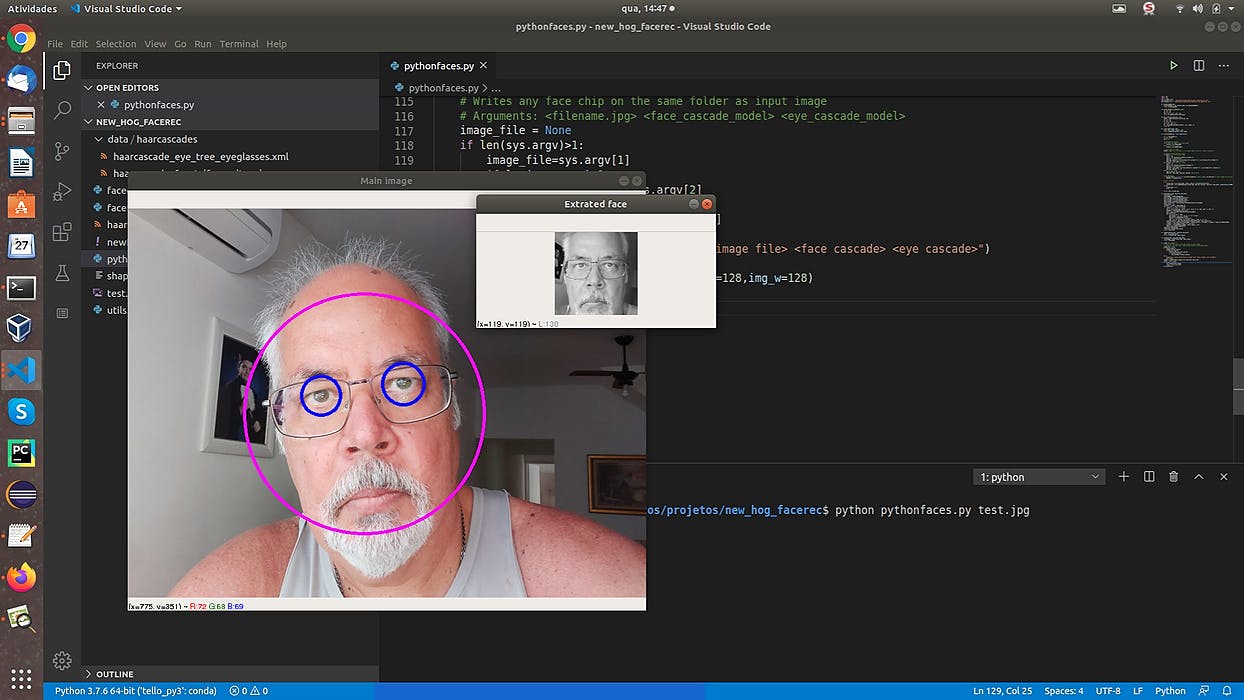
527 reads
Do Not Refactor Code That is Not Yet Working: Beautiful Code is Working Code
by byCleuton Sampaio@cleuton-sampaio
byCleuton Sampaio@cleuton-sampaio
Founder: "pythondrops.com". Full-stack dev/ AI Engineer/ Professional Writer/ M.Sc. Rio de Janeiro
April 10th, 2021






Founder: "pythondrops.com". Full-stack dev/ AI Engineer/ Professional Writer/ M.Sc. Rio de Janeiro


Founder: "pythondrops.com". Full-stack dev/ AI Engineer/ Professional Writer/ M.Sc. Rio de Janeiro
About Author

Founder: "pythondrops.com". Full-stack dev/ AI Engineer/ Professional Writer/ M.Sc. Rio de Janeiro
Comments