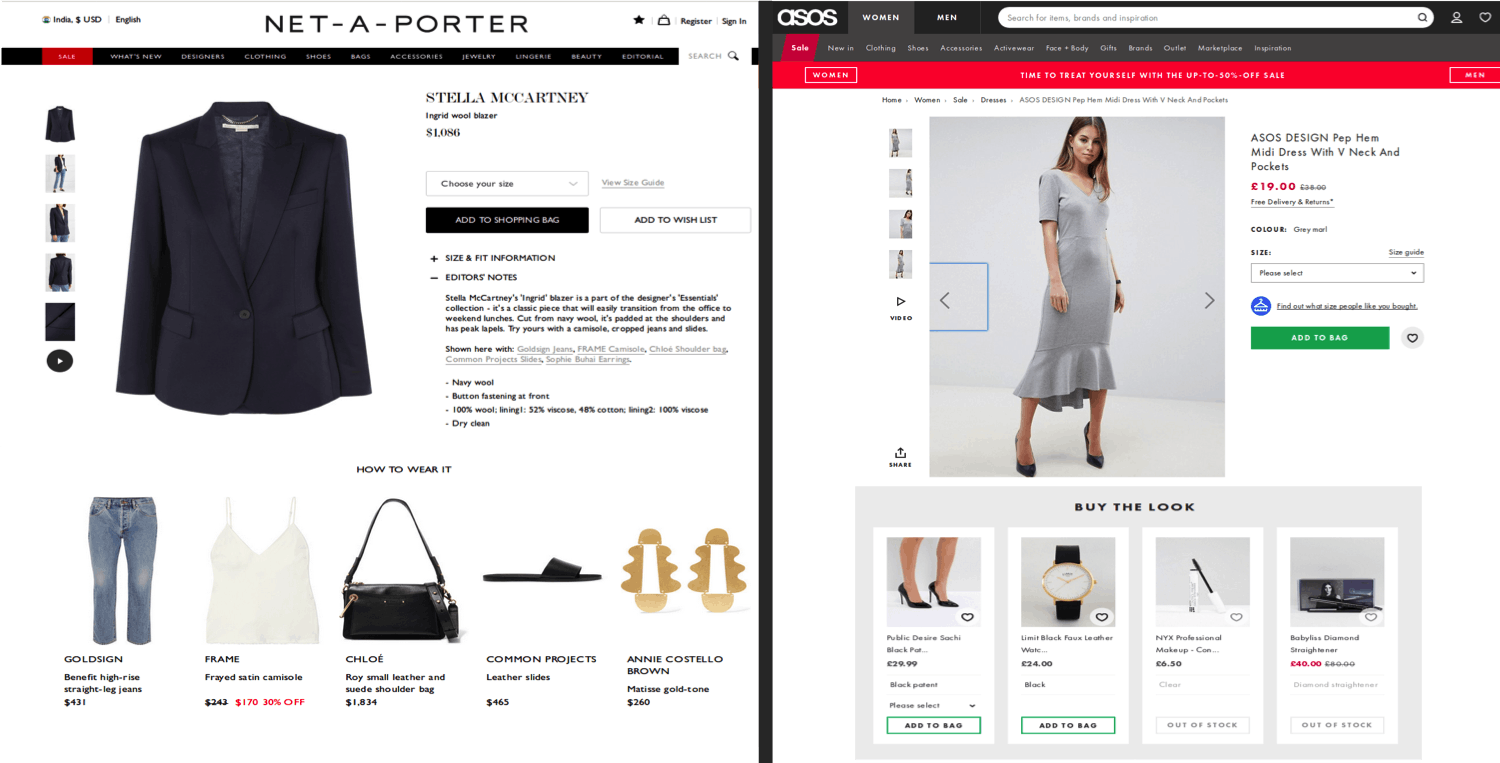
VogueNet trained on 5 Million Fashion Ensembles Problem What trousers should i wear this shirt with ? What bag goes well with this dress and these boots?This is a sort of question that would require a brain. fashion The world’s biggest fashion etailers ( SOS & ) show this as the only recommendation on their fashion product page.(How to wear this/Buy the look) A NetAPorter Lets see if we can make an ensemble recommendation engine using Deep Learning Vector Image Representation Standard way to find a vector image representation would be fine tune a pre-trained CNN (Inception Model) with fashion tags in a multi-label training environment. If we can assemble deep tags like neck types and skirt lengths etc, we can create a CNN based tag classification engine and use the fully connected last layer as the image representation.That representation can be used via transfer learning into multiple problems like similarity recommendations. The problem with such representations is that they contain only the visual cues on the image, i.e that all round neck t-shirts will be closer to each other in that vector space.This does not capture syntactic information or information based on things that co-occur. It does not capture the intrinsic relationship between a white shirt and denim jeans. Word Embeddings A word embedding is a learned representation for text where words that have the same meaning have a similar representation.It is a dense representation of a word in a vocabulary. Almost all state of the art advances in NLP use the concept of word embeddings.They can be trained using multiple methods.CBOW and Skip gram models are very common.[ eadMore R ] The most interesting property about word embeddings is that the word vectors capture many linguistic regularities, for example vector operations results in a vector that is very close to , and is close to [ ] vector(‘Paris’) — vector(‘France’) + vector(‘Italy’) vector(‘Rome’) vector(‘king’) — vector(‘man’) + vector(‘woman’) vector(‘queen’) ReadMore Word embeddings learn information in the language vector space. contextual and syntactic Fashion Embeddings Inspired by word embeddings i trained Fashion Embeddings: Dense Representations of fashion images which contain visual + relational(styling) information Fashion Embeddings VOGUENET A CNN+CBOW+Triplet Loss model that captures both visual and relational information Data Required You need data in form of sets where each set contains an ensemble of clothes/accessories that can be worn together. Polyvore.com and Fashupp.com used to be fashion portals which allowed users to create fashion ensembles and publish them.Polyvore.com and Fashupp.com do not exist now. I am the co-founder of Fashupp.com. I was able to collect such ensembles. ~5 million Multi-label Tag Data in the fashion domain Example of ensembles.For each ensemble i have a set individual product images. Alternatively you can run object detection on instagram fashion images to detect and segment fashion items that are worn together to get trending ensembles. Preprocessing Model for drawing bounding boxes on fashion objects in a image. Used the object detection api of tensorflow and fine-tuned an SSD model on fashion data. [ ] Fashion Object Detection Model (FODM): ReadMore for transfer : Train a multi label prediction model for fashion images.Use Last layer as representation.[ ] Pre-trained Fashion Model (PFM) learning ReadMore ) : Create a visual color histogram of Image Color Representation (CR ( ): Using dense representation from and color vector from duplicates can be found and replaced by putting a threshold on the cosine distance between dense and color representations of images respectively. Duplicate Removal DR PFM CR , Training Method for training embeddings : The CBOW model learns the embedding by predicting the current word based on its context. [ ] CBOW ReadMore : A hierarchical quantisation algorithm that produces codes of configurable length for data points. These codes are efficient representations of the original vector.Used to create fast search indexes for approximate[ ] Product Quantization (PQ) ReadMore ): The goal of the triplet loss with online learning is Triplet Loss (TL Two examples with the same label have their embeddings close together in the embedding space.Two examples with different labels have their embeddings far away. [ ] ReadMore Evaluation Collected around 1000 ensembles from ASOS which were created by their stylists as recommendations on their product pages. A Bucket is a category of fashion items.e.g Shirts,Shoes,Dresses. Create PQ Index for entire catalog per bucket.Pick an image(A) from a evaluation ensemble. Ea=VogueNet(A) Eb,B=IndexSearch(Ea) in BucketBIndex Ec,C=IndexSearch(VogueNet(Ea,Eb)) in BucketCIndex Ensemble = {A,B,C} Calculate Top10 precision for each search assuming ground truth from ASOS ensemble I feel there is a lot of scope for work on this and i would love to collaborate with people/startups working on such products. future I am available on LinkedIn Bibliography: https://omoindrot.github.io/triplet-loss https://github.com/yahoo/lopq http://ruder.io/word-embeddings-1/ https://www.tensorflow.org/tutorials/image_retraining https://github.com/tensorflow/models/tree/master/research/object_detection https://code.google.com/archive/p/word2vec/ More where this came from This story is published in , where thousands come every day to learn about the people & ideas shaping the products we love. Noteworthy Follow our publication to see more stories featured by the team. Journal