a background thread will be useful in preventing UI blocks. Browsers are single threaded not block the UI thread Webworkers is a simple means for web content to run scripts in background threads. The worker thread can perform tasks without interfering with the user interface. In addition, they can perform I/O using (although the and attributes are always null). Once created, a worker can send messages to the JavaScript code that created it by posting messages to an event handler specified by that code (and vice versa).This article provides a detailed introduction to using web workers. Web Workers [XMLHttpRequest](https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest) responseXML channel : If interested in identifying hands across frames, you will need to write additional code to infer the id’s of detected hands as they enter, move and leave successive frames. Hint: keeping state on location of each prediction (and euclidean distance) . Hands are tracked on a frame by frame basis across each frame can help : There will be the occasional incorrect prediction (sometimes a face is detected as a hand). I found that each camera and lighting condition needed different settings for the model parameters (especially confidence thresholds) to get good detection. More importantly, this can be improved with additional data. Incorrect predictions I really look forward to how others who use or extend this project solve some of these limitations. Whats Next? Handtrack.js represents really with respect to the overall potential in enabling new forms of human computer interaction with AI. In the browser. Already, there have been excellent ideas such as , and in the browser. early steps posenet for human pose detection handsfree.js for facial expression detection Above all, the reader is invited to . Imagine interesting use cases where knowing the location of a users hand can make for more engaging interactions. imagine In the meantime, I will be spending more time on the following Better handmodel: Creating a robust benchmark to evaluate the underlying hand model. Collecting additional data that improves accuracy and robustness metrics. Additional Vocabulary: As I worked through building the , one thing that becomes apparent is the limited vocabulary of this interaction method. There is clearly a need to support atleast one more state. Perhaps a fist and an open hand. This will mean re-labelling the dataset (or some semi supervised approaches). samples Additional model quantization: Right now, we are using the fastest model wrt architecture size and accuracy — MobilenetV2, SSD. Are there optimizations that make things even faster? Any ideas or contributions here are welcome. can If you would like to discuss this in more detail, feel free to reach out on , or Many thanks to who helped with proof reading this article. Twitter Github Linkedin. Kesa Oluwafunmilola References [1] Sandler, Mark, et al. “Mobilenetv2: Inverted residuals and linear bottlenecks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018. https://arxiv.org/abs/1801.04381 [2] Tensorflow.js Coco-ssd example.This library uses code and guidance from the example which provides a library for object detection trained on the MSCOCO dataset. The optimizations suggested in the repo (stripping out a post processing layer) was really helpful (2x speedup). Tensorflow.js coco-ssd