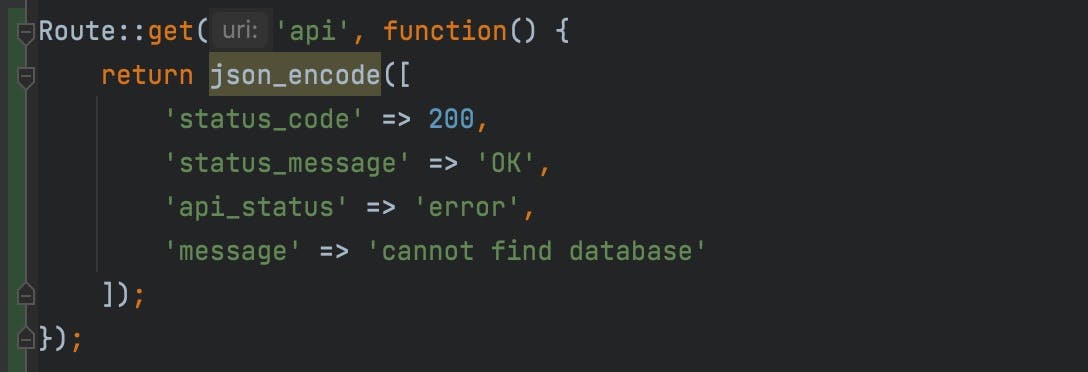
10 Threats to an Open API Ecosystem

Jul 18, 2022

I run Dev Spotlight - we write tech content for tech companies. Email at [email protected].
I run Dev Spotlight - we write tech content for tech companies. Email at [email protected].
I run Dev Spotlight - we write tech content for tech companies. Email at [email protected].
I run Dev Spotlight - we write tech content for tech companies. Email at [email protected].

Jul 18, 2022
Jul 18, 2022