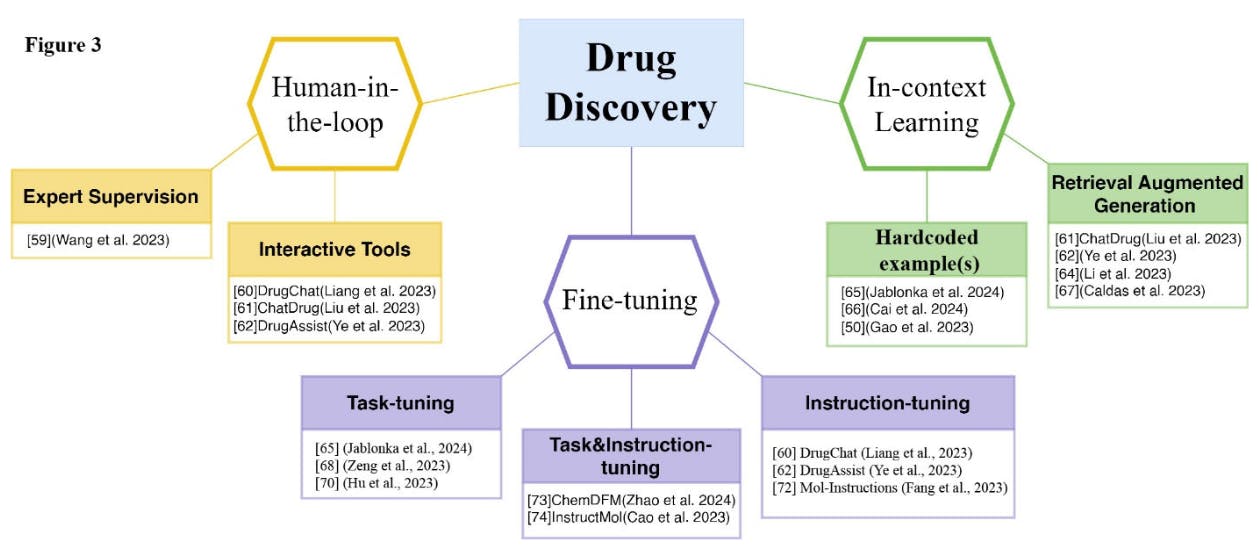
Authors: (1) Jinge Wang, Department of Microbiology, Immunology & Cell Biology, West Virginia University, Morgantown, WV 26506, USA; (2) Zien Cheng, Department of Microbiology, Immunology & Cell Biology, West Virginia University, Morgantown, WV 26506, USA; (3) Qiuming Yao, School of Computing, University of Nebraska-Lincoln, Lincoln, NE 68588, USA; (4) Li Liu, College of Health Solutions, Arizona State University, Phoenix, AZ 85004, USA and Biodesign Institute, Arizona State University, Tempe, AZ 85281, USA; (5) Dong Xu, Department of Electrical Engineer and Computer Science, Christopher S. Bond Life Sciences Center, University of Missouri, Columbia, MO 65211, USA; (6) Gangqing Hu, Department of Microbiology, Immunology & Cell Biology, West Virginia University, Morgantown, WV 26506, USA (Michael.hu@hsc.wvu.edu). Table of Links Abstract and 1. Introduction 2. Omics 3. Genetics 4. Biomedical Text Mining and 4.1. Performance Assessments across typical tasks 4.2. Biological pathway mining 5. Drug Discovery 5.1. Human-in-the-Loop and 5.2. In-context Learning 5.2 Instruction Finetuning 6. Biomedical Image Understanding 7. Bioinformatics Programming 7.1 Application in Applied Bioinformatics 7.2. Biomedical Database Access 7.2. Online tools for Coding with ChatGPT 7.4 Benchmarks for Bioinformatics Coding 8. Chatbots in Bioinformatics Education 9. Discussion and Future Perspectives Author Contributions, Acknowledgements, Conflict of Interest Statement, Ethics Statement, and References 9. DISCUSSION AND FUTURE PERSPECTIVES The year 2023 marked significant progress in leveraging ChatGPT for bioinformatics and biomedical informatics. Early studies affirming its capability in drafting workable code for basic bioinformatics data analysis[10, 12]. The chatbot has also demonstrated competitiveness with SOTA models in other bioinformatics areas, including identifying cell type from single-cell RNA-Seq data[16], performing question-answering tasks in biomedical text mining[26], and generating molecular captions in drug discovery[52]. These achievements underscore ChatGPT’s proficiency in text-generative tasks. Meanwhile, other LLMs are catching up. For example, Google developed Gemini and open-source LLM Gemma, which delivered impressive performance in various tasks. Although their applications in bioinformatics and medical informatics have not been reported, their potentials provide users a viable alternative to ChatGPT. Current chatbots exhibit limitations in performing biomedical tasks that require reasoning and quantitative analysis, such as regression and classification, as evidenced by references[30, 32, 67, 68, 104]. Though not yet widely adapted in bioinformatics[18], OpenAI’s fine-tuning APIs such as for GPT-3.5 and GPT-4 hold great potential for performance improvements when the training dataset is large. Nevertheless, the accuracy of ChatGPT's responses can be significantly improved through a strategic design of its input instructions with prompt engineering. Incorporating examples into prompts and employing CoT reasoning has proven an effective strategy, as evidenced in various bioinformatics applications[30, 35, 62, 67, 68, 101]. While examples in prompts are sometimes hardcoded, they can also be dynamically and strategically sourced from external knowledge bases or knowledge graphs[62, 63, 65, 109]. This approach, known as retrieval-augmented generation (RAG), improves ChatGPT's reliability by sourcing facts from domain-specific knowledge and represents a promising avenue for future bioinformatics with chatbots. In this rapidly evolving domain, ChatGPT has experienced several significant upgrades within its first year alone. We acknowledge that not every upgrade enhances performance across the board[110]. Consequently, prompts that are highly effective with the current version for specific tasks may not maintain the same level of efficacy following future updates. The technique of prompt engineering, which includes strategies like role prompting and in-context learning, offers a way to partially counteract this variability[45]. An innovative approach, rather than manually adjusting the prompts, involves instructing ChatGPT to autonomously optimize prompts to align with its latest model iteration. This strategy has shown promise in tasks such as mining gene relationships[45] but remains largely unexplored in other bioinformatics topics and therefore warrants further exploration to fully leverage ChatGPT's capabilities in the field. Numerous studies repeatedly show that using ChatGPT with human augmentations significantly improve the performance. Iterative human-AI communication plays a pivotal role in this process, where feedback from human operator grounds the chatbot's responses for improved accuracy. This human-in-the-loop methodology is particularly evident in prompt optimization[10] and molecular optimization[60, 63]. For code generation tasks, runtime error message represents commonly used feedback that has been automated into several GPT-based tools[95, 96, 102]. Conversely, the chatbot can also be instructed to provide feedback to human operators. As demonstrated byChen and Stadler [101], ChatGPT can produce textual descriptions for the generated code through an inverse generation process. Comparing these descriptions with the original instructions from the human operator ensures that the chatbot's output aligns closely with the intended task requirements. This iterative exchange of feedback between AI and human operators enhances the overall quality of the bioinformatics tasks being addressed. The assessment of ChatGPT's capabilities across various bioinformatics tasks has illuminated both its strengths and weaknesses. However, the reliability of these evaluations largely hinges on the quality of the benchmarks used and the methodologies applied in these assessments. Currently, many benchmarks are available for biomedical text mining and chemistry-related tasks. The development of benchmarks designed specifically for assessing ChatGPT’s capability in other bioinformatics tasks, including multimodality, is still in its infancy. It's important to recognize that in generative tasks like coding, producing expected results is not the sole criterion for gauging effectiveness and efficiency. Factors such as the readability of the code and the inclusion of code examples also play crucial roles[104]. Nonetheless, conducting such comprehensive evaluations can be resource-intensive, underscoring the need for community efforts to enhance the scope. While alternatives exist for automation, such as transforming tasks into multiple-choice questions or verifying responses against reference texts, for example through lexical overlap or semantic similarity, each method comes with its own set of limitations[7]. Consequently, there is a pressing need to develop new, scalable, and accurate evaluation metrics and benchmark datasets that can accommodate a wide range of bioinformatics tasks, ensuring that assessments are both meaningful and reflective of real-world and cutting-edge applicability. While aiming for comprehensiveness, our review does not encompass areas that, although outside the direct scope of bioinformatics and biomedical informatics, are closely related and significant. These areas include the management of electronic health records[111, 112], emotion analysis through social media[113], and medical consultation[114, 115]. To mitigate transparency and security concerns, fine-tuning open-source language models deployed locally with task-specific instructions presents a practical approach. Our review has spotlighted such advancements for drug discovery. However, we refer our readers to additional reviews for an expansive understanding of similar developments in other bioinformatics topics, as well as the ethical and legal issues involved[7-9, 116, 117]. Looking ahead, we envision a future where both online proprietary models such as ChatGPT and open-source, locally deployable finetuned language models coexist for bioinformatics and biomedical informatics, ensuring users with the most suitable tools to address their specific needs. AUTHOR CONTRIBUTIONS Gangqing Hu: Conceptualization, Writing - original draft, Writing - review & editing, Supervision. Jinge Wang: Writing - original draft, Writing - review & editing. Zien Cheng: Writing - original draft, Writing - review & editing. Qiuming Yao: Writing - review & editing. Li Liu: Writing - review & editing. Dong Xu: Writing - review & editing. All authors have read and approved the final manuscript. ACKNOWLEDGEMENTS This work was partially supported by NIH-NIGMS grants P20 GM103434 and U54 GM-104942, as well as NSF 2125872 (GH). NIH-NLM grant No. R01LM013438 and NIDDK grant No. T32 DK137525 to LL. NLM grant R01LM013392 to DX. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH and NSF. We thank the following scholars for making comments on the manuscript: Tarcisio Mendes de Farias from SIB Swiss Institute of Bioinformatics (Switzerland), Juexiao Zhou and Xin Gao from King Abdullah University of Science and Technology (Kingdom of Saudi Arabia), and Tanja Stadler from ETH Zürich (Switzerland). The writing was polished by ChatGPT. CONFLICT OF INTEREST STATEMENT The authors declared no conflict of interest or financial conflicts to disclose. ETHICS STATEMENT There was no sample from human subjects or animals collected for this work. REFERENCES Wang, H., et al., Scientific discovery in the age of artificial intelligence. Nature, 2023. 620(7972): p. 47-60. Xu, Y., et al., Artificial intelligence: A powerful paradigm for scientific research. Innovation (Camb), 2021. 2(4): p. 100179. Van Noorden, R. and J.M. Perkel, AI and science: what 1,600 researchers think. Nature, 2023.621(7980): p. 672-675. Milano, S., J.A. McGrane, and S. Leonelli, Large language models challenge the future of higher education. Nature Machine Intelligence, 2023. 5(4): p. 333-334. van Dis, E.A.M., et al., ChatGPT: five priorities for research. Nature, 2023. 614(7947): p. 224-226. Lee, P., S. Bubeck, and J. Petro, Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. New England Journal of Medicine, 2023. 388(13): p. 1233-1239. Tian, S., et al., Opportunities and challenges for ChatGPT and large language models in biomedicine and health. Brief Bioinform, 2023. 25(1). Liu, J., et al. Large language models in bioinformatics: applications and perspectives. 2024. arXiv:2401.04155 DOI: 10.48550/arXiv.2401.04155. Xu, D., et al. Large Language Models for Generative Information Extraction: A Survey. 2023. arXiv:2312.17617 DOI: 10.48550/arXiv.2312.17617. Shue, E., et al., Empowering Beginners in Bioinformatics with ChatGPT. Quantitative Biology, 11(2): p. 105-108. Zhou, J., et al., Automated Bioinformatics Analysis via AutoBA. bioRxiv, 2023. Piccolo, S.R., et al., Evaluating a large language model's ability to solve programming exercises from an introductory bioinformatics course. PLoS Comput Biol, 2023. 19(9): p. e1011511. Hu, G., L. Liu, and D. Xu, On the Responsible Use of Chatbots in Bioinformatics. Genomics, Proteomics, and Bioinformatics, 2024. Murdoch, B., Privacy and artificial intelligence: challenges for protecting health information in a new era. BMC Med Ethics, 2021. 22(1): p. 122. Karim, M.R., et al., Explainable AI for Bioinformatics: Methods, Tools and Applications. Brief Bioinform, 2023. 24(5). Hou, W. and Z. Ji, Assessing GPT-4 for cell type annotation in single-cell RNA-seq analysis.bioRxiv, 2023. Zhu, H., et al., MED: a new non-supervised gene prediction algorithm for bacterial and archaeal genomes. BMC Bioinformatics, 2007. 8: p. 97. Yin, H., et al. An Evaluation of Large Language Models in Bioinformatics Research. 2024. arXiv:2402.13714 DOI: 10.48550/arXiv.2402.13714. Hou, W. and Z. Ji, GeneTuring tests GPT models in genomics. bioRxiv, 2023. Jin, Q., Y. Yang, Q. Chen, and Z. Lu, GeneGPT: Augmenting large language models with domain tools for improved access to biomedical information. Bioinformatics, 2024. Chen, Q. and C. Deng, Bioinfo-Bench: A Simple Benchmark Framework for LLM Bioinformatics Skills Evaluation. bioRxiv, 2023: p. 2023.10.18.563023. Ahimaz, P., et al., Genetic counselors' utilization of ChatGPT in professional practice: A cross-sectional study. American Journal of Medical Genetics Part A, 2023. Duong, D. and B.D. Solomon, Analysis of large-language model versus human performance for genetics questions. Eur J Hum Genet, 2023. Alkuraya, I.F., Is artificial intelligence getting too much credit in medical genetics? American Journal of Medical Genetics Part C-Seminars in Medical Genetics, 2023. 193(3). Emmert-Streib, F., Can ChatGPT understand genetics? European Journal of Human Genetics, Chen, Q., et al., An Extensive Benchmark Study on Biomedical Text Generation and Mining with ChatGPT. Bioinformatics, 2023. Gu, Y., et al. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. 2020. arXiv:2007.15779 DOI: 10.48550/arXiv.2007.15779. Chen, Q., et al. Large language models in biomedical natural language processing: benchmarks, baselines, and recommendations. 2023. arXiv:2305.16326 DOI: 10.48550/arXiv.2305.16326. Ateia, S. and U. Kruschwitz Is ChatGPT a Biomedical Expert? -- Exploring the Zero-Shot Performance of Current GPT Models in Biomedical Tasks. 2023. arXiv:2306.16108 DOI: 10.48550/arXiv.2306.16108. Chen, S., et al., Evaluating the ChatGPT family of models for biomedical reasoning and classification. J Am Med Inform Assoc, 2024. Jahan, I., M.T.R. Laskar, C. Peng, and J.X. Huang, A comprehensive evaluation of large language models on benchmark biomedical text processing tasks. Computers in Biology and Medicine, 2024: p. 108189. Hou, Y., et al., From Answers to Insights: Unveiling the Strengths and Limitations of ChatGPT and Biomedical Knowledge Graphs. Res Sq, 2023. Rizvi, R.F., et al., iDISK: the integrated DIetary Supplements Knowledge base. J Am Med Inform Assoc, 2020. 27(4): p. 539-548. Zhao, Q., et al., BioTreasury: a community-based repository enabling indexing and rating of bioinformatics tools. Sci China Life Sci, 2023. Wu, X., et al., reguloGPT: Harnessing GPT for Knowledge Graph Construction of Molecular Regulatory Pathways. bioRxiv, 2024. Li, Y., et al. ChatPathway: Conversational Large Language Models for Biology Pathway Detection. 2023. Azam, M., et al., A Comprehensive Evaluation of Large Language Models in Mining Gene Interactions and Pathway Knowledge. bioRxiv, 2024: p. 2024.01.21.576542. Rehana, H., et al. Evaluation of GPT and BERT-based models on identifying protein-protein interactions in biomedical text. 2023. arXiv:2303.17728 DOI: 10.48550/arXiv.2303.17728. Tiwari, K., et al., ChatGPT usage in the Reactome curation process. bioRxiv, 2023: p. 2023.11.08.566195. Zhou, B., et al., EVLncRNAs 3.0: an updated comprehensive database for manually curated functional long non-coding RNAs validated by low-throughput experiments. Nucleic Acids Res, 2024. 52(D1): p. D98-D106. Chen, X., et al., Computational screening of biomarkers and potential drugs for arthrofibrosis based on combination of sequencing and large nature language model. Journal of Orthopaedic Translation, 2024. 44: p. 102-113. Fo, K., et al., PlantConnectome: knowledge networks encompassing >100,000 plant article abstracts. bioRxiv, 2023: p. 2023.07.11.548541. Rawte, V., A. Sheth, and A. Das A Survey of Hallucination in Large Foundation Models. 2023. arXiv:2309.05922 DOI: 10.48550/arXiv.2309.05922. Zhang, Y., et al. Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models. 2023. arXiv:2309.01219 DOI:10.48550/arXiv.2309.01219. Chen, Y., et al., Iterative Prompt Refinement for Mining Gene Relationships from ChatGPT. bioRxiv, 2023: p. 2023.12.23.573201. Yao, S., et al., Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv, 2023. Savage, N., Drug discovery companies are customizing ChatGPT: here's how. Nat Biotechnol, 41(5): p. 585-586. Chakraborty, C., M. Bhattacharya, and S.S. Lee, Artificial intelligence enabled ChatGPT and large language models in drug target discovery, drug discovery, and development. Mol Ther Nucleic Acids, 2023. 33: p. 866-868. Zhao, A. and Y. Wu, Future implications of ChatGPT in pharmaceutical industry: drug discovery and development. Front Pharmacol, 2023. 14: p. 1194216. Hu, G. and Z. Xie, The artificial intelligence pharma era after “Chat Generative Pre-trained Transformer”. Medical Review, 2023. 3(3): p. 198-199. Gao, Z., et al., Examining the Potential of ChatGPT on Biomedical Information Retrieval: FactChecking Drug-Disease Associations. Ann Biomed Eng, 2023. Guo, T., et al. What can Large Language Models do in chemistry? A comprehensive benchmark on eight tasks. 2023. arXiv:2305.18365 DOI: 10.48550/arXiv.2305.18365. Juhi, A., et al., The Capability of ChatGPT in Predicting and Explaining Common Drug-Drug Interactions. Cureus, 2023. 15(3): p. e36272. Al-Ashwal, F.Y., et al., Evaluating the Sensitivity, Specificity, and Accuracy of ChatGPT-3.5, ChatGPT-4, Bing AI, and Bard Against Conventional Drug-Drug Interactions Clinical Tools. Drug Healthc Patient Saf, 2023. 15: p. 137-147. Herrero-Zazo, M., I. Segura-Bedmar, P. Martinez, and T. Declerck, The DDI corpus: an annotated corpus with pharmacological substances and drug-drug interactions. J Biomed Inform, 2013. 46(5): p. 914-20. Wang, Y.M., H.W. Shen, and T.J. Chen, Performance of ChatGPT on the pharmacist licensing examination in Taiwan. J Chin Med Assoc, 2023. 86(7): p. 653-658. Kunitsu, Y., The Potential of GPT-4 as a Support Tool for Pharmacists: Analytical Study Using the Japanese National Examination for Pharmacists. Jmir Medical Education, 2023. 9. Zong, H., et al., Performance of ChatGPT on Chinese National Medical Licensing Examinations: A Five-Year Examination Evaluation Study for Physicians, Pharmacists and Nurses. medRxiv, 2023: p. 2023.07.09.23292415. Huang, X., et al., Evaluating the performance of ChatGPT in clinical pharmacy: A comparative study of ChatGPT and clinical pharmacists. Br J Clin Pharmacol, 2024. 90(1): p. 232-238. Wang, R., H. Feng, and G.W. Wei, ChatGPT in Drug Discovery: A Case Study on Anticocaine Addiction Drug Development with Chatbots. J Chem Inf Model, 2023. 63(22): p. 7189-7209. Liang, Y., R. Zhang, L. Zhang, and P. Xie DrugChat: Towards Enabling ChatGPT-Like Capabilities on Drug Molecule Graphs. 2023. arXiv:2309.03907 DOI: 10.48550/arXiv.2309.03907. Liu, S., et al. ChatGPT-powered Conversational Drug Editing Using Retrieval and Domain Feedback. 2023. arXiv:2305.18090 DOI: 10.48550/arXiv.2305.18090. Ye, G., et al. DrugAssist: A Large Language Model for Molecule Optimization. 2023. arXiv:2401.10334 DOI: 10.48550/arXiv.2401.10334. Dong, Q., et al. A Survey on In-context Learning. 2022. arXiv:2301.00234 DOI:10.48550/arXiv.2301.00234. Li, J., et al. Empowering Molecule Discovery for Molecule-Caption Translation with Large Language Models: A ChatGPT Perspective. 2023. arXiv:2306.06615 DOI: 10.48550/arXiv.2306.06615. Jablonka, K.M., P. Schwaller, A. Ortega-Guerrero, and B. Smit, Leveraging large language models for predictive chemistry. Nature Machine Intelligence, 2024. Cai, X., et al., Comprehensive evaluation of molecule property prediction with ChatGPT. Methods, 2024. 222: p. 133-141. Caldas Ramos, M., S.S. Michtavy, M.D. Porosoff, and A.D. White Bayesian Optimization of Catalysts With In-context Learning. 2023. arXiv:2304.05341 DOI: 10.48550/arXiv.2304.05341. Zeng, Z., et al. Interactive Molecular Discovery with Natural Language. 2023. arXiv:2306.11976 DOI: 10.48550/arXiv.2306.11976. Raffel, C., et al., Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research, 2020. 21. Hu, H., et al., A Generative Drug–Drug Interaction Triplets Extraction Framework Based on Large Language Models. Proceedings of the Association for Information Science and Technology, 2023. 60(1): p. 980-982. Wei, J., et al. Finetuned Language Models Are Zero-Shot Learners. 2021. arXiv:2109.01652 DOI: 10.48550/arXiv.2109.01652. Fang, Y., et al. Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models. 2023. arXiv:2306.08018 DOI: 10.48550/arXiv.2306.08018. Zhao, Z., et al. ChemDFM: Dialogue Foundation Model for Chemistry. 2024. arXiv:2401.14818 DOI: 10.48550/arXiv.2401.14818. Cao, H., et al. InstructMol: Multi-Modal Integration for Building a Versatile and Reliable Molecular Assistant in Drug Discovery. 2023. arXiv:2311.16208 DOI: 10.48550/arXiv.2311.16208. Acosta, J.N., G.J. Falcone, P. Rajpurkar, and E.J. Topol, Multimodal biomedical AI. Nature Medicine, 2022. 28(9): p. 1773-1784. Truhn, D., et al., A pilot study on the efficacy of GPT-4 in providing orthopedic treatment recommendations from MRI reports. Scientific Reports, 2023. 13(1). Liu, Z., et al. Holistic Evaluation of GPT-4V for Biomedical Imaging. 2023. arXiv:2312.05256 DOI: 10.48550/arXiv.2312.05256. Wu, C., et al. Can GPT-4V(ision) Serve Medical Applications? Case Studies on GPT-4V for Multimodal Medical Diagnosis. 2023. arXiv:2310.09909 DOI: 10.48550/arXiv.2310.09909. Yan, Z., et al. Multimodal ChatGPT for Medical Applications: an Experimental Study of GPT-4V. 2023. arXiv:2310.19061 DOI: 10.48550/arXiv.2310.19061. Buckley, T., J.A. Diao, A. Rodman, and A.K. Manrai Accuracy of a Vision-Language Model on Challenging Medical Cases. 2023. arXiv:2311.05591 DOI: 10.48550/arXiv.2311.05591. Yang, Z., et al., Performance of Multimodal GPT-4V on USMLE with Image: Potential for Imaging Diagnostic Support with Explanations. medRxiv, 2023: p. 2023.10.26.23297629. Li, Y., et al., A Comprehensive Study of GPT-4V’s Multimodal Capabilities in Medical Imaging. medRxiv, 2023: p. 2023.11.03.23298067. Hou, W. and Z. Ji, GPT-4V exhibits human-like performance in biomedical image classification. bioRxiv, 2024. Wang, J., et al., Scientific Figures Interpreted by ChatGPT: Strengths in Plot Recognition and Limits in Color Perception. npj Precision Oncology, 2024. in press. OpenAI, GPT-4V(ision) System Card. 2023, OpenAI. p. 1-18. Nickerson, R.S., Confirmation Bias: A Ubiquitous Phenomenon in Many Guises. Review of General Psychology, 1998. 2(2): p. 175-220. Jin, Q., et al. Hidden Flaws Behind Expert-Level Accuracy of GPT-4 Vision in Medicine. 2024. arXiv:2401.08396 DOI:10.48550/arXiv.2401.08396. Wang, J., et al. Review of Large Vision Models and Visual Prompt Engineering. 2023. arXiv:2307.00855 DOI: 10.48550/arXiv.2307.00855. Yang, Z., et al., The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision). arXiv, 2023. Li, Z., et al. VRPTEST: Evaluating Visual Referring Prompting in Large Multimodal Models. 2023. arXiv:2312.04087 DOI: 10.48550/arXiv.2312.04087. Li, J., et al., Next-Generation Analytics for Omics Data. Cancer Cell, 2021. 39(1): p. 3-6. Xie, M., et al., RiboChat: a chat-style web interface for analysis and annotation of ribosome profiling data. Brief Bioinform, 2022. 23(2). Merow, C., J.M. Serra-Diaz, B.J. Enquist, and A.M. Wilson, AI chatbots can boost scientific coding. Nature Ecology & Evolution, 2023. Zhou, J., et al., An AI Agent for Fully Automated Multi-omic Analyses. bioRxiv, 2024: p. 2023.09.08.556814. Jansen, J.A., A. Manukyan, N.A. Khoury, and A. Akalin, Leveraging large language models for data analysis automation. bioRxiv, 2023: p. 2023.12.11.571140. Dong, Z., V. Zhong, and Y.Y. Lu, BioMANIA: Simplifying bioinformatics data analysis through conversation. bioRxiv, 2023: p. 2023.10.29.564479. Liu, A., X. Hu, L. Wen, and P.S. Yu A comprehensive evaluation of ChatGPT's zero-shot Text-toSQL capability. 2023. arXiv:2303.13547 DOI: 10.48550/arXiv.2303.13547. Sima, A.-C. and T.M. de Farias. On the Potential of Artificial Intelligence Chatbots for Data Exploration of Federated Bioinformatics Knowledge Graphs. in SeWebMeDa’23: 6th Workshop on Semantic Web Solutions for Large-Scale Biomedical Data Analytics. 2023. Hersonissos, Greece: CEUR-WS.org. Rangel, J.C., T.M. de Farias, A.C. Sima, and N. Kobayashi. SPARQL Generation: an analysis on fine-tuning OpenLLaMA for Question Answering over a Life Science Knowledge Graph. in WAT4HCLS 2024: 15th International Semantic Web Applications and Tools for Health Care and Life Sciences Conference. 2024. Leiden, Netherlands: In press. Chen, C. and T. Stadler GenSpectrum Chat: Data Exploration in Public Health Using Large Language Models. 2023. arXiv:2305.13821 DOI: 10.48550/arXiv.2305.13821. Wang, L., X.J. Ge, L. Liu, and G.Q. Hu, Code Interpreter for Bioinformatics: Are We There Yet? Annals of Biomedical Engineering, 2023. Tang, X., et al., BioCoder: A Benchmark for Bioinformatics Code Generation with Contextual Pragmatic Knowledge. arXiv, 2023. Sarwal, V., et al., BioLLMBench: A Comprehensive Benchmarking of Large Language Models in Bioinformatics. bioRxiv, 2023: p. 2023.12.19.572483. Lubiana, T., et al., Ten quick tips for harnessing the power of ChatGPT in computational biology. PLoS Comput Biol, 2023. 19(8): p. e1011319. Chen, M., et al. Evaluating Large Language Models Trained on Code. 2021. arXiv:2107.03374 DOI: 10.48550/arXiv.2107.03374. Lehtinen, T., L. Haaranen, and J. Leinonen. Automated Questionnaires About Students’ JavaScript Programs: Towards Gauging Novice Programming Processes. in ACE '23: Proceedings of the 25th Australasian Computing Education Conference. 2023. New York, NY, USA: Association for Computing Machiner. Denny, P., et al. Promptly: Using Prompt Problems to Teach Learners How to Effectively Utilize AI Code Generators. 2023. arXiv:2307.16364 DOI: 10.48550/arXiv.2307.16364. Soman, K., et al. Biomedical knowledge graph-enhanced prompt generation for large language models. 2023. arXiv:2311.17330 DOI: 10.48550/arXiv.2311.17330. Chen, L., M. Zaharia, and J. Zou How is ChatGPT's behavior changing over time? 2023. arXiv:2307.09009 DOI: 10.48550/arXiv.2307.09009. Wang, G., et al. ClinicalGPT: Large Language Models Finetuned with Diverse Medical Data and Comprehensive Evaluation. 2023. arXiv:2306.09968 DOI: 10.48550/arXiv.2306.09968. Peng, C., et al. A Study of Generative Large Language Model for Medical Research and Healthcare. 2023. arXiv:2305.13523 DOI: 10.48550/arXiv.2305.13523. Lai, T., et al. Psy-LLM: Scaling up Global Mental Health Psychological Services with AI-based Large Language Models. 2023. arXiv:2307.11991 DOI: 10.48550/arXiv.2307.11991. Liu, J.M., et al. ChatCounselor: A Large Language Models for Mental Health Support. 2023. arXiv:2309.15461 DOI: 10.48550/arXiv.2309.15461. Han, T., et al. MedAlpaca -- An Open-Source Collection of Medical Conversational AI Models and Training Data. 2023. arXiv:2304.08247 DOI: 10.48550/arXiv.2304.08247. Zhang, S., et al., Applications of transformer-based language models in bioinformatics: a survey. Bioinform Adv, 2023. 3(1): p. vbad001. Qiu, J.N., et al., Large AI Models in Health Informatics: Applications, Challenges, and the Future. Ieee Journal of Biomedical and Health Informatics, 2023. 27(12): p. 6074-6087. This paper is available on arxiv under CC BY 4.0 DEED license. Authors: (1) Jinge Wang, Department of Microbiology, Immunology & Cell Biology, West Virginia University, Morgantown, WV 26506, USA; (2) Zien Cheng, Department of Microbiology, Immunology & Cell Biology, West Virginia University, Morgantown, WV 26506, USA; (3) Qiuming Yao, School of Computing, University of Nebraska-Lincoln, Lincoln, NE 68588, USA; (4) Li Liu, College of Health Solutions, Arizona State University, Phoenix, AZ 85004, USA and Biodesign Institute, Arizona State University, Tempe, AZ 85281, USA; (5) Dong Xu, Department of Electrical Engineer and Computer Science, Christopher S. Bond Life Sciences Center, University of Missouri, Columbia, MO 65211, USA; (6) Gangqing Hu, Department of Microbiology, Immunology & Cell Biology, West Virginia University, Morgantown, WV 26506, USA (Michael.hu@hsc.wvu.edu). Authors: Authors: (1) Jinge Wang, Department of Microbiology, Immunology & Cell Biology, West Virginia University, Morgantown, WV 26506, USA; (2) Zien Cheng, Department of Microbiology, Immunology & Cell Biology, West Virginia University, Morgantown, WV 26506, USA; (3) Qiuming Yao, School of Computing, University of Nebraska-Lincoln, Lincoln, NE 68588, USA; (4) Li Liu, College of Health Solutions, Arizona State University, Phoenix, AZ 85004, USA and Biodesign Institute, Arizona State University, Tempe, AZ 85281, USA; (5) Dong Xu, Department of Electrical Engineer and Computer Science, Christopher S. Bond Life Sciences Center, University of Missouri, Columbia, MO 65211, USA; (6) Gangqing Hu, Department of Microbiology, Immunology & Cell Biology, West Virginia University, Morgantown, WV 26506, USA (Michael.hu@hsc.wvu.edu). Table of Links Abstract and 1. Introduction Abstract and 1. Introduction 2. Omics 2. Omics 3. Genetics 3. Genetics 4. Biomedical Text Mining and 4.1. Performance Assessments across typical tasks 4. Biomedical Text Mining and 4.1. Performance Assessments across typical tasks 4.2. Biological pathway mining 4.2. Biological pathway mining 5. Drug Discovery 5. Drug Discovery 5.1. Human-in-the-Loop and 5.2. In-context Learning 5.1. Human-in-the-Loop and 5.2. In-context Learning 5.2 Instruction Finetuning 5.2 Instruction Finetuning 6. Biomedical Image Understanding 6. Biomedical Image Understanding 7. Bioinformatics Programming 7. Bioinformatics Programming 7.1 Application in Applied Bioinformatics 7.1 Application in Applied Bioinformatics 7.2. Biomedical Database Access 7.2. Biomedical Database Access 7.2. Online tools for Coding with ChatGPT 7.2. Online tools for Coding with ChatGPT 7.4 Benchmarks for Bioinformatics Coding 7.4 Benchmarks for Bioinformatics Coding 8. Chatbots in Bioinformatics Education 8. Chatbots in Bioinformatics Education 9. Discussion and Future Perspectives 9. Discussion and Future Perspectives Author Contributions, Acknowledgements, Conflict of Interest Statement, Ethics Statement, and References Author Contributions, Acknowledgements, Conflict of Interest Statement, Ethics Statement, and References 9. DISCUSSION AND FUTURE PERSPECTIVES The year 2023 marked significant progress in leveraging ChatGPT for bioinformatics and biomedical informatics. Early studies affirming its capability in drafting workable code for basic bioinformatics data analysis[10, 12]. The chatbot has also demonstrated competitiveness with SOTA models in other bioinformatics areas, including identifying cell type from single-cell RNA-Seq data[16], performing question-answering tasks in biomedical text mining[26], and generating molecular captions in drug discovery[52]. These achievements underscore ChatGPT’s proficiency in text-generative tasks. Meanwhile, other LLMs are catching up. For example, Google developed Gemini and open-source LLM Gemma, which delivered impressive performance in various tasks. Although their applications in bioinformatics and medical informatics have not been reported, their potentials provide users a viable alternative to ChatGPT. Current chatbots exhibit limitations in performing biomedical tasks that require reasoning and quantitative analysis, such as regression and classification, as evidenced by references[30, 32, 67, 68, 104]. Though not yet widely adapted in bioinformatics[18], OpenAI’s fine-tuning APIs such as for GPT-3.5 and GPT-4 hold great potential for performance improvements when the training dataset is large. Nevertheless, the accuracy of ChatGPT's responses can be significantly improved through a strategic design of its input instructions with prompt engineering. Incorporating examples into prompts and employing CoT reasoning has proven an effective strategy, as evidenced in various bioinformatics applications[30, 35, 62, 67, 68, 101]. While examples in prompts are sometimes hardcoded, they can also be dynamically and strategically sourced from external knowledge bases or knowledge graphs[62, 63, 65, 109]. This approach, known as retrieval-augmented generation (RAG), improves ChatGPT's reliability by sourcing facts from domain-specific knowledge and represents a promising avenue for future bioinformatics with chatbots. In this rapidly evolving domain, ChatGPT has experienced several significant upgrades within its first year alone. We acknowledge that not every upgrade enhances performance across the board[110]. Consequently, prompts that are highly effective with the current version for specific tasks may not maintain the same level of efficacy following future updates. The technique of prompt engineering, which includes strategies like role prompting and in-context learning, offers a way to partially counteract this variability[45]. An innovative approach, rather than manually adjusting the prompts, involves instructing ChatGPT to autonomously optimize prompts to align with its latest model iteration. This strategy has shown promise in tasks such as mining gene relationships[45] but remains largely unexplored in other bioinformatics topics and therefore warrants further exploration to fully leverage ChatGPT's capabilities in the field. Numerous studies repeatedly show that using ChatGPT with human augmentations significantly improve the performance. Iterative human-AI communication plays a pivotal role in this process, where feedback from human operator grounds the chatbot's responses for improved accuracy. This human-in-the-loop methodology is particularly evident in prompt optimization[10] and molecular optimization[60, 63]. For code generation tasks, runtime error message represents commonly used feedback that has been automated into several GPT-based tools[95, 96, 102]. Conversely, the chatbot can also be instructed to provide feedback to human operators. As demonstrated byChen and Stadler [101], ChatGPT can produce textual descriptions for the generated code through an inverse generation process. Comparing these descriptions with the original instructions from the human operator ensures that the chatbot's output aligns closely with the intended task requirements. This iterative exchange of feedback between AI and human operators enhances the overall quality of the bioinformatics tasks being addressed. The assessment of ChatGPT's capabilities across various bioinformatics tasks has illuminated both its strengths and weaknesses. However, the reliability of these evaluations largely hinges on the quality of the benchmarks used and the methodologies applied in these assessments. Currently, many benchmarks are available for biomedical text mining and chemistry-related tasks. The development of benchmarks designed specifically for assessing ChatGPT’s capability in other bioinformatics tasks, including multimodality, is still in its infancy. It's important to recognize that in generative tasks like coding, producing expected results is not the sole criterion for gauging effectiveness and efficiency. Factors such as the readability of the code and the inclusion of code examples also play crucial roles[104]. Nonetheless, conducting such comprehensive evaluations can be resource-intensive, underscoring the need for community efforts to enhance the scope. While alternatives exist for automation, such as transforming tasks into multiple-choice questions or verifying responses against reference texts, for example through lexical overlap or semantic similarity, each method comes with its own set of limitations[7]. Consequently, there is a pressing need to develop new, scalable, and accurate evaluation metrics and benchmark datasets that can accommodate a wide range of bioinformatics tasks, ensuring that assessments are both meaningful and reflective of real-world and cutting-edge applicability. While aiming for comprehensiveness, our review does not encompass areas that, although outside the direct scope of bioinformatics and biomedical informatics, are closely related and significant. These areas include the management of electronic health records[111, 112], emotion analysis through social media[113], and medical consultation[114, 115]. To mitigate transparency and security concerns, fine-tuning open-source language models deployed locally with task-specific instructions presents a practical approach. Our review has spotlighted such advancements for drug discovery. However, we refer our readers to additional reviews for an expansive understanding of similar developments in other bioinformatics topics, as well as the ethical and legal issues involved[7-9, 116, 117]. Looking ahead, we envision a future where both online proprietary models such as ChatGPT and open-source, locally deployable finetuned language models coexist for bioinformatics and biomedical informatics, ensuring users with the most suitable tools to address their specific needs. AUTHOR CONTRIBUTIONS Gangqing Hu: Conceptualization, Writing - original draft, Writing - review & editing, Supervision. Jinge Wang : Writing - original draft, Writing - review & editing. Zien Cheng : Writing - original draft, Writing - review & editing. Qiuming Yao : Writing - review & editing. Li Liu : Writing - review & editing. Dong Xu : Writing - review & editing. All authors have read and approved the final manuscript. Gangqing Hu: Jinge Wang Zien Cheng Qiuming Yao Li Liu Dong Xu ACKNOWLEDGEMENTS This work was partially supported by NIH-NIGMS grants P20 GM103434 and U54 GM-104942, as well as NSF 2125872 (GH). NIH-NLM grant No. R01LM013438 and NIDDK grant No. T32 DK137525 to LL. NLM grant R01LM013392 to DX. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH and NSF. We thank the following scholars for making comments on the manuscript: Tarcisio Mendes de Farias from SIB Swiss Institute of Bioinformatics (Switzerland), Juexiao Zhou and Xin Gao from King Abdullah University of Science and Technology (Kingdom of Saudi Arabia), and Tanja Stadler from ETH Zürich (Switzerland). The writing was polished by ChatGPT. CONFLICT OF INTEREST STATEMENT The authors declared no conflict of interest or financial conflicts to disclose. ETHICS STATEMENT There was no sample from human subjects or animals collected for this work. REFERENCES Wang, H., et al., Scientific discovery in the age of artificial intelligence. Nature, 2023. 620(7972): p. 47-60. Xu, Y., et al., Artificial intelligence: A powerful paradigm for scientific research. Innovation (Camb), 2021. 2(4): p. 100179. Van Noorden, R. and J.M. Perkel, AI and science: what 1,600 researchers think. Nature, 2023.621(7980): p. 672-675. Milano, S., J.A. McGrane, and S. Leonelli, Large language models challenge the future of higher education. Nature Machine Intelligence, 2023. 5(4): p. 333-334. van Dis, E.A.M., et al., ChatGPT: five priorities for research. Nature, 2023. 614(7947): p. 224-226. Lee, P., S. Bubeck, and J. Petro, Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. New England Journal of Medicine, 2023. 388(13): p. 1233-1239. Tian, S., et al., Opportunities and challenges for ChatGPT and large language models in biomedicine and health. Brief Bioinform, 2023. 25(1). Liu, J., et al. Large language models in bioinformatics: applications and perspectives. 2024. arXiv:2401.04155 DOI: 10.48550/arXiv.2401.04155. Xu, D., et al. Large Language Models for Generative Information Extraction: A Survey. 2023. arXiv:2312.17617 DOI: 10.48550/arXiv.2312.17617. Shue, E., et al., Empowering Beginners in Bioinformatics with ChatGPT. Quantitative Biology, 11(2): p. 105-108. Zhou, J., et al., Automated Bioinformatics Analysis via AutoBA. bioRxiv, 2023. Piccolo, S.R., et al., Evaluating a large language model's ability to solve programming exercises from an introductory bioinformatics course. PLoS Comput Biol, 2023. 19(9): p. e1011511. Hu, G., L. Liu, and D. Xu, On the Responsible Use of Chatbots in Bioinformatics. Genomics, Proteomics, and Bioinformatics, 2024. Murdoch, B., Privacy and artificial intelligence: challenges for protecting health information in a new era. BMC Med Ethics, 2021. 22(1): p. 122. Karim, M.R., et al., Explainable AI for Bioinformatics: Methods, Tools and Applications. Brief Bioinform, 2023. 24(5). Hou, W. and Z. Ji, Assessing GPT-4 for cell type annotation in single-cell RNA-seq analysis.bioRxiv, 2023. Zhu, H., et al., MED: a new non-supervised gene prediction algorithm for bacterial and archaeal genomes. BMC Bioinformatics, 2007. 8: p. 97. Yin, H., et al. An Evaluation of Large Language Models in Bioinformatics Research. 2024. arXiv:2402.13714 DOI: 10.48550/arXiv.2402.13714. Hou, W. and Z. Ji, GeneTuring tests GPT models in genomics. bioRxiv, 2023. Jin, Q., Y. Yang, Q. Chen, and Z. Lu, GeneGPT: Augmenting large language models with domain tools for improved access to biomedical information. Bioinformatics, 2024. Chen, Q. and C. Deng, Bioinfo-Bench: A Simple Benchmark Framework for LLM Bioinformatics Skills Evaluation. bioRxiv, 2023: p. 2023.10.18.563023. Ahimaz, P., et al., Genetic counselors' utilization of ChatGPT in professional practice: A cross-sectional study. American Journal of Medical Genetics Part A, 2023. Duong, D. and B.D. Solomon, Analysis of large-language model versus human performance for genetics questions. Eur J Hum Genet, 2023. Alkuraya, I.F., Is artificial intelligence getting too much credit in medical genetics? American Journal of Medical Genetics Part C-Seminars in Medical Genetics, 2023. 193(3). Emmert-Streib, F., Can ChatGPT understand genetics? European Journal of Human Genetics, Chen, Q., et al., An Extensive Benchmark Study on Biomedical Text Generation and Mining with ChatGPT. Bioinformatics, 2023. Gu, Y., et al. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. 2020. arXiv:2007.15779 DOI: 10.48550/arXiv.2007.15779. Chen, Q., et al. Large language models in biomedical natural language processing: benchmarks, baselines, and recommendations. 2023. arXiv:2305.16326 DOI: 10.48550/arXiv.2305.16326. Ateia, S. and U. Kruschwitz Is ChatGPT a Biomedical Expert? -- Exploring the Zero-Shot Performance of Current GPT Models in Biomedical Tasks. 2023. arXiv:2306.16108 DOI: 10.48550/arXiv.2306.16108. Chen, S., et al., Evaluating the ChatGPT family of models for biomedical reasoning and classification. J Am Med Inform Assoc, 2024. Jahan, I., M.T.R. Laskar, C. Peng, and J.X. Huang, A comprehensive evaluation of large language models on benchmark biomedical text processing tasks. Computers in Biology and Medicine, 2024: p. 108189. Hou, Y., et al., From Answers to Insights: Unveiling the Strengths and Limitations of ChatGPT and Biomedical Knowledge Graphs. Res Sq, 2023. Rizvi, R.F., et al., iDISK: the integrated DIetary Supplements Knowledge base. J Am Med Inform Assoc, 2020. 27(4): p. 539-548. Zhao, Q., et al., BioTreasury: a community-based repository enabling indexing and rating of bioinformatics tools. Sci China Life Sci, 2023. Wu, X., et al., reguloGPT: Harnessing GPT for Knowledge Graph Construction of Molecular Regulatory Pathways. bioRxiv, 2024. Li, Y., et al. ChatPathway: Conversational Large Language Models for Biology Pathway Detection. 2023. Azam, M., et al., A Comprehensive Evaluation of Large Language Models in Mining Gene Interactions and Pathway Knowledge. bioRxiv, 2024: p. 2024.01.21.576542. Rehana, H., et al. Evaluation of GPT and BERT-based models on identifying protein-protein interactions in biomedical text. 2023. arXiv:2303.17728 DOI: 10.48550/arXiv.2303.17728. Tiwari, K., et al., ChatGPT usage in the Reactome curation process. bioRxiv, 2023: p. 2023.11.08.566195. Zhou, B., et al., EVLncRNAs 3.0: an updated comprehensive database for manually curated functional long non-coding RNAs validated by low-throughput experiments. Nucleic Acids Res, 2024. 52(D1): p. D98-D106. Chen, X., et al., Computational screening of biomarkers and potential drugs for arthrofibrosis based on combination of sequencing and large nature language model. Journal of Orthopaedic Translation, 2024. 44: p. 102-113. Fo, K., et al., PlantConnectome: knowledge networks encompassing >100,000 plant article abstracts. bioRxiv, 2023: p. 2023.07.11.548541. Rawte, V., A. Sheth, and A. Das A Survey of Hallucination in Large Foundation Models. 2023. arXiv:2309.05922 DOI: 10.48550/arXiv.2309.05922. Zhang, Y., et al. Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models. 2023. arXiv:2309.01219 DOI:10.48550/arXiv.2309.01219. Chen, Y., et al., Iterative Prompt Refinement for Mining Gene Relationships from ChatGPT. bioRxiv, 2023: p. 2023.12.23.573201. Yao, S., et al., Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv, 2023. Savage, N., Drug discovery companies are customizing ChatGPT: here's how. Nat Biotechnol, 41(5): p. 585-586. Chakraborty, C., M. Bhattacharya, and S.S. Lee, Artificial intelligence enabled ChatGPT and large language models in drug target discovery, drug discovery, and development. Mol Ther Nucleic Acids, 2023. 33: p. 866-868. Zhao, A. and Y. Wu, Future implications of ChatGPT in pharmaceutical industry: drug discovery and development. Front Pharmacol, 2023. 14: p. 1194216. Hu, G. and Z. Xie, The artificial intelligence pharma era after “Chat Generative Pre-trained Transformer”. Medical Review, 2023. 3(3): p. 198-199. Gao, Z., et al., Examining the Potential of ChatGPT on Biomedical Information Retrieval: FactChecking Drug-Disease Associations. Ann Biomed Eng, 2023. Guo, T., et al. What can Large Language Models do in chemistry? A comprehensive benchmark on eight tasks. 2023. arXiv:2305.18365 DOI: 10.48550/arXiv.2305.18365. Juhi, A., et al., The Capability of ChatGPT in Predicting and Explaining Common Drug-Drug Interactions. Cureus, 2023. 15(3): p. e36272. Al-Ashwal, F.Y., et al., Evaluating the Sensitivity, Specificity, and Accuracy of ChatGPT-3.5, ChatGPT-4, Bing AI, and Bard Against Conventional Drug-Drug Interactions Clinical Tools. Drug Healthc Patient Saf, 2023. 15: p. 137-147. Herrero-Zazo, M., I. Segura-Bedmar, P. Martinez, and T. Declerck, The DDI corpus: an annotated corpus with pharmacological substances and drug-drug interactions. J Biomed Inform, 2013. 46(5): p. 914-20. Wang, Y.M., H.W. Shen, and T.J. Chen, Performance of ChatGPT on the pharmacist licensing examination in Taiwan. J Chin Med Assoc, 2023. 86(7): p. 653-658. Kunitsu, Y., The Potential of GPT-4 as a Support Tool for Pharmacists: Analytical Study Using the Japanese National Examination for Pharmacists. Jmir Medical Education, 2023. 9. Zong, H., et al., Performance of ChatGPT on Chinese National Medical Licensing Examinations: A Five-Year Examination Evaluation Study for Physicians, Pharmacists and Nurses. medRxiv, 2023: p. 2023.07.09.23292415. Huang, X., et al., Evaluating the performance of ChatGPT in clinical pharmacy: A comparative study of ChatGPT and clinical pharmacists. Br J Clin Pharmacol, 2024. 90(1): p. 232-238. Wang, R., H. Feng, and G.W. Wei, ChatGPT in Drug Discovery: A Case Study on Anticocaine Addiction Drug Development with Chatbots. J Chem Inf Model, 2023. 63(22): p. 7189-7209. Liang, Y., R. Zhang, L. Zhang, and P. Xie DrugChat: Towards Enabling ChatGPT-Like Capabilities on Drug Molecule Graphs. 2023. arXiv:2309.03907 DOI: 10.48550/arXiv.2309.03907. Liu, S., et al. ChatGPT-powered Conversational Drug Editing Using Retrieval and Domain Feedback. 2023. arXiv:2305.18090 DOI: 10.48550/arXiv.2305.18090. Ye, G., et al. DrugAssist: A Large Language Model for Molecule Optimization. 2023. arXiv:2401.10334 DOI: 10.48550/arXiv.2401.10334. Dong, Q., et al. A Survey on In-context Learning. 2022. arXiv:2301.00234 DOI:10.48550/arXiv.2301.00234. Li, J., et al. Empowering Molecule Discovery for Molecule-Caption Translation with Large Language Models: A ChatGPT Perspective. 2023. arXiv:2306.06615 DOI: 10.48550/arXiv.2306.06615. Jablonka, K.M., P. Schwaller, A. Ortega-Guerrero, and B. Smit, Leveraging large language models for predictive chemistry. Nature Machine Intelligence, 2024. Cai, X., et al., Comprehensive evaluation of molecule property prediction with ChatGPT. Methods, 2024. 222: p. 133-141. Caldas Ramos, M., S.S. Michtavy, M.D. Porosoff, and A.D. White Bayesian Optimization of Catalysts With In-context Learning. 2023. arXiv:2304.05341 DOI: 10.48550/arXiv.2304.05341. Zeng, Z., et al. Interactive Molecular Discovery with Natural Language. 2023. arXiv:2306.11976 DOI: 10.48550/arXiv.2306.11976. Raffel, C., et al., Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research, 2020. 21. Hu, H., et al., A Generative Drug–Drug Interaction Triplets Extraction Framework Based on Large Language Models. Proceedings of the Association for Information Science and Technology, 2023. 60(1): p. 980-982. Wei, J., et al. Finetuned Language Models Are Zero-Shot Learners. 2021. arXiv:2109.01652 DOI: 10.48550/arXiv.2109.01652. Fang, Y., et al. Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models. 2023. arXiv:2306.08018 DOI: 10.48550/arXiv.2306.08018. Zhao, Z., et al. ChemDFM: Dialogue Foundation Model for Chemistry. 2024. arXiv:2401.14818 DOI: 10.48550/arXiv.2401.14818. Cao, H., et al. InstructMol: Multi-Modal Integration for Building a Versatile and Reliable Molecular Assistant in Drug Discovery. 2023. arXiv:2311.16208 DOI: 10.48550/arXiv.2311.16208. Acosta, J.N., G.J. Falcone, P. Rajpurkar, and E.J. Topol, Multimodal biomedical AI. Nature Medicine, 2022. 28(9): p. 1773-1784. Truhn, D., et al., A pilot study on the efficacy of GPT-4 in providing orthopedic treatment recommendations from MRI reports. Scientific Reports, 2023. 13(1). Liu, Z., et al. Holistic Evaluation of GPT-4V for Biomedical Imaging. 2023. arXiv:2312.05256 DOI: 10.48550/arXiv.2312.05256. Wu, C., et al. Can GPT-4V(ision) Serve Medical Applications? Case Studies on GPT-4V for Multimodal Medical Diagnosis. 2023. arXiv:2310.09909 DOI: 10.48550/arXiv.2310.09909. Yan, Z., et al. Multimodal ChatGPT for Medical Applications: an Experimental Study of GPT-4V. 2023. arXiv:2310.19061 DOI: 10.48550/arXiv.2310.19061. Buckley, T., J.A. Diao, A. Rodman, and A.K. Manrai Accuracy of a Vision-Language Model on Challenging Medical Cases. 2023. arXiv:2311.05591 DOI: 10.48550/arXiv.2311.05591. Yang, Z., et al., Performance of Multimodal GPT-4V on USMLE with Image: Potential for Imaging Diagnostic Support with Explanations. medRxiv, 2023: p. 2023.10.26.23297629. Li, Y., et al., A Comprehensive Study of GPT-4V’s Multimodal Capabilities in Medical Imaging. medRxiv, 2023: p. 2023.11.03.23298067. Hou, W. and Z. Ji, GPT-4V exhibits human-like performance in biomedical image classification. bioRxiv, 2024. Wang, J., et al., Scientific Figures Interpreted by ChatGPT: Strengths in Plot Recognition and Limits in Color Perception. npj Precision Oncology, 2024. in press. OpenAI, GPT-4V(ision) System Card. 2023, OpenAI. p. 1-18. Nickerson, R.S., Confirmation Bias: A Ubiquitous Phenomenon in Many Guises. Review of General Psychology, 1998. 2(2): p. 175-220. Jin, Q., et al. Hidden Flaws Behind Expert-Level Accuracy of GPT-4 Vision in Medicine. 2024. arXiv:2401.08396 DOI:10.48550/arXiv.2401.08396. Wang, J., et al. Review of Large Vision Models and Visual Prompt Engineering. 2023. arXiv:2307.00855 DOI: 10.48550/arXiv.2307.00855. Yang, Z., et al., The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision). arXiv, 2023. Li, Z., et al. VRPTEST: Evaluating Visual Referring Prompting in Large Multimodal Models. 2023. arXiv:2312.04087 DOI: 10.48550/arXiv.2312.04087. Li, J., et al., Next-Generation Analytics for Omics Data. Cancer Cell, 2021. 39(1): p. 3-6. Xie, M., et al., RiboChat: a chat-style web interface for analysis and annotation of ribosome profiling data. Brief Bioinform, 2022. 23(2). Merow, C., J.M. Serra-Diaz, B.J. Enquist, and A.M. Wilson, AI chatbots can boost scientific coding. Nature Ecology & Evolution, 2023. Zhou, J., et al., An AI Agent for Fully Automated Multi-omic Analyses. bioRxiv, 2024: p. 2023.09.08.556814. Jansen, J.A., A. Manukyan, N.A. Khoury, and A. Akalin, Leveraging large language models for data analysis automation. bioRxiv, 2023: p. 2023.12.11.571140. Dong, Z., V. Zhong, and Y.Y. Lu, BioMANIA: Simplifying bioinformatics data analysis through conversation. bioRxiv, 2023: p. 2023.10.29.564479. Liu, A., X. Hu, L. Wen, and P.S. Yu A comprehensive evaluation of ChatGPT's zero-shot Text-toSQL capability. 2023. arXiv:2303.13547 DOI: 10.48550/arXiv.2303.13547. Sima, A.-C. and T.M. de Farias. On the Potential of Artificial Intelligence Chatbots for Data Exploration of Federated Bioinformatics Knowledge Graphs. in SeWebMeDa’23: 6th Workshop on Semantic Web Solutions for Large-Scale Biomedical Data Analytics. 2023. Hersonissos, Greece: CEUR-WS.org. Rangel, J.C., T.M. de Farias, A.C. Sima, and N. Kobayashi. SPARQL Generation: an analysis on fine-tuning OpenLLaMA for Question Answering over a Life Science Knowledge Graph. in WAT4HCLS 2024: 15th International Semantic Web Applications and Tools for Health Care and Life Sciences Conference. 2024. Leiden, Netherlands: In press. Chen, C. and T. Stadler GenSpectrum Chat: Data Exploration in Public Health Using Large Language Models. 2023. arXiv:2305.13821 DOI: 10.48550/arXiv.2305.13821. Wang, L., X.J. Ge, L. Liu, and G.Q. Hu, Code Interpreter for Bioinformatics: Are We There Yet? Annals of Biomedical Engineering, 2023. Tang, X., et al., BioCoder: A Benchmark for Bioinformatics Code Generation with Contextual Pragmatic Knowledge. arXiv, 2023. Sarwal, V., et al., BioLLMBench: A Comprehensive Benchmarking of Large Language Models in Bioinformatics. bioRxiv, 2023: p. 2023.12.19.572483. Lubiana, T., et al., Ten quick tips for harnessing the power of ChatGPT in computational biology. PLoS Comput Biol, 2023. 19(8): p. e1011319. Chen, M., et al. Evaluating Large Language Models Trained on Code. 2021. arXiv:2107.03374 DOI: 10.48550/arXiv.2107.03374. Lehtinen, T., L. Haaranen, and J. Leinonen. Automated Questionnaires About Students’ JavaScript Programs: Towards Gauging Novice Programming Processes. in ACE '23: Proceedings of the 25th Australasian Computing Education Conference. 2023. New York, NY, USA: Association for Computing Machiner. Denny, P., et al. Promptly: Using Prompt Problems to Teach Learners How to Effectively Utilize AI Code Generators. 2023. arXiv:2307.16364 DOI: 10.48550/arXiv.2307.16364. Soman, K., et al. Biomedical knowledge graph-enhanced prompt generation for large language models. 2023. arXiv:2311.17330 DOI: 10.48550/arXiv.2311.17330. Chen, L., M. Zaharia, and J. Zou How is ChatGPT's behavior changing over time? 2023. arXiv:2307.09009 DOI: 10.48550/arXiv.2307.09009. Wang, G., et al. ClinicalGPT: Large Language Models Finetuned with Diverse Medical Data and Comprehensive Evaluation. 2023. arXiv:2306.09968 DOI: 10.48550/arXiv.2306.09968. Peng, C., et al. A Study of Generative Large Language Model for Medical Research and Healthcare. 2023. arXiv:2305.13523 DOI: 10.48550/arXiv.2305.13523. Lai, T., et al. Psy-LLM: Scaling up Global Mental Health Psychological Services with AI-based Large Language Models. 2023. arXiv:2307.11991 DOI: 10.48550/arXiv.2307.11991. Liu, J.M., et al. ChatCounselor: A Large Language Models for Mental Health Support. 2023. arXiv:2309.15461 DOI: 10.48550/arXiv.2309.15461. Han, T., et al. MedAlpaca -- An Open-Source Collection of Medical Conversational AI Models and Training Data. 2023. arXiv:2304.08247 DOI: 10.48550/arXiv.2304.08247. Zhang, S., et al., Applications of transformer-based language models in bioinformatics: a survey. Bioinform Adv, 2023. 3(1): p. vbad001. Qiu, J.N., et al., Large AI Models in Health Informatics: Applications, Challenges, and the Future. Ieee Journal of Biomedical and Health Informatics, 2023. 27(12): p. 6074-6087. Wang, H., et al., Scientific discovery in the age of artificial intelligence. Nature, 2023. 620(7972): p. 47-60. Wang, H., et al., Scientific discovery in the age of artificial intelligence. Nature, 2023. 620(7972): p. 47-60. Xu, Y., et al., Artificial intelligence: A powerful paradigm for scientific research. Innovation (Camb), 2021. 2(4): p. 100179. Xu, Y., et al., Artificial intelligence: A powerful paradigm for scientific research. Innovation (Camb), 2021. 2(4): p. 100179. Van Noorden, R. and J.M. Perkel, AI and science: what 1,600 researchers think. Nature, 2023.621(7980): p. 672-675. Van Noorden, R. and J.M. Perkel, AI and science: what 1,600 researchers think. Nature, 2023.621(7980): p. 672-675. Milano, S., J.A. McGrane, and S. Leonelli, Large language models challenge the future of higher education. Nature Machine Intelligence, 2023. 5(4): p. 333-334. Milano, S., J.A. McGrane, and S. Leonelli, Large language models challenge the future of higher education. Nature Machine Intelligence, 2023. 5(4): p. 333-334. van Dis, E.A.M., et al., ChatGPT: five priorities for research. Nature, 2023. 614(7947): p. 224-226. van Dis, E.A.M., et al., ChatGPT: five priorities for research. Nature, 2023. 614(7947): p. 224-226. Lee, P., S. Bubeck, and J. Petro, Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. New England Journal of Medicine, 2023. 388(13): p. 1233-1239. Lee, P., S. Bubeck, and J. Petro, Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. New England Journal of Medicine, 2023. 388(13): p. 1233-1239. Tian, S., et al., Opportunities and challenges for ChatGPT and large language models in biomedicine and health. Brief Bioinform, 2023. 25(1). Tian, S., et al., Opportunities and challenges for ChatGPT and large language models in biomedicine and health. Brief Bioinform, 2023. 25(1). Liu, J., et al. Large language models in bioinformatics: applications and perspectives. 2024. arXiv:2401.04155 DOI: 10.48550/arXiv.2401.04155. Liu, J., et al. Large language models in bioinformatics: applications and perspectives. 2024. arXiv:2401.04155 DOI: 10.48550/arXiv.2401.04155. Xu, D., et al. Large Language Models for Generative Information Extraction: A Survey. 2023. arXiv:2312.17617 DOI: 10.48550/arXiv.2312.17617. Xu, D., et al. Large Language Models for Generative Information Extraction: A Survey. 2023. arXiv:2312.17617 DOI: 10.48550/arXiv.2312.17617. Shue, E., et al., Empowering Beginners in Bioinformatics with ChatGPT. Quantitative Biology, 11(2): p. 105-108. Shue, E., et al., Empowering Beginners in Bioinformatics with ChatGPT. Quantitative Biology, 11(2): p. 105-108. Zhou, J., et al., Automated Bioinformatics Analysis via AutoBA. bioRxiv, 2023. Zhou, J., et al., Automated Bioinformatics Analysis via AutoBA. bioRxiv, 2023. Piccolo, S.R., et al., Evaluating a large language model's ability to solve programming exercises from an introductory bioinformatics course. PLoS Comput Biol, 2023. 19(9): p. e1011511. Piccolo, S.R., et al., Evaluating a large language model's ability to solve programming exercises from an introductory bioinformatics course. PLoS Comput Biol, 2023. 19(9): p. e1011511. Hu, G., L. Liu, and D. Xu, On the Responsible Use of Chatbots in Bioinformatics. Genomics, Proteomics, and Bioinformatics, 2024. Hu, G., L. Liu, and D. Xu, On the Responsible Use of Chatbots in Bioinformatics. Genomics, Proteomics, and Bioinformatics, 2024. Murdoch, B., Privacy and artificial intelligence: challenges for protecting health information in a new era. BMC Med Ethics, 2021. 22(1): p. 122. Murdoch, B., Privacy and artificial intelligence: challenges for protecting health information in a new era. BMC Med Ethics, 2021. 22(1): p. 122. Karim, M.R., et al., Explainable AI for Bioinformatics: Methods, Tools and Applications. Brief Bioinform, 2023. 24(5). Karim, M.R., et al., Explainable AI for Bioinformatics: Methods, Tools and Applications. Brief Bioinform, 2023. 24(5). Hou, W. and Z. Ji, Assessing GPT-4 for cell type annotation in single-cell RNA-seq analysis.bioRxiv, 2023. Hou, W. and Z. Ji, Assessing GPT-4 for cell type annotation in single-cell RNA-seq analysis.bioRxiv, 2023. Zhu, H., et al., MED: a new non-supervised gene prediction algorithm for bacterial and archaeal genomes. BMC Bioinformatics, 2007. 8: p. 97. Zhu, H., et al., MED: a new non-supervised gene prediction algorithm for bacterial and archaeal genomes. BMC Bioinformatics, 2007. 8: p. 97. Yin, H., et al. An Evaluation of Large Language Models in Bioinformatics Research. 2024. arXiv:2402.13714 DOI: 10.48550/arXiv.2402.13714. Yin, H., et al. An Evaluation of Large Language Models in Bioinformatics Research. 2024. arXiv:2402.13714 DOI: 10.48550/arXiv.2402.13714. Hou, W. and Z. Ji, GeneTuring tests GPT models in genomics. bioRxiv, 2023. Hou, W. and Z. Ji, GeneTuring tests GPT models in genomics. bioRxiv, 2023. Jin, Q., Y. Yang, Q. Chen, and Z. Lu, GeneGPT: Augmenting large language models with domain tools for improved access to biomedical information. Bioinformatics, 2024. Jin, Q., Y. Yang, Q. Chen, and Z. Lu, GeneGPT: Augmenting large language models with domain tools for improved access to biomedical information. Bioinformatics, 2024. Chen, Q. and C. Deng, Bioinfo-Bench: A Simple Benchmark Framework for LLM Bioinformatics Skills Evaluation. bioRxiv, 2023: p. 2023.10.18.563023. Chen, Q. and C. Deng, Bioinfo-Bench: A Simple Benchmark Framework for LLM Bioinformatics Skills Evaluation. bioRxiv, 2023: p. 2023.10.18.563023. Ahimaz, P., et al., Genetic counselors' utilization of ChatGPT in professional practice: A cross-sectional study. American Journal of Medical Genetics Part A, 2023. Ahimaz, P., et al., Genetic counselors' utilization of ChatGPT in professional practice: A cross-sectional study. American Journal of Medical Genetics Part A, 2023. Duong, D. and B.D. Solomon, Analysis of large-language model versus human performance for genetics questions. Eur J Hum Genet, 2023. Duong, D. and B.D. Solomon, Analysis of large-language model versus human performance for genetics questions. Eur J Hum Genet, 2023. Alkuraya, I.F., Is artificial intelligence getting too much credit in medical genetics? American Journal of Medical Genetics Part C-Seminars in Medical Genetics, 2023. 193(3). Alkuraya, I.F., Is artificial intelligence getting too much credit in medical genetics? American Journal of Medical Genetics Part C-Seminars in Medical Genetics, 2023. 193(3). Emmert-Streib, F., Can ChatGPT understand genetics? European Journal of Human Genetics, Emmert-Streib, F., Can ChatGPT understand genetics? European Journal of Human Genetics, Chen, Q., et al., An Extensive Benchmark Study on Biomedical Text Generation and Mining with ChatGPT. Bioinformatics, 2023. Chen, Q., et al., An Extensive Benchmark Study on Biomedical Text Generation and Mining with ChatGPT. Bioinformatics, 2023. Gu, Y., et al. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. 2020. arXiv:2007.15779 DOI: 10.48550/arXiv.2007.15779. Gu, Y., et al. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. 2020. arXiv:2007.15779 DOI: 10.48550/arXiv.2007.15779. Chen, Q., et al. Large language models in biomedical natural language processing: benchmarks, baselines, and recommendations. 2023. arXiv:2305.16326 DOI: 10.48550/arXiv.2305.16326. Chen, Q., et al. Large language models in biomedical natural language processing: benchmarks, baselines, and recommendations. 2023. arXiv:2305.16326 DOI: 10.48550/arXiv.2305.16326. Ateia, S. and U. Kruschwitz Is ChatGPT a Biomedical Expert? -- Exploring the Zero-Shot Performance of Current GPT Models in Biomedical Tasks. 2023. arXiv:2306.16108 DOI: 10.48550/arXiv.2306.16108. Ateia, S. and U. Kruschwitz Is ChatGPT a Biomedical Expert? -- Exploring the Zero-Shot Performance of Current GPT Models in Biomedical Tasks. 2023. arXiv:2306.16108 DOI: 10.48550/arXiv.2306.16108. Chen, S., et al., Evaluating the ChatGPT family of models for biomedical reasoning and classification. J Am Med Inform Assoc, 2024. Chen, S., et al., Evaluating the ChatGPT family of models for biomedical reasoning and classification. J Am Med Inform Assoc, 2024. Jahan, I., M.T.R. Laskar, C. Peng, and J.X. Huang, A comprehensive evaluation of large language models on benchmark biomedical text processing tasks. Computers in Biology and Medicine, 2024: p. 108189. Jahan, I., M.T.R. Laskar, C. Peng, and J.X. Huang, A comprehensive evaluation of large language models on benchmark biomedical text processing tasks. Computers in Biology and Medicine, 2024: p. 108189. Hou, Y., et al., From Answers to Insights: Unveiling the Strengths and Limitations of ChatGPT and Biomedical Knowledge Graphs. Res Sq, 2023. Hou, Y., et al., From Answers to Insights: Unveiling the Strengths and Limitations of ChatGPT and Biomedical Knowledge Graphs. Res Sq, 2023. Rizvi, R.F., et al., iDISK: the integrated DIetary Supplements Knowledge base. J Am Med Inform Assoc, 2020. 27(4): p. 539-548. Rizvi, R.F., et al., iDISK: the integrated DIetary Supplements Knowledge base. J Am Med Inform Assoc, 2020. 27(4): p. 539-548. Zhao, Q., et al., BioTreasury: a community-based repository enabling indexing and rating of bioinformatics tools. Sci China Life Sci, 2023. Zhao, Q., et al., BioTreasury: a community-based repository enabling indexing and rating of bioinformatics tools. Sci China Life Sci, 2023. Wu, X., et al., reguloGPT: Harnessing GPT for Knowledge Graph Construction of Molecular Regulatory Pathways. bioRxiv, 2024. Wu, X., et al., reguloGPT: Harnessing GPT for Knowledge Graph Construction of Molecular Regulatory Pathways. bioRxiv, 2024. Li, Y., et al. ChatPathway: Conversational Large Language Models for Biology Pathway Detection. 2023. Li, Y., et al. ChatPathway: Conversational Large Language Models for Biology Pathway Detection. 2023. Azam, M., et al., A Comprehensive Evaluation of Large Language Models in Mining Gene Interactions and Pathway Knowledge. bioRxiv, 2024: p. 2024.01.21.576542. Azam, M., et al., A Comprehensive Evaluation of Large Language Models in Mining Gene Interactions and Pathway Knowledge. bioRxiv, 2024: p. 2024.01.21.576542. Rehana, H., et al. Evaluation of GPT and BERT-based models on identifying protein-protein interactions in biomedical text. 2023. arXiv:2303.17728 DOI: 10.48550/arXiv.2303.17728. Rehana, H., et al. Evaluation of GPT and BERT-based models on identifying protein-protein interactions in biomedical text. 2023. arXiv:2303.17728 DOI: 10.48550/arXiv.2303.17728. Tiwari, K., et al., ChatGPT usage in the Reactome curation process. bioRxiv, 2023: p. 2023.11.08.566195. Tiwari, K., et al., ChatGPT usage in the Reactome curation process. bioRxiv, 2023: p. 2023.11.08.566195. Zhou, B., et al., EVLncRNAs 3.0: an updated comprehensive database for manually curated functional long non-coding RNAs validated by low-throughput experiments. Nucleic Acids Res, 2024. 52(D1): p. D98-D106. Zhou, B., et al., EVLncRNAs 3.0: an updated comprehensive database for manually curated functional long non-coding RNAs validated by low-throughput experiments. Nucleic Acids Res, 2024. 52(D1): p. D98-D106. Chen, X., et al., Computational screening of biomarkers and potential drugs for arthrofibrosis based on combination of sequencing and large nature language model. Journal of Orthopaedic Translation, 2024. 44: p. 102-113. Chen, X., et al., Computational screening of biomarkers and potential drugs for arthrofibrosis based on combination of sequencing and large nature language model. Journal of Orthopaedic Translation, 2024. 44: p. 102-113. Fo, K., et al., PlantConnectome: knowledge networks encompassing >100,000 plant article abstracts. bioRxiv, 2023: p. 2023.07.11.548541. Fo, K., et al., PlantConnectome: knowledge networks encompassing >100,000 plant article abstracts. bioRxiv, 2023: p. 2023.07.11.548541. Rawte, V., A. Sheth, and A. Das A Survey of Hallucination in Large Foundation Models. 2023. arXiv:2309.05922 DOI: 10.48550/arXiv.2309.05922. Rawte, V., A. Sheth, and A. Das A Survey of Hallucination in Large Foundation Models. 2023. arXiv:2309.05922 DOI: 10.48550/arXiv.2309.05922. Zhang, Y., et al. Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models. 2023. arXiv:2309.01219 DOI:10.48550/arXiv.2309.01219. Zhang, Y., et al. Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models. 2023. arXiv:2309.01219 DOI:10.48550/arXiv.2309.01219. Chen, Y., et al., Iterative Prompt Refinement for Mining Gene Relationships from ChatGPT. bioRxiv, 2023: p. 2023.12.23.573201. Chen, Y., et al., Iterative Prompt Refinement for Mining Gene Relationships from ChatGPT. bioRxiv, 2023: p. 2023.12.23.573201. Yao, S., et al., Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv, 2023. Yao, S., et al., Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv, 2023. Savage, N., Drug discovery companies are customizing ChatGPT: here's how. Nat Biotechnol, 41(5): p. 585-586. Savage, N., Drug discovery companies are customizing ChatGPT: here's how. Nat Biotechnol, 41(5): p. 585-586. Chakraborty, C., M. Bhattacharya, and S.S. Lee, Artificial intelligence enabled ChatGPT and large language models in drug target discovery, drug discovery, and development. Mol Ther Nucleic Acids, 2023. 33: p. 866-868. Chakraborty, C., M. Bhattacharya, and S.S. Lee, Artificial intelligence enabled ChatGPT and large language models in drug target discovery, drug discovery, and development. Mol Ther Nucleic Acids, 2023. 33: p. 866-868. Zhao, A. and Y. Wu, Future implications of ChatGPT in pharmaceutical industry: drug discovery and development. Front Pharmacol, 2023. 14: p. 1194216. Zhao, A. and Y. Wu, Future implications of ChatGPT in pharmaceutical industry: drug discovery and development. Front Pharmacol, 2023. 14: p. 1194216. Hu, G. and Z. Xie, The artificial intelligence pharma era after “Chat Generative Pre-trained Transformer”. Medical Review, 2023. 3(3): p. 198-199. Hu, G. and Z. Xie, The artificial intelligence pharma era after “Chat Generative Pre-trained Transformer”. Medical Review, 2023. 3(3): p. 198-199. Gao, Z., et al., Examining the Potential of ChatGPT on Biomedical Information Retrieval: FactChecking Drug-Disease Associations. Ann Biomed Eng, 2023. Gao, Z., et al., Examining the Potential of ChatGPT on Biomedical Information Retrieval: FactChecking Drug-Disease Associations. Ann Biomed Eng, 2023. Guo, T., et al. What can Large Language Models do in chemistry? A comprehensive benchmark on eight tasks. 2023. arXiv:2305.18365 DOI: 10.48550/arXiv.2305.18365. Guo, T., et al. What can Large Language Models do in chemistry? A comprehensive benchmark on eight tasks. 2023. arXiv:2305.18365 DOI: 10.48550/arXiv.2305.18365. Juhi, A., et al., The Capability of ChatGPT in Predicting and Explaining Common Drug-Drug Interactions. Cureus, 2023. 15(3): p. e36272. Juhi, A., et al., The Capability of ChatGPT in Predicting and Explaining Common Drug-Drug Interactions. Cureus, 2023. 15(3): p. e36272. Al-Ashwal, F.Y., et al., Evaluating the Sensitivity, Specificity, and Accuracy of ChatGPT-3.5, ChatGPT-4, Bing AI, and Bard Against Conventional Drug-Drug Interactions Clinical Tools. Drug Healthc Patient Saf, 2023. 15: p. 137-147. Al-Ashwal, F.Y., et al., Evaluating the Sensitivity, Specificity, and Accuracy of ChatGPT-3.5, ChatGPT-4, Bing AI, and Bard Against Conventional Drug-Drug Interactions Clinical Tools. Drug Healthc Patient Saf, 2023. 15: p. 137-147. Herrero-Zazo, M., I. Segura-Bedmar, P. Martinez, and T. Declerck, The DDI corpus: an annotated corpus with pharmacological substances and drug-drug interactions. J Biomed Inform, 2013. 46(5): p. 914-20. Herrero-Zazo, M., I. Segura-Bedmar, P. Martinez, and T. Declerck, The DDI corpus: an annotated corpus with pharmacological substances and drug-drug interactions. J Biomed Inform, 2013. 46(5): p. 914-20. Wang, Y.M., H.W. Shen, and T.J. Chen, Performance of ChatGPT on the pharmacist licensing examination in Taiwan. J Chin Med Assoc, 2023. 86(7): p. 653-658. Wang, Y.M., H.W. Shen, and T.J. Chen, Performance of ChatGPT on the pharmacist licensing examination in Taiwan. J Chin Med Assoc, 2023. 86(7): p. 653-658. Kunitsu, Y., The Potential of GPT-4 as a Support Tool for Pharmacists: Analytical Study Using the Japanese National Examination for Pharmacists. Jmir Medical Education, 2023. 9. Kunitsu, Y., The Potential of GPT-4 as a Support Tool for Pharmacists: Analytical Study Using the Japanese National Examination for Pharmacists. Jmir Medical Education, 2023. 9. Zong, H., et al., Performance of ChatGPT on Chinese National Medical Licensing Examinations: A Five-Year Examination Evaluation Study for Physicians, Pharmacists and Nurses. medRxiv, 2023: p. 2023.07.09.23292415. Zong, H., et al., Performance of ChatGPT on Chinese National Medical Licensing Examinations: A Five-Year Examination Evaluation Study for Physicians, Pharmacists and Nurses. medRxiv, 2023: p. 2023.07.09.23292415. Huang, X., et al., Evaluating the performance of ChatGPT in clinical pharmacy: A comparative study of ChatGPT and clinical pharmacists. Br J Clin Pharmacol, 2024. 90(1): p. 232-238. Huang, X., et al., Evaluating the performance of ChatGPT in clinical pharmacy: A comparative study of ChatGPT and clinical pharmacists. Br J Clin Pharmacol, 2024. 90(1): p. 232-238. Wang, R., H. Feng, and G.W. Wei, ChatGPT in Drug Discovery: A Case Study on Anticocaine Addiction Drug Development with Chatbots. J Chem Inf Model, 2023. 63(22): p. 7189-7209. Wang, R., H. Feng, and G.W. Wei, ChatGPT in Drug Discovery: A Case Study on Anticocaine Addiction Drug Development with Chatbots. J Chem Inf Model, 2023. 63(22): p. 7189-7209. Liang, Y., R. Zhang, L. Zhang, and P. Xie DrugChat: Towards Enabling ChatGPT-Like Capabilities on Drug Molecule Graphs. 2023. arXiv:2309.03907 DOI: 10.48550/arXiv.2309.03907. Liang, Y., R. Zhang, L. Zhang, and P. Xie DrugChat: Towards Enabling ChatGPT-Like Capabilities on Drug Molecule Graphs. 2023. arXiv:2309.03907 DOI: 10.48550/arXiv.2309.03907. Liu, S., et al. ChatGPT-powered Conversational Drug Editing Using Retrieval and Domain Feedback. 2023. arXiv:2305.18090 DOI: 10.48550/arXiv.2305.18090. Liu, S., et al. ChatGPT-powered Conversational Drug Editing Using Retrieval and Domain Feedback. 2023. arXiv:2305.18090 DOI: 10.48550/arXiv.2305.18090. Ye, G., et al. DrugAssist: A Large Language Model for Molecule Optimization. 2023. arXiv:2401.10334 DOI: 10.48550/arXiv.2401.10334. Ye, G., et al. DrugAssist: A Large Language Model for Molecule Optimization. 2023. arXiv:2401.10334 DOI: 10.48550/arXiv.2401.10334. Dong, Q., et al. A Survey on In-context Learning. 2022. arXiv:2301.00234 DOI:10.48550/arXiv.2301.00234. Dong, Q., et al. A Survey on In-context Learning. 2022. arXiv:2301.00234 DOI:10.48550/arXiv.2301.00234. Li, J., et al. Empowering Molecule Discovery for Molecule-Caption Translation with Large Language Models: A ChatGPT Perspective. 2023. arXiv:2306.06615 DOI: 10.48550/arXiv.2306.06615. Li, J., et al. Empowering Molecule Discovery for Molecule-Caption Translation with Large Language Models: A ChatGPT Perspective. 2023. arXiv:2306.06615 DOI: 10.48550/arXiv.2306.06615. Jablonka, K.M., P. Schwaller, A. Ortega-Guerrero, and B. Smit, Leveraging large language models for predictive chemistry. Nature Machine Intelligence, 2024. Jablonka, K.M., P. Schwaller, A. Ortega-Guerrero, and B. Smit, Leveraging large language models for predictive chemistry. Nature Machine Intelligence, 2024. Cai, X., et al., Comprehensive evaluation of molecule property prediction with ChatGPT. Methods, 2024. 222: p. 133-141. Cai, X., et al., Comprehensive evaluation of molecule property prediction with ChatGPT. Methods, 2024. 222: p. 133-141. Caldas Ramos, M., S.S. Michtavy, M.D. Porosoff, and A.D. White Bayesian Optimization of Catalysts With In-context Learning. 2023. arXiv:2304.05341 DOI: 10.48550/arXiv.2304.05341. Caldas Ramos, M., S.S. Michtavy, M.D. Porosoff, and A.D. White Bayesian Optimization of Catalysts With In-context Learning. 2023. arXiv:2304.05341 DOI: 10.48550/arXiv.2304.05341. Zeng, Z., et al. Interactive Molecular Discovery with Natural Language. 2023. arXiv:2306.11976 DOI: 10.48550/arXiv.2306.11976. Zeng, Z., et al. Interactive Molecular Discovery with Natural Language. 2023. arXiv:2306.11976 DOI: 10.48550/arXiv.2306.11976. Raffel, C., et al., Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research, 2020. 21. Raffel, C., et al., Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research, 2020. 21. Hu, H., et al., A Generative Drug–Drug Interaction Triplets Extraction Framework Based on Large Language Models. Proceedings of the Association for Information Science and Technology, 2023. 60(1): p. 980-982. Hu, H., et al., A Generative Drug–Drug Interaction Triplets Extraction Framework Based on Large Language Models. Proceedings of the Association for Information Science and Technology, 2023. 60(1): p. 980-982. Wei, J., et al. Finetuned Language Models Are Zero-Shot Learners. 2021. arXiv:2109.01652 DOI: 10.48550/arXiv.2109.01652. Wei, J., et al. Finetuned Language Models Are Zero-Shot Learners. 2021. arXiv:2109.01652 DOI: 10.48550/arXiv.2109.01652. Fang, Y., et al. Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models. 2023. arXiv:2306.08018 DOI: 10.48550/arXiv.2306.08018. Fang, Y., et al. Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models. 2023. arXiv:2306.08018 DOI: 10.48550/arXiv.2306.08018. Zhao, Z., et al. ChemDFM: Dialogue Foundation Model for Chemistry. 2024. arXiv:2401.14818 DOI: 10.48550/arXiv.2401.14818. Zhao, Z., et al. ChemDFM: Dialogue Foundation Model for Chemistry. 2024. arXiv:2401.14818 DOI: 10.48550/arXiv.2401.14818. Cao, H., et al. InstructMol: Multi-Modal Integration for Building a Versatile and Reliable Molecular Assistant in Drug Discovery. 2023. arXiv:2311.16208 DOI: 10.48550/arXiv.2311.16208. Cao, H., et al. InstructMol: Multi-Modal Integration for Building a Versatile and Reliable Molecular Assistant in Drug Discovery. 2023. arXiv:2311.16208 DOI: 10.48550/arXiv.2311.16208. Acosta, J.N., G.J. Falcone, P. Rajpurkar, and E.J. Topol, Multimodal biomedical AI. Nature Medicine, 2022. 28(9): p. 1773-1784. Acosta, J.N., G.J. Falcone, P. Rajpurkar, and E.J. Topol, Multimodal biomedical AI. Nature Medicine, 2022. 28(9): p. 1773-1784. Truhn, D., et al., A pilot study on the efficacy of GPT-4 in providing orthopedic treatment recommendations from MRI reports. Scientific Reports, 2023. 13(1). Truhn, D., et al., A pilot study on the efficacy of GPT-4 in providing orthopedic treatment recommendations from MRI reports. Scientific Reports, 2023. 13(1). Liu, Z., et al. Holistic Evaluation of GPT-4V for Biomedical Imaging. 2023. arXiv:2312.05256 DOI: 10.48550/arXiv.2312.05256. Liu, Z., et al. Holistic Evaluation of GPT-4V for Biomedical Imaging. 2023. arXiv:2312.05256 DOI: 10.48550/arXiv.2312.05256. Wu, C., et al. Can GPT-4V(ision) Serve Medical Applications? Case Studies on GPT-4V for Multimodal Medical Diagnosis. 2023. arXiv:2310.09909 DOI: 10.48550/arXiv.2310.09909. Wu, C., et al. Can GPT-4V(ision) Serve Medical Applications? Case Studies on GPT-4V for Multimodal Medical Diagnosis. 2023. arXiv:2310.09909 DOI: 10.48550/arXiv.2310.09909. Yan, Z., et al. Multimodal ChatGPT for Medical Applications: an Experimental Study of GPT-4V. 2023. arXiv:2310.19061 DOI: 10.48550/arXiv.2310.19061. Yan, Z., et al. Multimodal ChatGPT for Medical Applications: an Experimental Study of GPT-4V. 2023. arXiv:2310.19061 DOI: 10.48550/arXiv.2310.19061. Buckley, T., J.A. Diao, A. Rodman, and A.K. Manrai Accuracy of a Vision-Language Model on Challenging Medical Cases. 2023. arXiv:2311.05591 DOI: 10.48550/arXiv.2311.05591. Buckley, T., J.A. Diao, A. Rodman, and A.K. Manrai Accuracy of a Vision-Language Model on Challenging Medical Cases. 2023. arXiv:2311.05591 DOI: 10.48550/arXiv.2311.05591. Yang, Z., et al., Performance of Multimodal GPT-4V on USMLE with Image: Potential for Imaging Diagnostic Support with Explanations. medRxiv, 2023: p. 2023.10.26.23297629. Yang, Z., et al., Performance of Multimodal GPT-4V on USMLE with Image: Potential for Imaging Diagnostic Support with Explanations. medRxiv, 2023: p. 2023.10.26.23297629. Li, Y., et al., A Comprehensive Study of GPT-4V’s Multimodal Capabilities in Medical Imaging. medRxiv, 2023: p. 2023.11.03.23298067. Li, Y., et al., A Comprehensive Study of GPT-4V’s Multimodal Capabilities in Medical Imaging. medRxiv, 2023: p. 2023.11.03.23298067. Hou, W. and Z. Ji, GPT-4V exhibits human-like performance in biomedical image classification. bioRxiv, 2024. Hou, W. and Z. Ji, GPT-4V exhibits human-like performance in biomedical image classification. bioRxiv, 2024. Wang, J., et al., Scientific Figures Interpreted by ChatGPT: Strengths in Plot Recognition and Limits in Color Perception. npj Precision Oncology, 2024. in press. Wang, J., et al., Scientific Figures Interpreted by ChatGPT: Strengths in Plot Recognition and Limits in Color Perception. npj Precision Oncology, 2024. in press. OpenAI, GPT-4V(ision) System Card. 2023, OpenAI. p. 1-18. OpenAI, GPT-4V(ision) System Card. 2023, OpenAI. p. 1-18. Nickerson, R.S., Confirmation Bias: A Ubiquitous Phenomenon in Many Guises. Review of General Psychology, 1998. 2(2): p. 175-220. Nickerson, R.S., Confirmation Bias: A Ubiquitous Phenomenon in Many Guises. Review of General Psychology, 1998. 2(2): p. 175-220. Jin, Q., et al. Hidden Flaws Behind Expert-Level Accuracy of GPT-4 Vision in Medicine. 2024. arXiv:2401.08396 DOI:10.48550/arXiv.2401.08396. Jin, Q., et al. Hidden Flaws Behind Expert-Level Accuracy of GPT-4 Vision in Medicine. 2024. arXiv:2401.08396 DOI:10.48550/arXiv.2401.08396. Wang, J., et al. Review of Large Vision Models and Visual Prompt Engineering. 2023. arXiv:2307.00855 DOI: 10.48550/arXiv.2307.00855. Wang, J., et al. Review of Large Vision Models and Visual Prompt Engineering. 2023. arXiv:2307.00855 DOI: 10.48550/arXiv.2307.00855. Yang, Z., et al., The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision). arXiv, 2023. Yang, Z., et al., The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision). arXiv, 2023. Li, Z., et al. VRPTEST: Evaluating Visual Referring Prompting in Large Multimodal Models. 2023. arXiv:2312.04087 DOI: 10.48550/arXiv.2312.04087. Li, Z., et al. VRPTEST: Evaluating Visual Referring Prompting in Large Multimodal Models. 2023. arXiv:2312.04087 DOI: 10.48550/arXiv.2312.04087. Li, J., et al., Next-Generation Analytics for Omics Data. Cancer Cell, 2021. 39(1): p. 3-6. Li, J., et al., Next-Generation Analytics for Omics Data. Cancer Cell, 2021. 39(1): p. 3-6. Xie, M., et al., RiboChat: a chat-style web interface for analysis and annotation of ribosome profiling data. Brief Bioinform, 2022. 23(2). Xie, M., et al., RiboChat: a chat-style web interface for analysis and annotation of ribosome profiling data. Brief Bioinform, 2022. 23(2). Merow, C., J.M. Serra-Diaz, B.J. Enquist, and A.M. Wilson, AI chatbots can boost scientific coding. Nature Ecology & Evolution, 2023. Merow, C., J.M. Serra-Diaz, B.J. Enquist, and A.M. Wilson, AI chatbots can boost scientific coding. Nature Ecology & Evolution, 2023. Zhou, J., et al., An AI Agent for Fully Automated Multi-omic Analyses. bioRxiv, 2024: p. 2023.09.08.556814. Zhou, J., et al., An AI Agent for Fully Automated Multi-omic Analyses. bioRxiv, 2024: p. 2023.09.08.556814. Jansen, J.A., A. Manukyan, N.A. Khoury, and A. Akalin, Leveraging large language models for data analysis automation. bioRxiv, 2023: p. 2023.12.11.571140. Jansen, J.A., A. Manukyan, N.A. Khoury, and A. Akalin, Leveraging large language models for data analysis automation. bioRxiv, 2023: p. 2023.12.11.571140. Dong, Z., V. Zhong, and Y.Y. Lu, BioMANIA: Simplifying bioinformatics data analysis through conversation. bioRxiv, 2023: p. 2023.10.29.564479. Dong, Z., V. Zhong, and Y.Y. Lu, BioMANIA: Simplifying bioinformatics data analysis through conversation. bioRxiv, 2023: p. 2023.10.29.564479. Liu, A., X. Hu, L. Wen, and P.S. Yu A comprehensive evaluation of ChatGPT's zero-shot Text-toSQL capability. 2023. arXiv:2303.13547 DOI: 10.48550/arXiv.2303.13547. Liu, A., X. Hu, L. Wen, and P.S. Yu A comprehensive evaluation of ChatGPT's zero-shot Text-toSQL capability. 2023. arXiv:2303.13547 DOI: 10.48550/arXiv.2303.13547. Sima, A.-C. and T.M. de Farias. On the Potential of Artificial Intelligence Chatbots for Data Exploration of Federated Bioinformatics Knowledge Graphs. in SeWebMeDa’23: 6th Workshop on Semantic Web Solutions for Large-Scale Biomedical Data Analytics. 2023. Hersonissos, Greece: CEUR-WS.org. Sima, A.-C. and T.M. de Farias. On the Potential of Artificial Intelligence Chatbots for Data Exploration of Federated Bioinformatics Knowledge Graphs. in SeWebMeDa’23: 6th Workshop on Semantic Web Solutions for Large-Scale Biomedical Data Analytics. 2023. Hersonissos, Greece: CEUR-WS.org . CEUR-WS.org Rangel, J.C., T.M. de Farias, A.C. Sima, and N. Kobayashi. SPARQL Generation: an analysis on fine-tuning OpenLLaMA for Question Answering over a Life Science Knowledge Graph. in WAT4HCLS 2024: 15th International Semantic Web Applications and Tools for Health Care and Life Sciences Conference. 2024. Leiden, Netherlands: In press. Rangel, J.C., T.M. de Farias, A.C. Sima, and N. Kobayashi. SPARQL Generation: an analysis on fine-tuning OpenLLaMA for Question Answering over a Life Science Knowledge Graph. in WAT4HCLS 2024: 15th International Semantic Web Applications and Tools for Health Care and Life Sciences Conference. 2024. Leiden, Netherlands: In press. Chen, C. and T. Stadler GenSpectrum Chat: Data Exploration in Public Health Using Large Language Models. 2023. arXiv:2305.13821 DOI: 10.48550/arXiv.2305.13821. Chen, C. and T. Stadler GenSpectrum Chat: Data Exploration in Public Health Using Large Language Models. 2023. arXiv:2305.13821 DOI: 10.48550/arXiv.2305.13821. Wang, L., X.J. Ge, L. Liu, and G.Q. Hu, Code Interpreter for Bioinformatics: Are We There Yet? Annals of Biomedical Engineering, 2023. Wang, L., X.J. Ge, L. Liu, and G.Q. Hu, Code Interpreter for Bioinformatics: Are We There Yet? Annals of Biomedical Engineering, 2023. Tang, X., et al., BioCoder: A Benchmark for Bioinformatics Code Generation with Contextual Pragmatic Knowledge. arXiv, 2023. Tang, X., et al., BioCoder: A Benchmark for Bioinformatics Code Generation with Contextual Pragmatic Knowledge. arXiv, 2023. Sarwal, V., et al., BioLLMBench: A Comprehensive Benchmarking of Large Language Models in Bioinformatics. bioRxiv, 2023: p. 2023.12.19.572483. Sarwal, V., et al., BioLLMBench: A Comprehensive Benchmarking of Large Language Models in Bioinformatics. bioRxiv, 2023: p. 2023.12.19.572483. Lubiana, T., et al., Ten quick tips for harnessing the power of ChatGPT in computational biology. PLoS Comput Biol, 2023. 19(8): p. e1011319. Lubiana, T., et al., Ten quick tips for harnessing the power of ChatGPT in computational biology. PLoS Comput Biol, 2023. 19(8): p. e1011319. Chen, M., et al. Evaluating Large Language Models Trained on Code. 2021. arXiv:2107.03374 DOI: 10.48550/arXiv.2107.03374. Chen, M., et al. Evaluating Large Language Models Trained on Code. 2021. arXiv:2107.03374 DOI: 10.48550/arXiv.2107.03374. Lehtinen, T., L. Haaranen, and J. Leinonen. Automated Questionnaires About Students’ JavaScript Programs: Towards Gauging Novice Programming Processes. in ACE '23: Proceedings of the 25th Australasian Computing Education Conference. 2023. New York, NY, USA: Association for Computing Machiner. Lehtinen, T., L. Haaranen, and J. Leinonen. Automated Questionnaires About Students’ JavaScript Programs: Towards Gauging Novice Programming Processes. in ACE '23: Proceedings of the 25th Australasian Computing Education Conference. 2023. New York, NY, USA: Association for Computing Machiner. Denny, P., et al. Promptly: Using Prompt Problems to Teach Learners How to Effectively Utilize AI Code Generators. 2023. arXiv:2307.16364 DOI: 10.48550/arXiv.2307.16364. Denny, P., et al. Promptly: Using Prompt Problems to Teach Learners How to Effectively Utilize AI Code Generators. 2023. arXiv:2307.16364 DOI: 10.48550/arXiv.2307.16364. Soman, K., et al. Biomedical knowledge graph-enhanced prompt generation for large language models. 2023. arXiv:2311.17330 DOI: 10.48550/arXiv.2311.17330. Soman, K., et al. Biomedical knowledge graph-enhanced prompt generation for large language models. 2023. arXiv:2311.17330 DOI: 10.48550/arXiv.2311.17330. Chen, L., M. Zaharia, and J. Zou How is ChatGPT's behavior changing over time? 2023. arXiv:2307.09009 DOI: 10.48550/arXiv.2307.09009. Chen, L., M. Zaharia, and J. Zou How is ChatGPT's behavior changing over time? 2023. arXiv:2307.09009 DOI: 10.48550/arXiv.2307.09009. Wang, G., et al. ClinicalGPT: Large Language Models Finetuned with Diverse Medical Data and Comprehensive Evaluation. 2023. arXiv:2306.09968 DOI: 10.48550/arXiv.2306.09968. Wang, G., et al. ClinicalGPT: Large Language Models Finetuned with Diverse Medical Data and Comprehensive Evaluation. 2023. arXiv:2306.09968 DOI: 10.48550/arXiv.2306.09968. Peng, C., et al. A Study of Generative Large Language Model for Medical Research and Healthcare. 2023. arXiv:2305.13523 DOI: 10.48550/arXiv.2305.13523. Peng, C., et al. A Study of Generative Large Language Model for Medical Research and Healthcare. 2023. arXiv:2305.13523 DOI: 10.48550/arXiv.2305.13523. Lai, T., et al. Psy-LLM: Scaling up Global Mental Health Psychological Services with AI-based Large Language Models. 2023. arXiv:2307.11991 DOI: 10.48550/arXiv.2307.11991. Lai, T., et al. Psy-LLM: Scaling up Global Mental Health Psychological Services with AI-based Large Language Models. 2023. arXiv:2307.11991 DOI: 10.48550/arXiv.2307.11991. Liu, J.M., et al. ChatCounselor: A Large Language Models for Mental Health Support. 2023. arXiv:2309.15461 DOI: 10.48550/arXiv.2309.15461. Liu, J.M., et al. ChatCounselor: A Large Language Models for Mental Health Support. 2023. arXiv:2309.15461 DOI: 10.48550/arXiv.2309.15461. Han, T., et al. MedAlpaca -- An Open-Source Collection of Medical Conversational AI Models and Training Data. 2023. arXiv:2304.08247 DOI: 10.48550/arXiv.2304.08247. Han, T., et al. MedAlpaca -- An Open-Source Collection of Medical Conversational AI Models and Training Data. 2023. arXiv:2304.08247 DOI: 10.48550/arXiv.2304.08247. Zhang, S., et al., Applications of transformer-based language models in bioinformatics: a survey. Bioinform Adv, 2023. 3(1): p. vbad001. Zhang, S., et al., Applications of transformer-based language models in bioinformatics: a survey. Bioinform Adv, 2023. 3(1): p. vbad001. Qiu, J.N., et al., Large AI Models in Health Informatics: Applications, Challenges, and the Future. Ieee Journal of Biomedical and Health Informatics, 2023. 27(12): p. 6074-6087. Qiu, J.N., et al., Large AI Models in Health Informatics: Applications, Challenges, and the Future. Ieee Journal of Biomedical and Health Informatics, 2023. 27(12): p. 6074-6087. This paper is available on arxiv under CC BY 4.0 DEED license. This paper is available on arxiv under CC BY 4.0 DEED license. available on arxiv